 系统中的latency是如何产生的
系统中的latency是如何产生的
在当今数字时代,手机已成为人们日常生活中不可或缺,多任务处理和实时响应对于用户体验越来越重要,抢占(preemption)机制在提升系统性能和用户体验方面发挥了至关重要的作用。内核抢占机制使得系统能够有效地管理多任务处理,确保系统对用户操作的快速响应,并在资源紧张的情况下仍能保持稳定和流畅的运行。
本篇文档旨在详细探讨Linux内核中的抢占机制,涵盖其基本概念、实现细节、性能影响以及相关的调试方法。通过对抢占机制的深入解析,我们希望能够帮助读者更好地理解和优化Linux系统的性能,并在实际工作应用这些知识。
为了使内容组织更清晰,本文档将使用Linux6.1内核,按照以下结构展开:
1.基本概念:首先讲解系统中的latency是如何产生的,为什么会产生
2.内核抢占的实现机制:从latency的角度说明了为什么需要抢占,什么是抢占,内核的抢占模型是怎么样的,内核中抢占点的设置、抢占计数的机制,以及如何在内核代码中控制抢占
3.Linux内核中的抢占实现:什么是内核抢占和实现方式,包括在什么情况下会发生抢占以及抢占的触发条件
4.实例分析:通过实际案例中一个高优先级的线程长时间抢占不到资源,来看如何定位类似问题
1. latency in linux
内核抢占允许高优先级任务中断正在执行的低优先级任务,从而减少调度延迟,提高系统响应性,那么我们就需要知道对于Linux内核中有哪些因素会导致响应不及时。首先,我们来看看典型应用场景如下:
一个硬件中断发生,并通过唤醒一个更高优先级的任务,一段时间后,高优先级的任务才得以执行,那么latency是实时响应关注的重点。
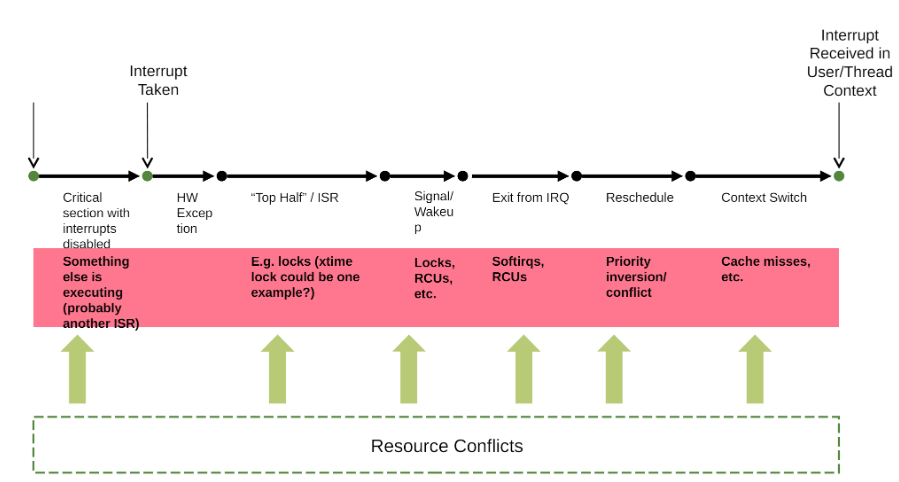
接下来细化该过程,初始状态时,进程处于睡眠等待,中断发生,到唤醒这个进程,等待选核选到这个任务,最后发生上下文切换,直到该进程运行,这个时间经历了以下几个完整的完成,这个统称为一次Scheduling latency。
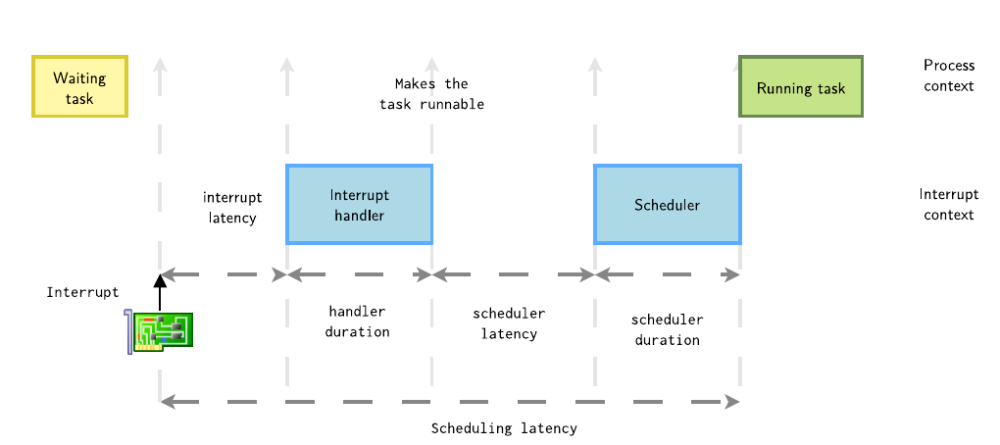
这一次的内核调度延迟 = 中断延迟(interrupt latency) + 处理程序持续时间(handler duration) + 调度程序延迟(scheduler latency) + 调度程序持续时间(scheduler duration),每一个过程都会影响这个高优先级任务的实时响应。
1.1 中断延迟
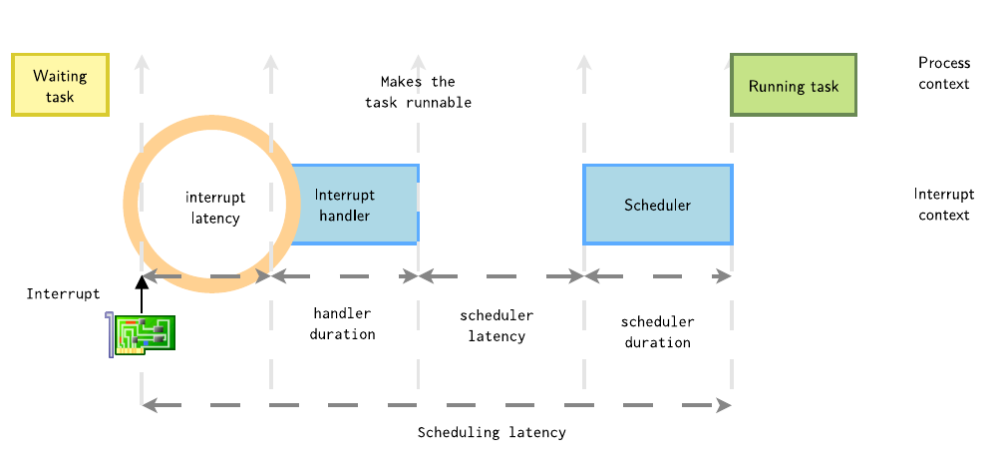
在T0时刻,外设中断发生,从中断发生到linux内核响应这个中断,之间有一个延时,称为中断延时,中断延迟的来源主要有以下原因:
1. 内核中大量使用了并发预防机制之一就是自旋锁,并且这个是一个common的接口供所有的模块使用,所以主要的来源就是中断在内核中被disable,如spinlock_irq()和spinlock_irq_irqsave(),此时当中断发生时候,内核处于关中断状态。
2. 中断控制器的调度延迟,现代的中断控制器支持中断优先级调度,当多个中断同时发生时,内核会通过比较中断的优先级来决定处理的顺序。较高优先级的中断会被优先处理,以保证对紧急事件的及时响应。因此,它可能会被高优先级中断
3. 中断处理会切换模式,保存寄存器状态等,这个时间很短
4. Shared Interrupt Line:当多个设备共享同一个中断时,中断控制器需要识别和区分不同的中断源,这个能有效地减少系统中断线的数量,节省硬件成本。然而,它也带来了一些潜在的问题,其中之一就是中断延迟的增加
1.2 中断处理程序持续时间
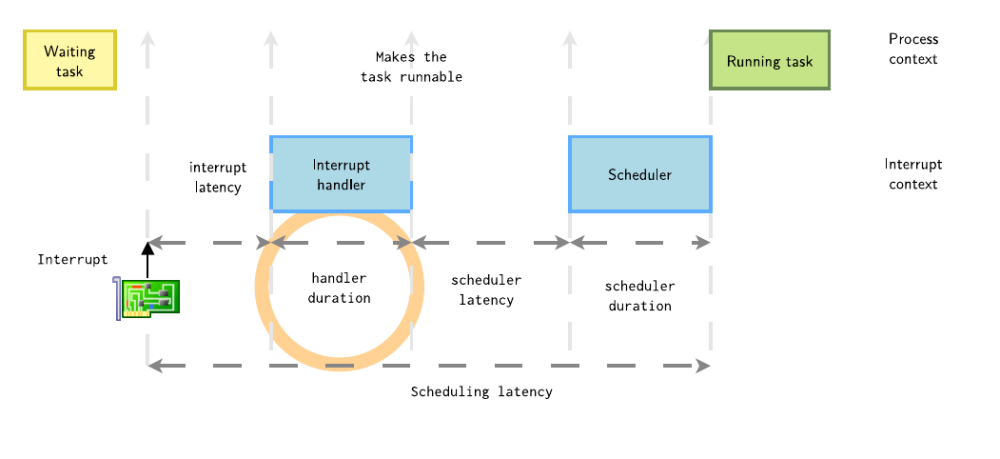
在T1时刻,CPU响应了这个中断,在Linux内核的中断处理分为上半部和下半部
1. 上半部分,它在禁用中断的情况下运行,并且应该尽快完成
2. 由上半部分调度的下半部分,在所有待处理的上半部分完成执行后开始,下半部分是开中断情况下执行,可能被其他中断打断
如下图,在处理完中断A上部分后,其他外设中断发生,CPU转而处理其他中断,这样延迟处理中断A下半部,我们把开始响应中断到这个处理的时间称为中断处理延迟,其处理的整个过程如下图所示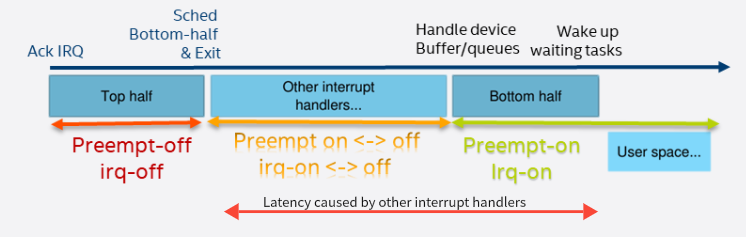
对于前面两个过程,我们在编写外设驱动的时候,要特别注意,里面设计大量的关中断和关抢占的过程,特别我们在一些自旋锁以及变体的接口,使用不当会导致响应不及时,例如中断响应不及时,高优先级任务迟迟得不到调度,给用户的直接感受就是卡顿。
1.3 调度延迟
在T2时刻,中断处理完后,唤醒了进程。从唤醒进程到进程被调度器选中的这段延时称为调度延时。
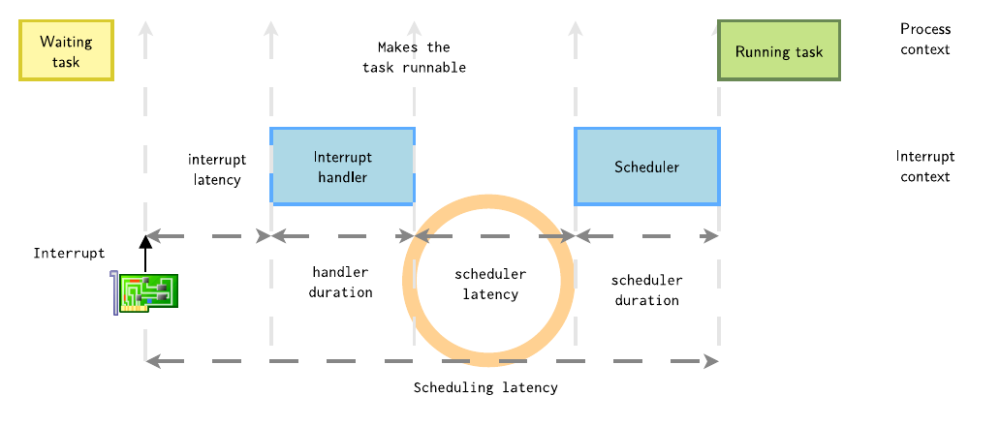
其产生调度延时的主要原因如下:
调度器选中进程A的时间也是不确定的,可能就绪队列中有比进程A优先级更高的进程
对于这个,就需要了解抢占,尽快的通过抢占来完成任务的切换工作。对于Linux内核是一个支持抢占式操作系统,当一个任务运行在用户空间并被中断打断时,如果中断处理程序唤醒另外一个任务,我们从中断处理返回后可以立即调度该任务。对于不同内核支持不同的抢占方式,处理方式也会不同,这个后面会详细介绍,这里只是作为一个引子,目前存在以下情况会影响调度延迟
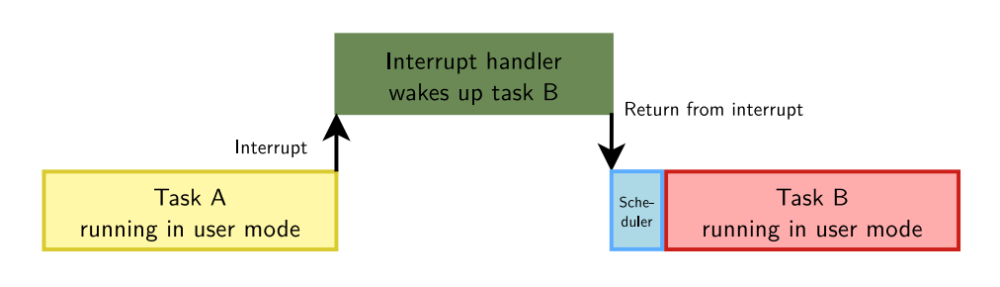
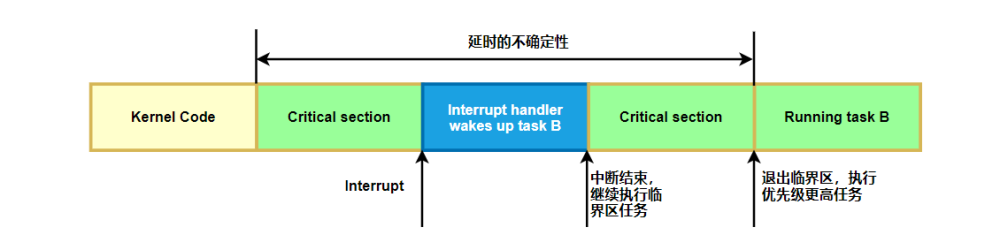
当中断发生时,linux内核正在自旋锁临界区里执行,这样,中断完成后,不能马上抢占调度,必须等待linux内核执行完自旋锁临界区才能抢占调度,这也会导致延迟的增加,并且很难被发现如下图所示
1.4 调度持续时间
在T3时刻,调度器选中了进程A,还需要进行上下文切换后才能执行进程A,上下文切换也是具有一定的延时性
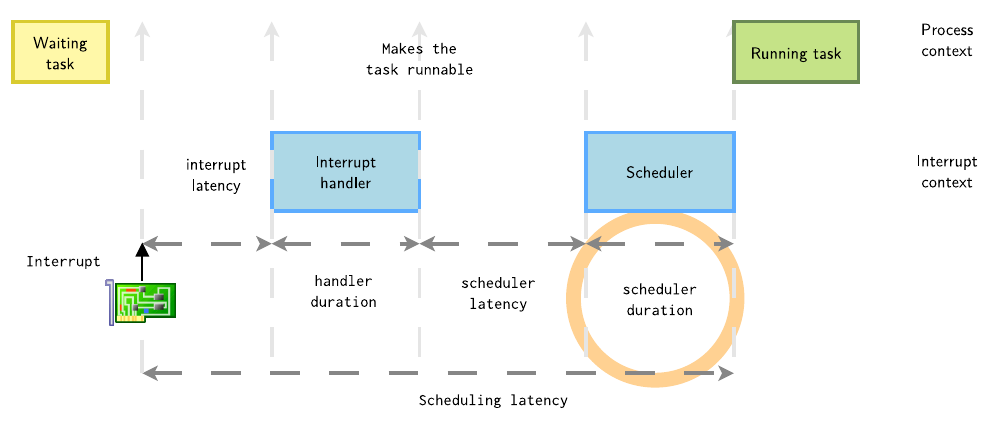
除了前面详细讲解的关键路径之外,Linux的其他非确定性机制也会影响实时任务的执行时间,例如linux是一个基于虚拟内存,由MMU提供,因此内存是按需分配的。每当应用程序首次访问代码和数据时,它都是按需加载的,这也会导致巨大的延时,同时C库服务和内核服务在设计的时候并未考虑实时约束。
1.5优先级倒置
内核抢占是指操作系统内核能够在某些情况下抢占正在运行的任务并切换到更高优先级的任务。但是在实际的场景中,可能会存在优先级翻转的问题导致系统响应下降。
例如,低优先级的进程可能持有高优先级所需要的锁,从而有效地降低该进程的优先级,如果中等优先级进程使用CPU,情况可能会更糟。在简单的情况下,只要低优先级任务(任务 L)持有锁,高优先级任务(任务 H)就会被阻塞。这被称为“有界优先级反转”,因为反转的时间长度受低优先级任务在临界区(持有锁)中的时间长度的限制。
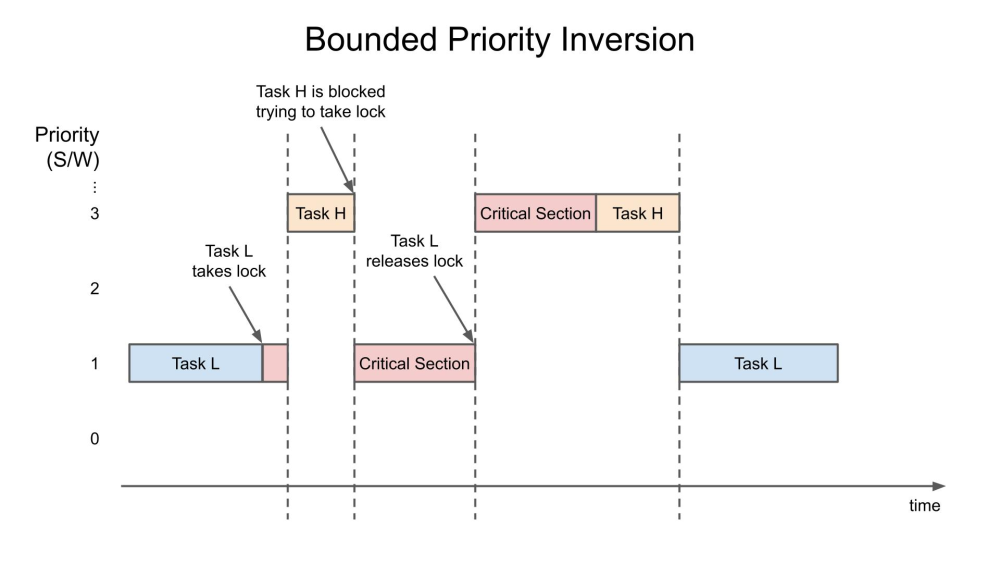
当中等优先级任务(任务 M)在持有锁时中断任务 L 时,会发生无限优先级反转。之所以称为“无界”,是因为任务 M 现在可以有效地阻止任务 H 任意时间,因为任务 M 正在抢占任务 L(它仍然持有锁)。下面简化了这种危险的事件序列,其过程如下:
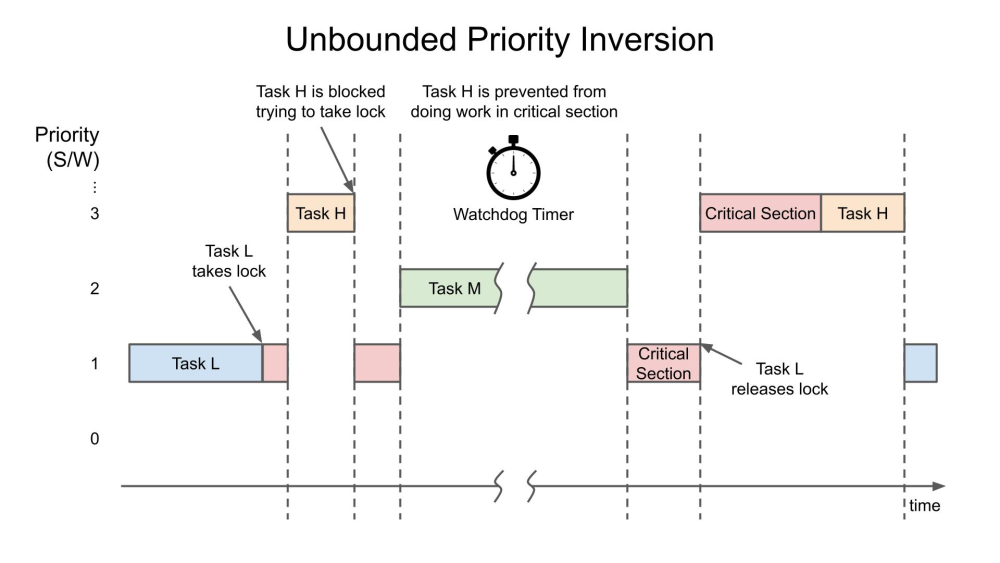
低优先级任务L和高优先级的任务H共享资源,在任务L获取资源后不久,任务H就开始运行。但是任务H必须等待任务L完成资源,因此它被挂起
在任务L完成资源之前,任务M准备好运行,抢占任务L,当任务M(可能还有其他中等优先级的任务)运行时,系统中的最高优先级任务H仍然处于挂起状态。
2. 为什么需要内核抢占
当一个以优先级为主的调度器中,当一个新的进程(下图中的task2)进入到可执行(running)的状态,核心的调度器会检查它的优先级,若该进程的优先权比目前正在执行的进程(下图中的task1)还高,核心调度器便会触发抢占(preempt),使得正在执行的进程被打断,而拥有更高优先级的进程会开始执行。
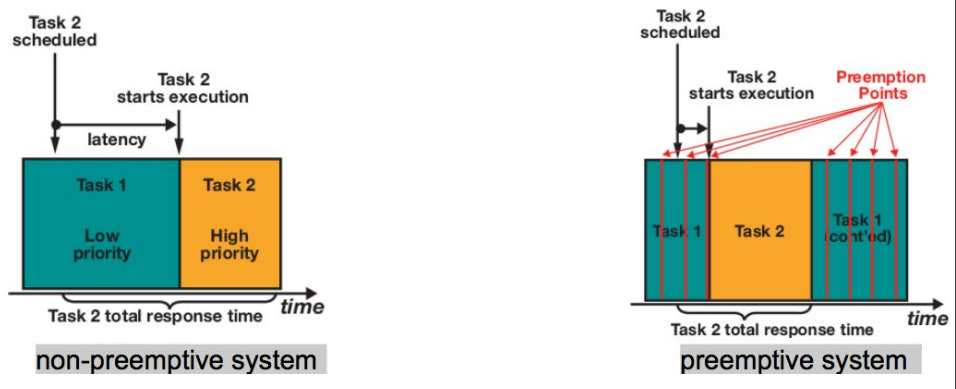
在不支持内核抢占模型中,抢占点比较少,对于内核抢占,如右图会在系统中添加很多抢占点,同时会导致执行时间会比左图多一点,可抢占会导致每隔一定时间去检查是否需要抢占,这样也会影响cache,pipeline,这样就会牺牲吞吐量。从上面图可以看出,操作系统演进过程中,不是新的就一定比旧的好,需要考量场景选择合适的方案。从这张图我们可以看出,内核抢占主要解决以下问题:
提高系统响应实时性和用户体验:在不支持内核抢占式内核中,低优先级任务可能会长时间占用CPU,导致高优先级任务无法及时得到处理,主要解决的是latency问题。这种情况会显著影响系统的响应速度,特别是在实时应用中,可能导致严重的性能问题。对于手机场景中,当用户在使用应用程序时,内核抢占可以确保用户界面关键线程得到足够的CPU时间,避免界面卡顿和延迟。
避免优先级翻转:内核抢占结合优先级继承(Priority Inheritance)等机制,可以有效缓解优先级翻转问题。当低优先级任务持有高优先级任务需要的资源时,内核抢占机制可以提高低优先级任务的优先级,使其尽快释放资源,从而减少高优先级任务的等待时间。在Linux中,从2.6开始,rtmutex支持优先级继承,解决优先级翻转的问题。
所以需要内核抢占的根本原因就是系统在吞吐量和及时响应之间进行权衡的结果,对于Linux作为一个通用的操作系统,其最初设计就是为了throughput而非确定性时延而设计。但是越来越多的场景对及时响应的要求越来越高,让更高优先级的任务和关键的任务及时得到调度,特别对于我们手机这种交互式的场景中。
3.抢占模型
将抢占视为减少调度程序延迟的一种方法可能很有用,但减少延迟通常也会影响吞吐量,因此需要在完成大量工作(高吞吐量)和在任务准备好运行时立即调度任务(低延迟)之间保持平衡。Linux 内核支持多种抢占模型,以便您可以根据工作负载调整抢占行为。为了让用户根据自己的需求进行配置,Linux 提供了 3 种 Preemption Model:
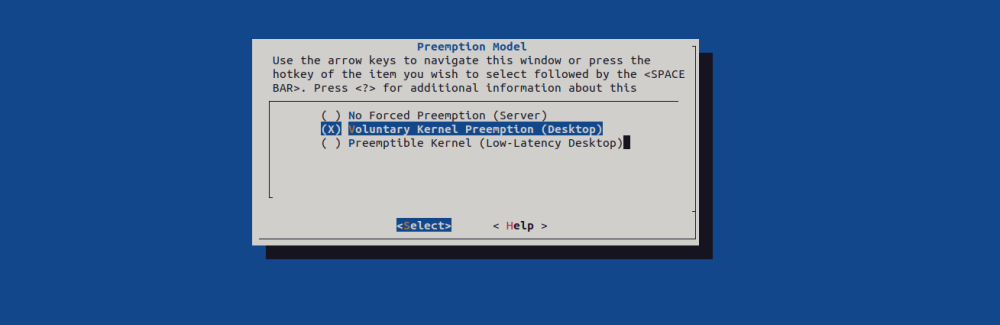
CONFIG_PREEMPT_NONE=y:不允许内核抢占,吞吐量最大的 Model,一般用于 Server 系统,其特点如下(红色:non-preemptible,绿色:preemptible):

该模式下只支持用户抢占,系统调用返回和中断是唯一的抢占点
CONFIG_PREEMPT_VOLUNTARY=y:内核核心系统的开发者开始着手做低延迟优化,其中一个优化点就是如果有高优先级进程需要处理器,内核代码也可以被抢占。在一些耗时较长的内核代码中主动调用cond_resched()让出CPU,对吞吐量有轻微影响,但是系统响应会稍微快一些。主动抢占(voluntary preemption)功能,它为内核增加了一个受限的内核抢占模式,并且一直使用到现在。

通过向运行在内核模式下的几个代码添加显式抢占点,目前内核中有近千个抢占点,检查是否经常需要重新调度,并且通过增加必须使用抢占的频率,减少抢占延迟。
CONFIG_PREEMPT=y:除了处于持有 spinlock 时的 critical section,其他时候都允许内核抢占,响应速度进一步提升,吞吐量进一步下降,一般用于 Desktop / Embedded 系统,目前Andorid中使用的这个配置项

正如抢占选项名称所暗示的那样,这些设置中的每一项都有适当的用例。服务器抢占可用于吞吐量是最重要的。另一方面,实时抢占应该用在嵌入式系统中,其中绝对吞吐量并不重要,但最大体验延迟才是关键。因此,Linux中不同的抢占级别可以在不同的环境中提供很大的灵活性

另外,还有一个没有合并进主线内核的 Model: CONFIG_PREEMPT_RT,这个模式几乎将所有的 spinlock 都换成了 preemptable mutex,只剩下一些极其核心的地方仍然用禁止抢占的 spinlock,所以基本可以认为是随时可被抢占,这部分不在本文讨论的范围之内。
4. 什么是内核抢占
说起这个抢占,在 Linux 内核的 2.4 时代,除非主动调度schedule,否则通常只允许从 system call 或者 interrupt 返回用户态的时候发生抢占(即产生中断前,也在用户态),这可称之为 "User Preemption"。对于用户抢占,只支持程序执行在用户态空间的时候,才可以被抢占,如果进程在Kernel空间执行(系统调用),是不允许抢占的。其执行过程如下:
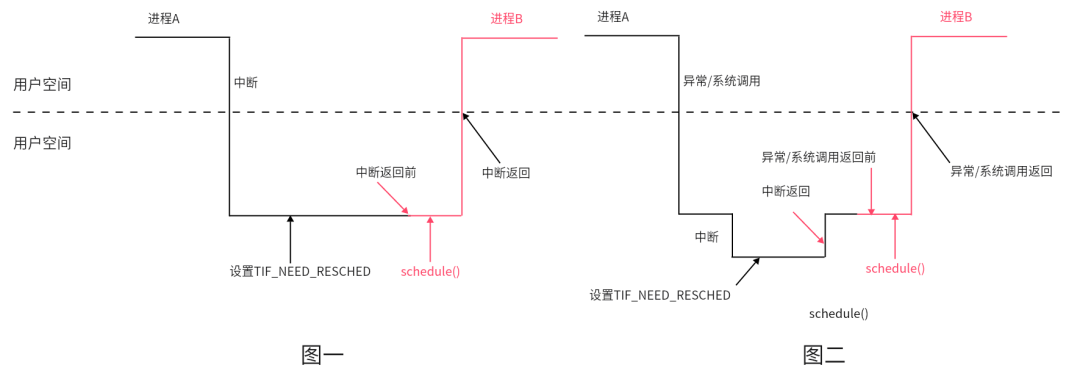
如上图一,假设周期性中断发生在进程A用户空间,此时进入到内核空间,在周期性调度器实现函数中设置了进程A的TIF_NEED_RESCHED标记位,则在时钟中断处理程序返回用户空间前夕,将调用schedule()函数执行进程调度
如上图二,假设周期性中断发生在进程A在内核空间运行之时,时钟中断返回前并不会执行进程调度,因为这时返回的是内核空间,而不是用户空间。在进程A从内核空间返回用户空间前的工作中,才会检测TIF_NEED_RESCHED标记位,置位则执行进程调度
何为内核抢占?简单地说就是当进程进入内核空间运行时,能否被抢占,被剥夺CPU控制权,执行进程调度,从而运行其它进程。还是以中断和异常为例,对比其差异
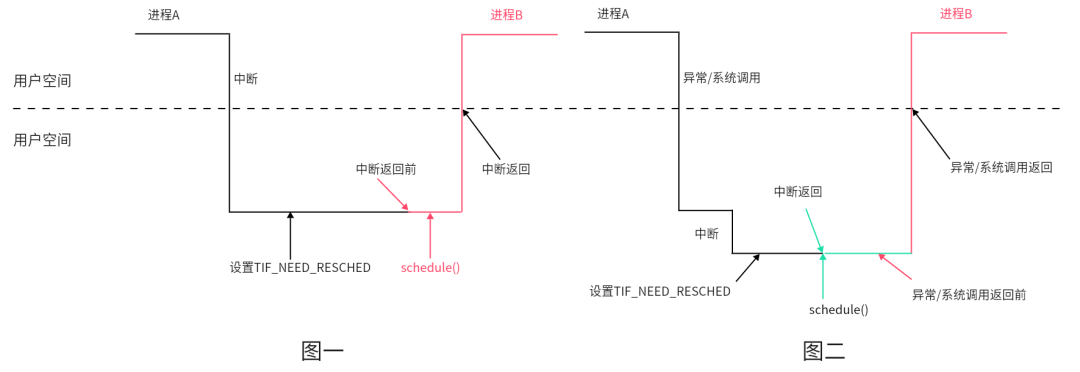
如上图一,假设周期时钟中断发生在进程A用户空间,此时的处理与不支持内核抢占时相同,在中断处理程序返回用户空间前夕的工作中,执行进程调度。
如上图二,假设周期时钟中断发生在进程A在内核空间运行时,在时钟中断处理程序返回内核空间前的工作中就可能会执行进程调度(抢占计数需为0)。如果在中断处理程序返回内核空间前没有执行进程调度,则在返回用户空间前执行,与不支持内核抢占时相同。
5.Linux抢占标志位--TIF_NEED_RESCHED
首先,我们从数据结构开始,我们会详细探讨thread_info数据结构和它在Linux抢占中的作用和关系
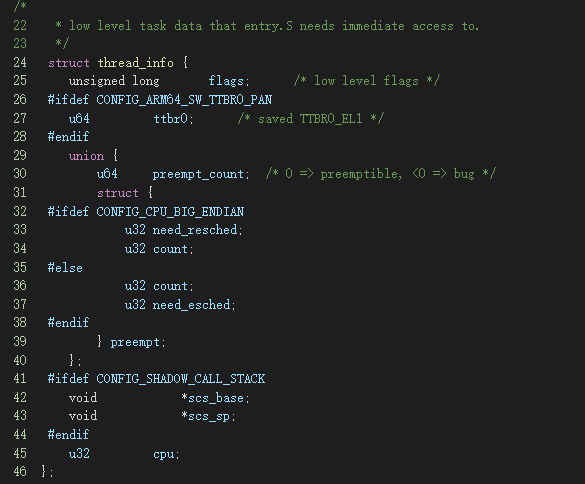
这个数据结构与抢占的发展历程也有关系,其提供功能如下:
调度标志位设置:早期的Linux,只需要调用set_tsk_need_resched 给当前任务设置 struct thread_info 的 TIF_NEED_RESCHED 标志,所以就提供了一个thread_info的flags中有一个是TIF_NEED_RESCHED,后面会详细介绍
抢占计数:为了实现内核抢占,新加入preempt_count,这笔提交请参考arm64: preempt: Provide our own implementation of asm/preempt.h,可以发现它是一个共用体,内核某些路径使用preempt_count,有的是preempt,为何会使用这么奇怪的定义呢?后面将详细揭晓答案
内核如何检查一个进程是否需要被调度呢?早期的Linux,在即将返回用户空间时,检查进程是否需要重新调度,如果设置了,就会发生调度,内核主要是在thread_info的flag重设置标识来标记进程是否需要被调度,即重新调度need_resched标识TI_NEED_RESCHED,其主要的接口函数为

当内核的某个路径设置重新调度标志(如时钟中断tick 时),会调用到resched_curr 来设置重新调度标志:可以看到除了设置任务的flags 的TIF_NEED_RESCHED 标志外,还设置了preempt.need_resched 为0

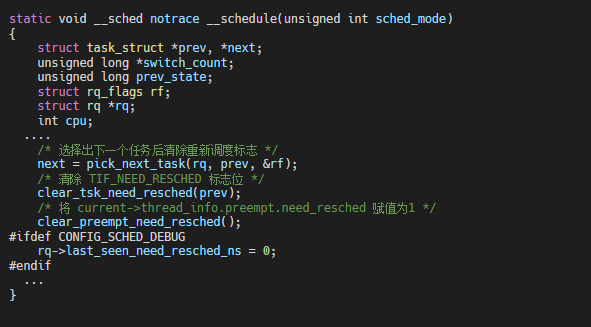
清抢占标志,__schedule 中pick到下一个任务后会清除抢占标志,其代码实现为:
6. 抢占计数preempt_count
在像Linux这样的多任务系统中,任何执行线程都不能保证只要它想运行就可以独占访问处理器。内核总是有能力(多数情况下)抢占一个正在运行的线程,而选择一个优先级更高的线程来执行。新线程可能是另一个不同的进程,但也可能是一个硬件中断,或者其他外部事件。
为了正确协调系统中所有任务能正确运行,内核必须跟踪当前的执行状态,包括已经被抢占或可能阻止线程被抢占的各种情况。用来进行这个追踪记录的基础,就是在系统中每个任务里存储的 preemption counter。这个计数器是通过 preempt_count() 函数来访问的,它的通用定义是这样的:

这个 counter 可以用来指示当前线程的状态、它是否可以被抢占,以及它是否被允许睡眠。要实现这个功能的话,就必须在这个 counter 里面记录若干种不同状态,因此这个 preempt_count 也被分成了几个字段(sub-fields):
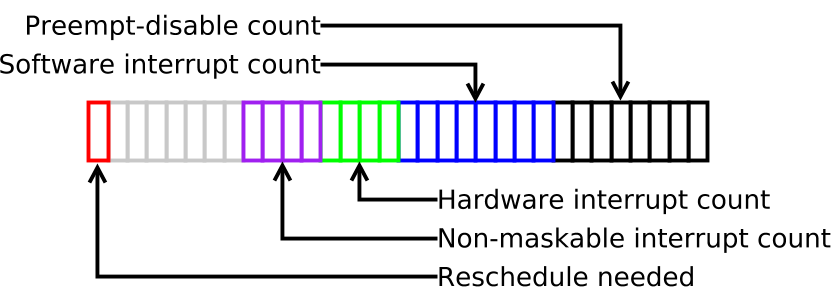
最低位的这个 byte 是用来记录 preempt_disable()嵌套调用的次数,也就是到目前为止 preemption 被 disable 的次数。
SOFTIRQ:当CPU进入软中处理程序时,对该位域加1,退出时减1
HARDIRQ:当CPU进入硬件中断处理函数时,对该位域加1,退出时减1,位域数值表示中断嵌套层级
NMI:CPU进入不可屏蔽中断处理函数时,此位置1,退出时清0。
最后,最高位表示内核是否已经决定当前进程需要在后面执行时一有机会就马上被调度出去,让给其他任务。
接下来,我们看看内核是如何定义这块的,其定义在include/linux/preempt.h

其每个bit的定义如下:
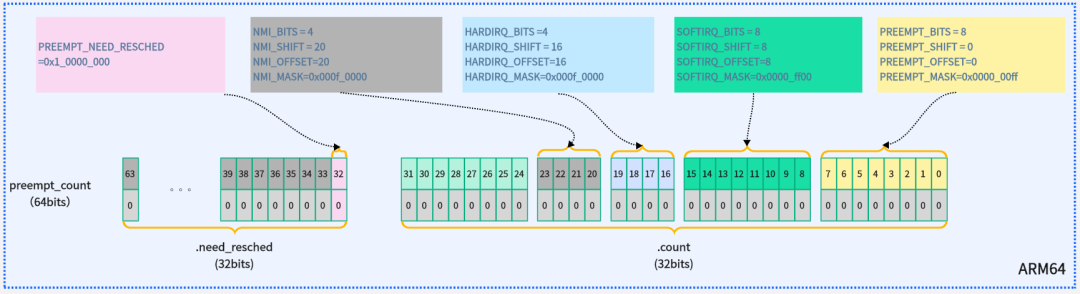
这里需要特别注意,preempt_count是允许嵌套的,在进入临界区,被中断打断,软中断都会存在preempt_count。下图展示了preempt_count相关的操作函数

这里要特别注意irq这个,它包含了NMI、IRQ和SOFTIRQ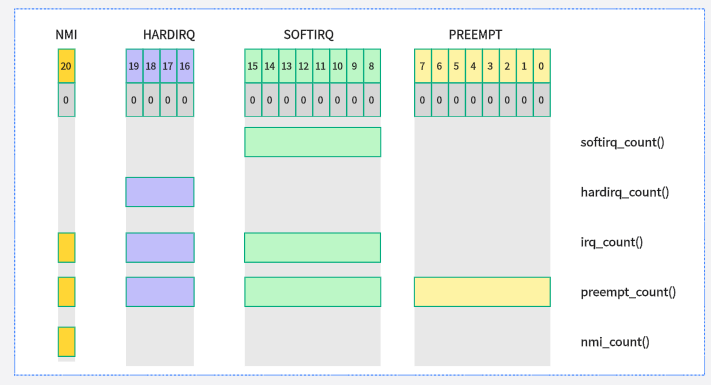
下图是preempt_count相关的条件判断函数,这个在抢占中会频繁用到

以下接口函数用于检测preempt_count成员相应位域值,用于检测CPU是否处于硬件中断、软中断等处理函数中(include/linux/preempt.h):
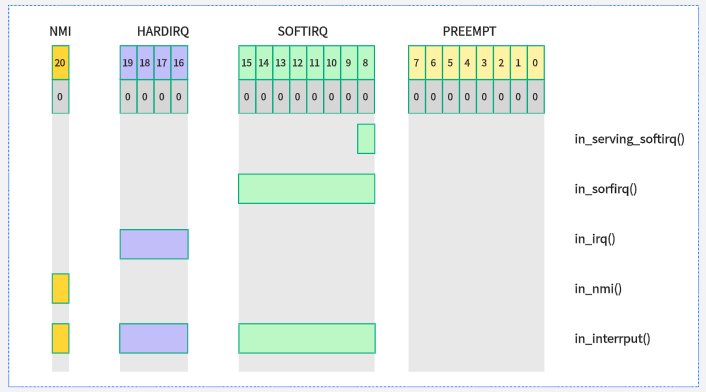
in_irq():当前CPU是否处于硬件中断处理程序内,返回HARDIRQ计数值。
in_softirq():当前CPU是否处于软中断处理函数内或禁止软中断,返回SOFTIRQ计数值。
in_serving_softirq():当前CPU是否处于软中断处理函数内。
in_nmi():CPU是否处于不可屏蔽中断处理程序内,返回NMI计数值。
in_interrupt():CPU是否处于中断处理程序内(或禁止软中断状态),包括硬件中断、软中断和不可屏蔽中断。
只要看一下 preempt_count 的值,内核就可知道当前的情况如何。比如,preempt_count 是非零值,就表示当前线程不能被 scheduler 抢占:要么是 preemption 已经被明确 disable 了,要么是 CPU 当前正在处理某种中断。
同理,非零值也表示当前线程不能睡眠,因为它此刻在运行的上下文必须要持续执行完成。"reschedule needed" 这个 bit 告诉内核,当前有一个优先级较高的进程应该在第一时间获得 CPU。必须要在 preempt_count 为非零值的情况下,才会设置这个 bit。否则的话,内核早就可以直接对这个进程进行 prempt 抢占,而不是设置此 bit 并等待。
那么哪些情况下,会操作preempt_count,下面是preempt_count相关操作函数
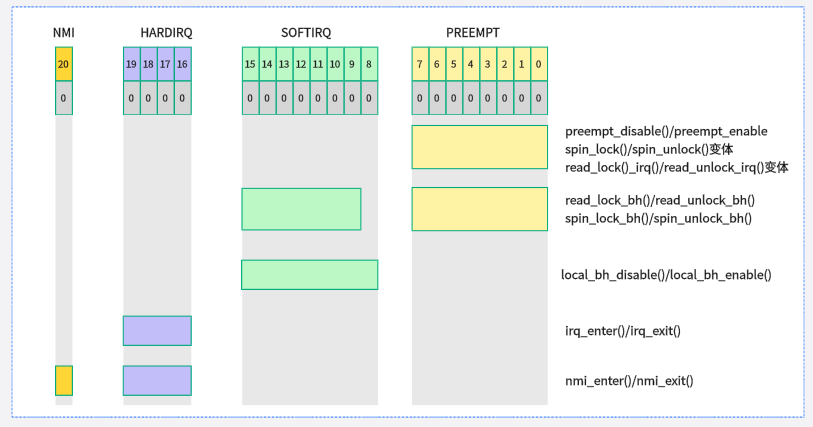
对于这些接口以及相关变体,都是内核中通用的接口API,所以系统实时性会受驱动中如何使用这些接口的影响。这里我们来看看经常讨论的中断上下文、进程上下文和atomic上下文的关系,首先我们来看看代码实现:
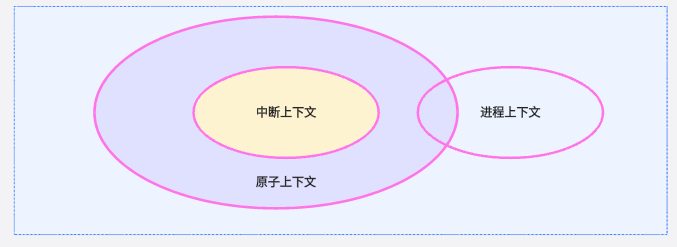
所以总结一下,对于内核什么时候不允许抢占,在哪些时机是不可调度的,想要搞清这个问题,首先需要介绍一下linux中的四类区间:
中断
软中断
进程上下文中的spin_lock
进程上下文中的其他区域
上述四类区间中,只有第四类区间支持抢占调度,对于1,2,3也就是atomic上下文。当可以调度的事情发生在前3类区间中,即如果在这3类区间中唤醒了高优先级的可以抢占的task,实际上却不能抢占,直到这3类区间结束。那么对于4类区间是不是一定能发生抢占呢?
7. preempt_enable
为了支持内核抢占 而引入了 preempt_count ,如果为 0,就允许 Kernel Preemption,否则就不允许。内核函数preempt_enable/preempt_disable用来内核代码临界区动态关闭和打开内核抢占,详细的用法请参考preempt-locking。
内核代码中preempt_disable()和preempt_enable()函数总是成对出现的,用于保证进程在执行这两个函数之间的代码时,不会发生进程调度(当前进程不会被抢占,不被抢占不是说不能被中断,硬件中断还是允许的,只是中断还是返回原进程)
preempt_disable()函数用于禁止内核抢占,函数定义如下(include/linux/preempt.h)

这个比较简单,preempt_count加一,然后做了一个内存屏障,增加抢占计数器以防止重新调度,不管处于哪种抢占模式,都不允许抢占。
内核抢占函数preempt_enable()定义在include/linux/preempt.h头文件内:
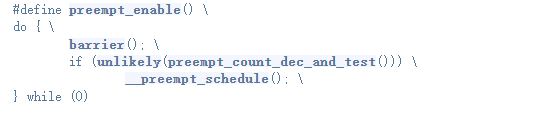
preempt_enable()函数内对抢占计数值减1,如果减1后为0,并且进程TIF_NEED_RESCHED标记置位了,则调用__preempt_schedule()函数执行进程调度(抢占当前进程)。

对于ARM64,使用64位的preempt_count,通过将其划分为count和need_resched来管理,判断 preempt_count 和 TIF_NEED_RESCHED 看是否可以被抢占

这个首先来检查若当前CPU处于关中断状态和preempt_count不为0,就禁止抢占,反之就执行抢占。
内核代码里面通常直接调用preempt_enable比较少,但是调用锁的地方比较多,例如常见的spinlock等,目前内核的这种锁机制又是一个处于泛滥的趋势,所以可以认为每次调用spinlock结束时默认都会发起一次隐式抢占

8. Linux内核中的抢占实现
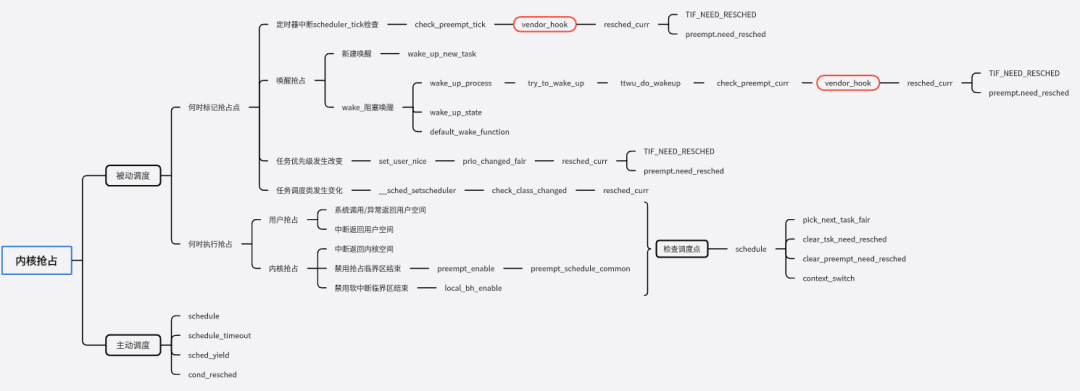
在当前进程被抢占的场景下,调度并不是立刻发生,而是延迟执行,具体的方法是设定当前进程的need_resched等于1,然后静静的等待最近一个调度点的来临,当调度点到来的时候,内核会调用schedule函数,抢占当前task的执行。这部分的内容比较多,有兴趣的同学可以自行查看源码,大致梳理了一个相关知识的导图。
9. 案例分析
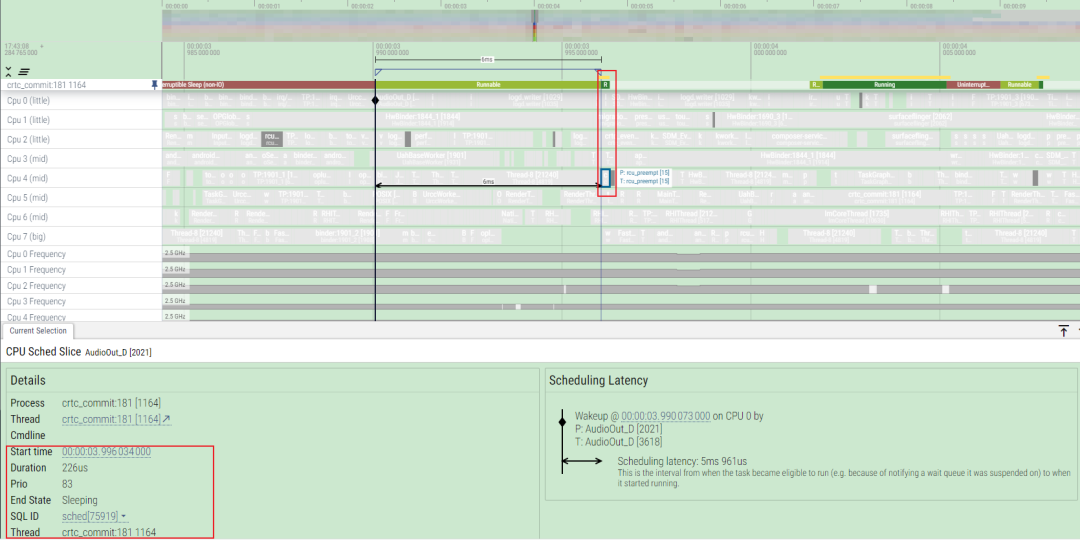
对于性能开发的同学,经常会遇到这种runnable很长的问题,那么我们以下面这个为例,crtc_commit的RT线程长时间runnable,为什么没抢占cfs的线程
首先,我们来看看结合梳理下整个流程是如何的,有什么影响因素,关键问题卡在哪个环节
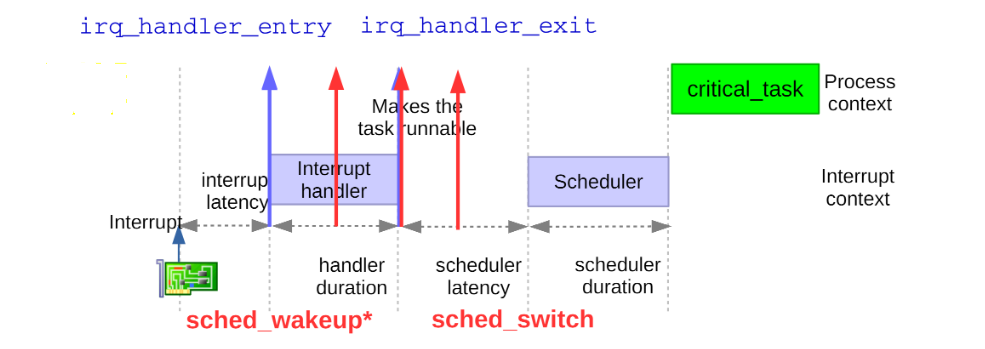
结合目前的ftrace下相关tracepoint,大致就可以有一个分析问题的思路
首先从日志来看,当唤醒的时刻,这个crtc_commit线程会发生选核,从选核逻辑上看,这个线程选择了cpu1,而后差不多6ms后被做了loadbalance迁移到cpu4上

为什么会出现在选核完成后,没有第一时间内抢占cpu1上的HwBinder:1844_1这个线程,为什么没有发生正常的一次调度?如何看这个问题?还有这个线程为什么能运行这么久?
目前对于内核ftrace提供分析的方法

这个代码的实现如下,详细的可以参考代码和ftrace.txt
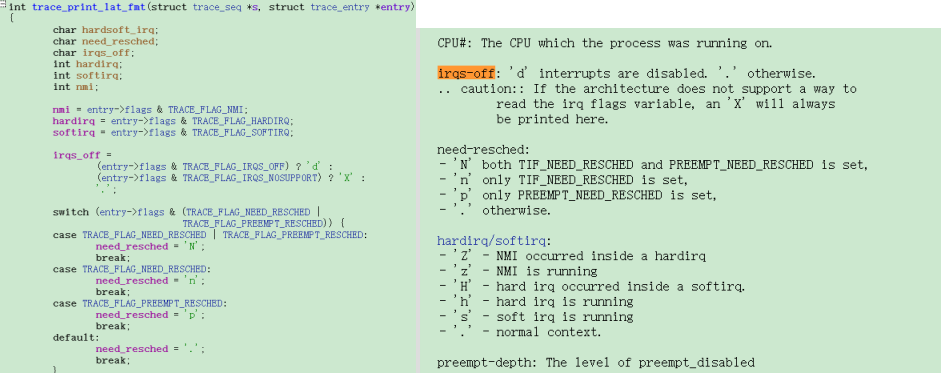
那我们就可以通过这个方法来看看,这个HwBinder:1844_1在选核的时候发生了什么情况?可以看到这个时候中断被关闭了,同时preempt也被disable了

同时arch定时器中断也有延迟,通常至少需要 4ms 会出现 arch 定时器中断,而出现问题这段时间内,系统arch_timer也出现问题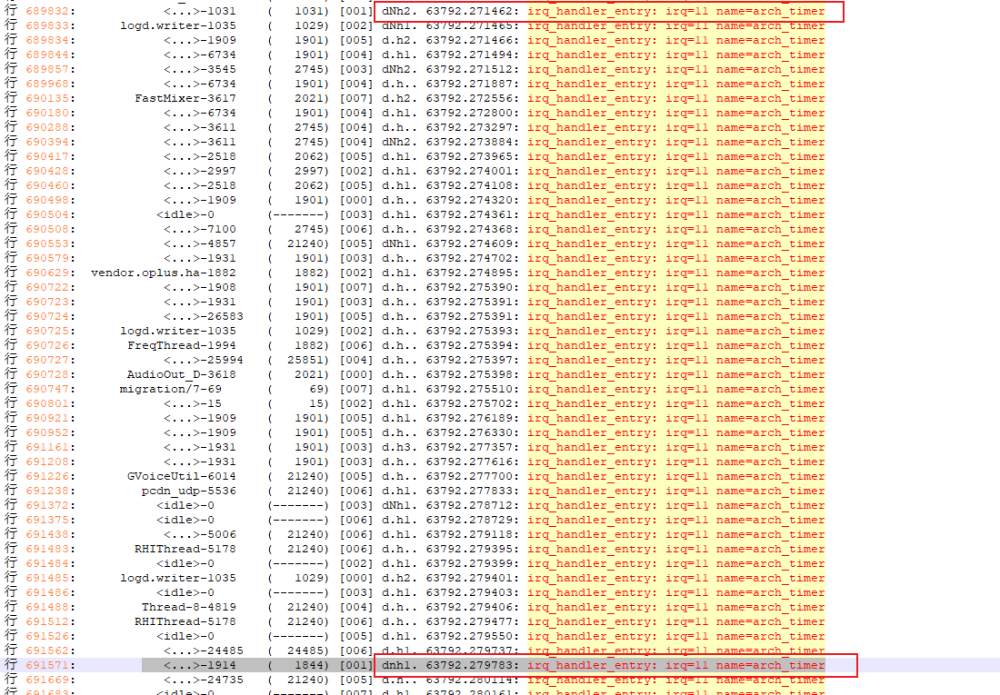
下一步就需要去排查驱动中是哪里会关这么长时间的中断,可以开启preemptirq和preemptirq_long相关的tracepoint进行复现debug,所以在写内核代码的时候,需要关注preempt_count相关操作函数及其变体函数,这个会切身影响到系统的实时性。
10. 总结
本文档主要探讨了Linux 6.1内核中抢占特性的原理和实现,重点关注latency产生原因、内核抢占模型与机制以及实例分析,而目前遇到的痛点问题是抢占造成资源竞争,以及锁和中断延迟对于实时性的影响,特别目前锁是一个通用的API接口,任何驱动都可以随便使用,导致得不到及时抢占。
Linux内核的抢占机制与中断、锁机制之间的矛盾是提高系统实时性和系统优化的的一大挑战,也希望PREEMPT_RT的实时补丁能尽快合进内核主线,增强了Linux内核的实时性能,通过减少不可抢占的临界区和优化中断处理来提高抢占性。
审核编辑:彭菁
-
Linux
+关注
关注
87文章
11311浏览量
209684 -
函数
+关注
关注
3文章
4332浏览量
62684 -
模型
+关注
关注
1文章
3253浏览量
48874 -
API接口
+关注
关注
1文章
84浏览量
10438
原文标题:全方位剖析内核抢占机制
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
在计算指令周期时(Delay_Slot),其是否包括了功能单元的延时时间(Function Uint Latency)?
[DM385] Latency Performance
什么是谐波_电力系统中谐波产生的原因和危害
请问修改DEFAULT_DESIRED_SLAVE_LATENCY 值?
Latency TestUAC设备的相关资料分享
TMOS设置DEFAULT_DESIRED_SLAVE_LATENCY会不会造成什么不良后果?
i.MX8MP EQOS MAC_Ingress_Timestamp_Latency和MAC_Egress_Timestamp_Latency始终为0的原因?
JESD204B SystemC module Deterministic Latency(四)
Zero Latency与微软、惠普和英特尔合作 共同打造下一代VR娱乐平台
Zero Latency VR与育碧合作 共同打造沉浸式VR游戏
Low Latency High Bandwidth Memory 数据表(Digest Edition)

时序分析基本概念介绍<Latency>
Low Latency High Bandwidth Memory 数据表(Digest Edition)





 工商网监
工商网监
评论