 如何从处理器和加速器内核中榨取最大性能?
如何从处理器和加速器内核中榨取最大性能?
本文由半导体产业纵横(ID:ICVIEWS)编译自semiengineering
利用缓存增强低成本、上一代或中端的 SoC。
一些设计团队在创建片上系统(SoC)设备时,有幸能够使用最新和最先进的技术节点,并且拥有相对不受限制的预算来从可信的第三方供应商那里获取知识产权(IP)模块。然而,许多工程师并没有这么幸运。对于每一个“不惜一切代价”的项目,都有一千个“在有限预算下尽你所能”的对应项目。
一种从成本较低、早期代、中档处理器和加速器核心中挤出最大性能的方法是,明智地应用缓存。
削减成本图1展示了一个典型的成本意识SoC场景的简化示例。尽管SoC可能由许多IP组成,但这里为了清晰起见,只展示了三个。
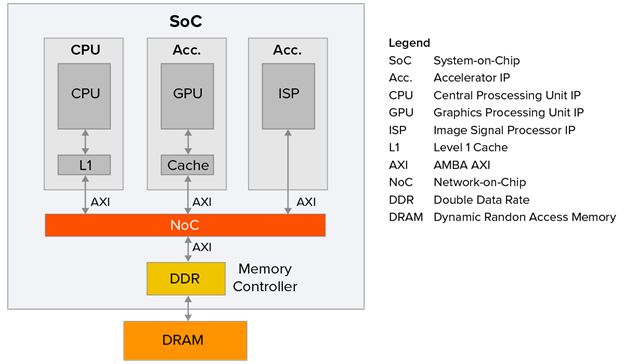
图 1SoC内部IP之间连接的主要技术是网络片上(NoC)互连IP。这可以被看作是一个跨越整个设备的IP。图1中展示的例子可以假定为一个非缓存一致性场景。在这种情况下,任何一致性需求将由软件处理。
假设SoC的时钟运行在1GHz。假设一个基于精简指令集计算机(RISC)架构的中央处理单元(CPU)运行一个典型指令将消耗一个时钟周期。然而,访问外部DRAM内存可能需要100到200个处理器时钟周期(为了本文的目的,我们将这个平均为150个周期)。这意味着,如果CPU没有一级(L1)缓存,并且通过NoC和DDR内存控制器直接连接到DRAM,那么每个指令将消耗150个处理器时钟周期,导致CPU利用率仅为1/150 = 0.67%。
这就是为什么CPU以及一些加速器和其他IP使用缓存内存来提高处理器利用率和应用程序性能。缓存概念基于的基本原理是局部性原则。这个观点是,在任何给定时间,只有一小部分主内存被使用,而且那个空间中的位置被多次访问。主要是由于循环、嵌套循环和子程序,指令及其相关数据经历时间、空间和顺序局部性。这意味着,一旦一块指令和数据从主内存复制到IP的缓存中,IP通常会反复访问它们。
当今高端CPU IP通常至少有一个一级(L1)和二级(L2)缓存,它们通常还有一个三级(L3)缓存。此外,一些加速器IP,如图形处理单元(GPU)通常有自己的内部缓存。然而,这些最新一代的高端IP的价格通常比上一代中档产品高出5倍到10倍。因此,正如图1所示,一个注重成本的SoC中的CPU可能只配备了一个L1缓存。
更深入地考虑CPU及其L1缓存。当CPU在其缓存中请求某物时,结果被称为缓存命中。由于L1缓存通常以与处理器核心相同的速度运行,因此缓存命中将在单个处理器时钟周期内处理。相比之下,如果请求的数据不在缓存中,结果称为缓存未命中,将需要访问主内存,这将消耗150个处理器时钟周期。
现在考虑运行1,000,000条指令。如果缓存足够大以包含整个程序,那么这将只消耗1,000,000个时钟周期,从而实现100%的CPU效率。
不幸的是,中档CPU中的L1缓存通常只有16KB到64KB的大小。如果我们假设95%的缓存命中率,那么我们的1,000,000条指令中的950,000条将需要一个处理器时钟周期。其余的50,000条指令每条将消耗150个时钟周期。因此,这种情况下的CPU效率可以计算为1,000,000/((950,000 * 1) + (50,000 * 150)) = ~12%。
提升性能
提高注重成本SoC性能的一种成本效益高的方式是添加缓存IP。例如,Arteris的CodaCache是一个可配置的、独立的非一致性缓存IP。每个CodaCache实例可以高达8MB,并且可以在同一个SoC中实例化多个副本,如图2所示。
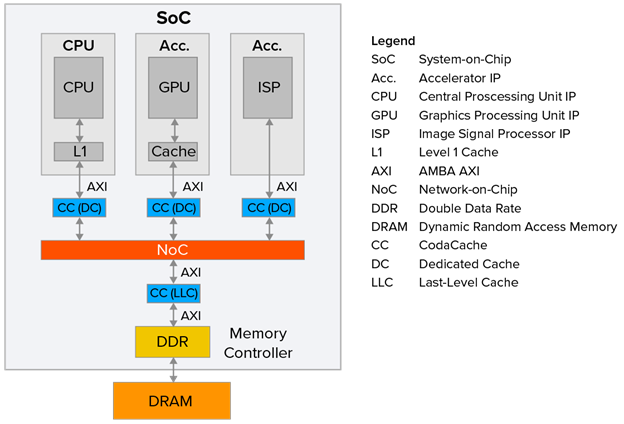
图2
本文的目的并不是建议每个IP都应该配备一个CodaCache。图2仅旨在提供潜在CodaCache部署的示例。
如果一个CodaCache实例与一个IP关联,它被称为专用缓存(DC)。或者,如果一个CodaCache实例与一个DDR内存控制器关联,它被称为末级缓存(LLC)。DC将加速与其关联的IP的性能,而LLC将增强整个SoC的性能。
作为我们可能期望的性能提升类型的一个示例,考虑图2中显示的CPU。让我们假设与这个IP关联的CodaCache DC实例以处理器速度的一半运行,并且对这个缓存的任何访问消耗20个处理器时钟周期。如果我们还假设这个DC有95%的缓存命中率,那么对于1,000,000条指令——我们的整体CPU+L1+DC效率可以计算为1,000,000/((950,000 * 1) + (47,500 * 20) + (2,500 * 150)) = ~44%。这是一个~273%的性能提升!
结论过去,嵌入式程序员喜欢挑战,尽可能从时钟速度低、内存资源有限的小处理器中挤出最高性能。事实上,计算机杂志通常会向读者提出挑战,例如:“谁能在处理器Y上使用最少的时钟周期和最小的内存量执行任务X?”
今天,许多SoC开发者喜欢挑战,尽可能从他们的设计中挤出最高性能,特别是如果他们被限制使用性能较低的中档IP。部署CodaCache IP作为专用和末级缓存,为工程师提供了一种负担得起的方式来提升他们注重成本的SoC的性能。
-
处理器
+关注
关注
68文章
19533浏览量
231849 -
内核
+关注
关注
3文章
1391浏览量
40596 -
加速器
+关注
关注
2文章
813浏览量
38368
发布评论请先 登录
相关推荐
充分利用数字信号处理器上的片内FIR和IIR硬件加速器
【FPGA干货分享六】基于FPGA协处理器的算法加速的实现
【Aworks申请】中国科学院高能物理所质子直线加速器chopper电源
AM57x处理器实施多种内核
正确进行多内核之间的应用划分(Ⅱ)
采用控制律加速器的Piccolo MCU
如何充分利用数字信号处理器上的片内FIR和IIR硬件加速器?
D-2700和D-1700处理器产品资料
利用硬件加速器提高处理器的性能
如何解放你的内核?硬件加速器“使用指南”奉上

利用数字信号处理器上的片上FIR和IIR硬件加速器
硬件加速器提升下一代SHARC处理器的性能





 工商网监
工商网监
评论