 ClickHouse内幕(3)基于索引的查询优化
ClickHouse内幕(3)基于索引的查询优化

ClickHouse索引采用唯一聚簇索引的方式,即Part内数据按照order by keys有序,在整个查询计划中,如果算子能够有效利用输入数据的有序性,对算子的执行性能将有巨大的提升。本文讨论ClickHouse基于索引的查询算子优化方式。
在整个查询计划中Sort、Distinct、聚合这3个算子相比其他算子比如:过滤、projection等有如下几个特点:1.算子需要再内存中保存状态,内存代价高;2.算子计算代价高;3.算子会阻断执行pipeline,待所有数据计算完整后才会向下游输出数据。所以上算子往往是整个查询的瓶颈算子。
本文详细讨论,3个算子基于索引的查询优化前后,在计算、内存和pipeline阻断上的影响。
实验前准备:
后续的讨论主要基于实验进行。
CREATE TABLE test_in_order ( `a` UInt64, `b` UInt64, `c` UInt64, `d` UInt64 ) ENGINE = MergeTree ORDER BY (a, b);
表中总共有3个part,每个part数据量4条。
PS: 用户可以在插入数据前提前关闭后台merge,以避免part合并成一个,如果part合并成一个将影响查询并行度,可能对实验有影响,以下查询可以关闭后台merge:system stop merges test_in_order
一、Sort算子
如果order by查询的order by字段与表的order by keys的前缀列匹配,那么可以根据数据的有序特性对Sort算子进行优化。
1.Sort算子实现方式
首先看下不能利用主键有序性的场景,即对于order by查询的order by字段与表的order by keys的前缀列不匹配。比如下面的查询:
query_1: EXPLAIN PIPELINE SELECT b FROM read_in_order ORDER BY b ASC
它的执行计划如下:
┌─explain───────────────────────────────┐ │ (Expression) │ │ ExpressionTransform │ │ (Sorting) │ │ MergingSortedTransform 3 → 1 │ │ MergeSortingTransform × 3 │ │ LimitsCheckingTransform × 3 │ │ PartialSortingTransform × 3 │ │ (Expression) │ │ ExpressionTransform × 3 │ │ (ReadFromMergeTree) │ │ MergeTreeThread × 3 0 → 1 │ └───────────────────────────────────────┘
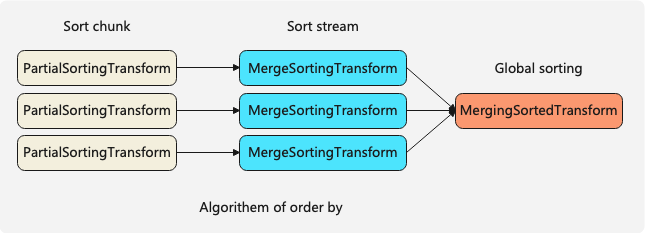
排序算法由3个Transform组成,其中
1)PartialSortingTransform对单个Chunk进行排序;
2)MergeSortingTransform对单个stream进行排序;
3)MergingSortedTransform合并多个有序的stream进行全局sort-merge排序
如果查询的order by字段与表的order by keys的前缀列匹配,那么可以根据数据的有序特性对查询进行优化,优化开关:optimize_read_in_order。
2.匹配索引列的查询
以下查询的order by字段与表的order by keys的前缀列匹配
query_3: EXPLAIN PIPELINE SELECT b FROM test_in_order ORDER BY a ASC, b ASCSETTINGS optimize_read_in_order = 0 -- 关闭read_in_order优化
查看order by语句的pipeline执行计划
┌─explain───────────────────────────┐ │ (Expression) │ │ ExpressionTransform │ │ (Sorting) │ │ MergingSortedTransform 3 → 1 │ │ MergeSortingTransform × 3 │ │ (Expression) │ │ ExpressionTransform × 3 │ │ (ReadFromMergeTree) │ │ MergeTreeThread × 3 0 → 1 │ └───────────────────────────────────┘
此时order by算子的算法
1)首先MergeSortingTransform对输入的stream进行排序
2)然后MergingSortedTransform将多个排好序的stream进行合并,并输出一个整体有序的stream,也是最终的排序结果。
这里有个疑问在关闭read_in_order优化的查询计划中,系统直接默认了MergeSortingTransform的输入在Chunk内是有序的,这里其实是一个默认优化,因为order by查询的order by字段与表的order by keys的前缀列匹配,所以数据在Chunk内部一定是有序的。
3. 开启优化optimize_read_in_order
┌─explain──────────────────────────┐ │ (Expression) │ │ ExpressionTransform │ │ (Sorting) │ │ MergingSortedTransform 3 → 1 │ │ (Expression) │ │ ExpressionTransform × 3 │ │ (ReadFromMergeTree) │ │ MergeTreeInOrder × 3 0 → 1 │ └──────────────────────────────────┘
4. 优化分析
打开optimize_read_in_order后:
1.对于计算方面:算法中只有一个MergingSortedTransform,省略了单个stream内排序的步骤
2.由于内存方面:由于MergeSortingTransform是消耗内存最大的步骤,所以优化后可以节约大量的内存
3.对于poipeline阻塞:MergeSortingTransform会阻塞整个pipeline,所以优化后也消除了对pipeline的阻塞
二、Distinct算子
如果distinct查询的distinct字段与表的order by keys的前缀列匹配,那么可以根据数据的有序特性对Distinct算子进行优化,优化开关:optimize_distinct_in_order。通过以下实验进行说明:
1. Distinct算子实现方式
查看distinct语句的pipeline执行计划
query_2: EXPLAIN PIPELINE SELECT DISTINCT * FROM woo.test_in_order SETTINGS optimize_distinct_in_order = 0 -- 关闭distinct in order优化
┌─explain─────────────────────────────┐ │ (Expression) │ │ ExpressionTransform │ │ (Distinct) │ │ DistinctTransform │ │ Resize 3 → 1 │ │ (Distinct) │ │ DistinctTransform × 3 │ │ (Expression) │ │ ExpressionTransform × 3 │ │ (ReadFromMergeTree) │ │ MergeTreeThread × 3 0 → 1 │ └─────────────────────────────────────┘
Distinct算子采用两阶段的方式,首先第一个DistinctTransform在内部进行初步distinct,其并行度为3,可以简单的认为有3个线程在同时执行。然后第二个DistinctTransform进行final distinct。
每个DistinctTransform的计算方式为:首先构建一个HashSet数据结构,然后根据HashSet,构建一个Filter Mask(如果当前key存在于HashSet中,则过滤掉),最后过滤掉不需要的数据。
2.开启优化optimize_distinct_in_order
┌─explain────────────────────────────────┐ │ (Expression) │ │ ExpressionTransform │ │ (Distinct) │ │ DistinctTransform │ │ Resize 3 → 1 │ │ (Distinct) │ │ DistinctSortedChunkTransform × 3 │ │ (Expression) │ │ ExpressionTransform × 3 │ │ (ReadFromMergeTree) │ │ MergeTreeThread × 3 0 → 1 │ └────────────────────────────────────────┘
可以看到初步distinct和final distinct采用了不同的transform,DistinctSortedChunkTransform和DistinctTransform。
DistinctSortedChunkTransform:对单个stream内的数据进行distinct操作,因为distinct列跟表的order by keys的前缀列匹配,scan算子读取数据的时候一个stream只从一个part内读取数据,那么每个distinct transform输入的数据就是有序的。所以distinct算法有:
DistinctSortedChunkTransform算法一:
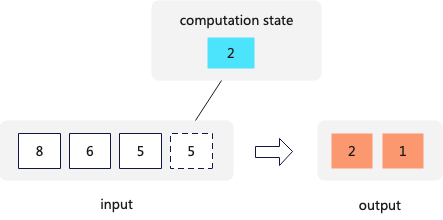
Transform中保留最后一个输入的数据作为状态,对于每个输入的新数据如果跟保留的状态相同,那么忽略,如果不同则将上一个状态输出给上一个算子,然后保留当前的数据最为状态。这种算法对于在整个stream内部全局去重时间和空间复杂度都有极大的降低。
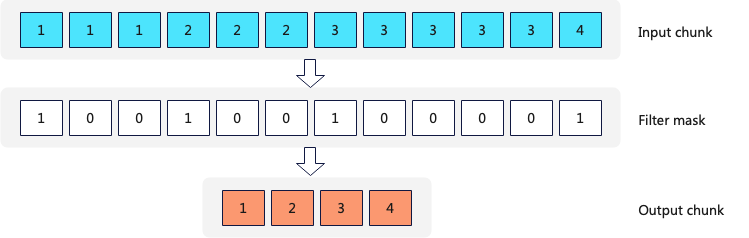
DistinctSortedStreamTransform算法二:(ClickHouse采用的)
Transform对与每个Chunk(ClickHouse中Transform数据处理的基本单位,默认大约6.5w行),首先将相同的数据划分成多个Range,并设置一个mask数组,然后将相同的数据删除掉,最后返回删除重复数据的Chunk。
3. 优化分析
打开optimize_distinct_in_order后:主要对于第一阶段的distinct步骤进行了优化,从基于HashSet过滤的算法到基于连续相同值的算法。
1.对于计算方面:优化后的算法,省去了Hash计算,但多了判断相等的步骤,在不同数据基数集大小下,各有优劣。
2.由于内存方面:优化后的算法,不需要存储HashSet
3.对于poipeline阻塞:优化前后都不会阻塞pipeline
三、聚合算子
如果group by查询的order by字段与表的order by keys的前缀列匹配,那么可以根据数据的有序特性对聚合算子进行优化,优化开关:optimize_aggregation_in_order。
1.聚合算子实现方式
查看group by语句的pipeline执行计划:
query_4: EXPLAIN PIPELINE SELECT a FROM test_in_order GROUP BY a SETTINGS optimize_aggregation_in_order = 0 -- 关闭read_in_order优化
┌─explain─────────────────────────────┐ │ (Expression) │ │ ExpressionTransform × 8 │ │ (Aggregating) │ │ Resize 3 → 8 │ │ AggregatingTransform × 3 │ │ StrictResize 3 → 3 │ │ (Expression) │ │ ExpressionTransform × 3 │ │ (ReadFromMergeTree) │ │ MergeTreeThread × 3 0 → 1 │ └─────────────────────────────────────┘
对于聚合算子的整体算法没有在执行计划中完整显示出来,其宏观上采用两阶段的聚合算法,其完整算法如下:1.AggregatingTransform进行初步聚合,这一步可以并行计算;2.ConvertingAggregatedToChunksTransform进行第二阶段聚合。(PS:为简化起见,忽略two level HashMap,和spill to disk的介绍)。
2.开启优化optimize_aggregation_in_order
执行计划如下:
┌─explain───────────────────────────────────────┐ │ (Expression) │ │ ExpressionTransform × 8 │ │ (Aggregating) │ │ MergingAggregatedBucketTransform × 8 │ │ Resize 1 → 8 │ │ FinishAggregatingInOrderTransform 3 → 1 │ │ AggregatingInOrderTransform × 3 │ │ (Expression) │ │ ExpressionTransform × 3 │ │ (ReadFromMergeTree) │ │ MergeTreeInOrder × 3 0 → 1 │ └───────────────────────────────────────────────┘
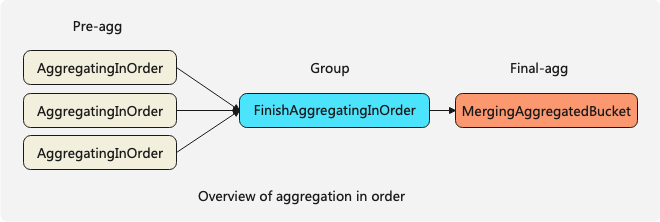
可以看到打开optimize_aggregation_in_order后aggregating算法由三个步骤组成:
1)首先AggregatingInOrderTransform会将stream内连续的相同的key进行预聚合,预聚合后在当前stream内相同keys的数据只会有一条;
2)FinishAggregatingInOrderTransform将接收到的多个stream内的数据进行重新分组使得输出的chunk间数据是有序的,假设前一个chunk中group by keys最大的一条数据是5,当前即将输出的chunk中没有大于5的数据;
3)MergingAggregatedBucketTransform的作用是进行最终的merge aggregating。
FinishAggregatingInOrderTransform的分组算法如下:
假设有3个stream当前算子会维护3个Chunk,每一次选取在当前的3个Chunk内找到最后一条数据的最小值,比如初始状态最小值是5,然后将3个Chunk内所有小于5的数据一次性取走,如此反复如果一个Chunk被取光,需要从改stream内拉取新的Chunk。
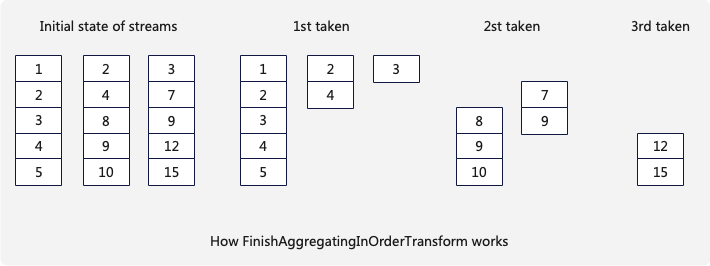
这种算法保证了每次FinishAggregatingInOrderTransform向下游输出的Chunk的最大值小于下一次Chunk的最小值,便于后续步骤的优化。
3.优化分析
打开optimize_aggregation_in_order后:主要对于第一阶段的聚合步骤进行了优化,从基于HashMap的算法到基于连续相同值的算法。
1.对于计算方面:优化后的算法,减少了Hash计算,但多了判断相等的步骤,在不同数据基数集大小下,各有优劣。
2.由于内存方面:优化前后无差别
3.对于poipeline阻塞:优化前后无差别
四、优化小结
在整个查询计划中Sort、Distinct、聚合这3个算子算子往往是整个查询的瓶颈算子,所以值得对其进行深度优化。ClickHouse通过利用算子输入数据的有序性,优化算子的算法或者选择不同的算法,在计算、内存和pipeline阻塞三个方面均有不同程度的优化。
审核编辑 黄宇
-
Pipeline
+关注
关注
0文章
29浏览量
10023 -
算子
+关注
关注
0文章
16浏览量
7415
发布评论请先 登录
MySQL数据库慢查询的排查思路和最佳实践
MySQL数据库慢查询分析与优化实战
MySQL慢查询分析与索引调优全流程
从0到1搭建实时日志监控系统:基于WebSocket + Elasticsearch的实战方案
订单实时状态查询接口技术实现

Hudi系列:Hudi核心概念之索引(Indexs)



评论