 算力基础设施的风险与挑战
算力基础设施的风险与挑战
编者按算力网络有一个美好的愿景,就是希望算力和算网,能像电力和电网一样:
- 算力可以标准化,有统一的计量单位。类似电力计量的千瓦时,或称为度数。
- 有很多算力中心生产算力,类似电厂生产电力。
- 生产出来的算力,通过接入算网,最终供应给算力的客户。类似电厂的电力,通过电网接入千家万户。
- 算力“随时随地,无处不在”,算力客户可以非常方便的随时接入任何位置的算力,支撑自己的业务。类似无处不在的电源接口,方便我们随时随地使用电力。
- 从基础设施的角度看,就是希望算力基础设施也能像电力基础设施一样,通过更大规模的人力物力投入,实现算力基础设施的领先。
但算力基础设施,和我们的能源、电力、交通等传统基础设施相比,仍存在许多风险和挑战。今天这篇文章,我们抛砖引玉。
1、算力基础设施战略价值巨大
本章节内容节选自《2022-2023全球计算力指数评估报告》,由IDC、浪潮信息、清华全球产业院。内容有调整。
通过数字技术推动业务变革,进而实现数字化转型,已经成为传统企业发展的必由之路。随着数字技术的不断进步和发展,以及数据量的爆发性增长,强大的算力,成为了创新和突破的关键要素。以人工智能领域为典型,人工智能大模型的发展,受算力发展的直接影响。人工智能算法和技术被应用于各种领域和行业(AI+),如自动驾驶汽车、医疗诊断、金融预测等。 算力的发展不仅激发数字技术的创新和突破,也推动了数字技术在各行各业的广泛应用与深度融合,为各行业能够实现科技创新提供了重要支撑。
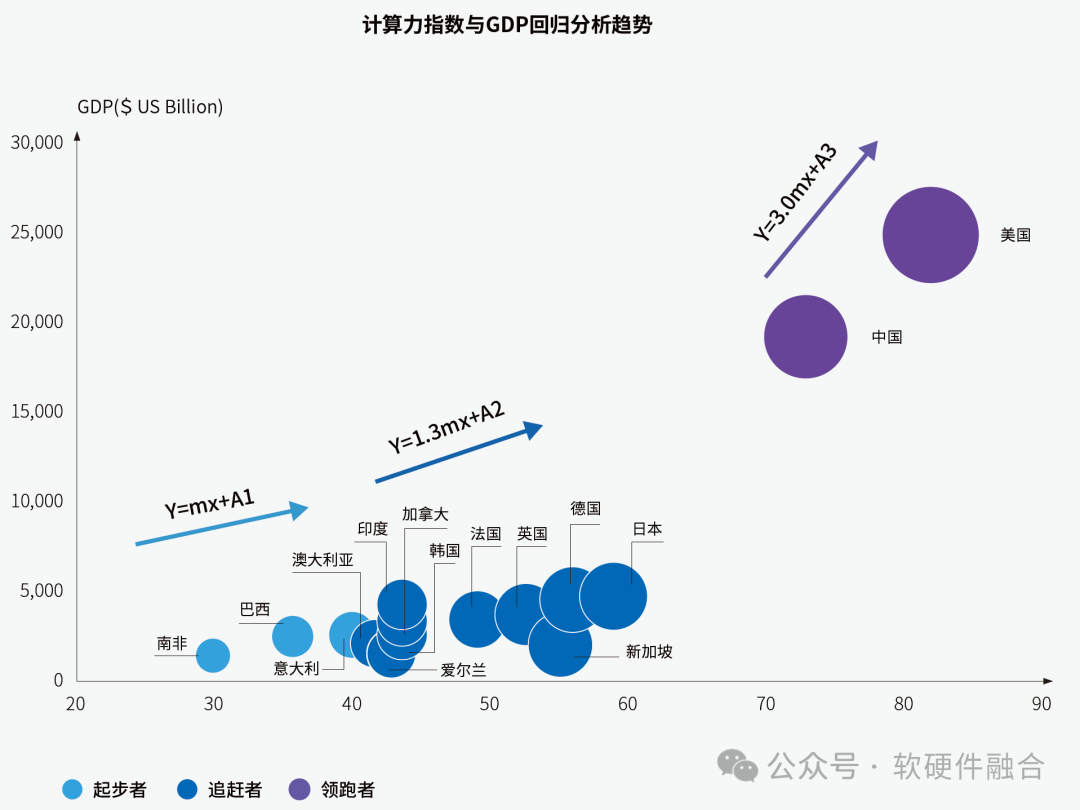
在数字经济时代,算力是国家经济增长的关键驱动力之一。根据上图可以看到,算力的提高对一国经济增长的拉动效应非常显著,且随着计算力指数的增加,提升效应会越来越明显。
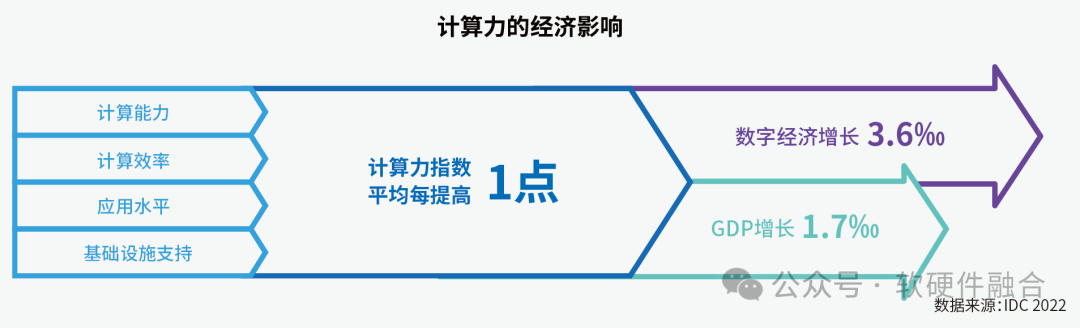
评估结果显示,十五个样本国家的计算力指数平均每提高1点,国家的数字经济和GDP将分别增长3.6‰和1.7‰。
总之,算力基础设施支撑并加速新质生产力和千行百业的发展,算力基础设施是整个国民经济发展的重中之重。
2、算力基础设施的风险和挑战
虽然算力和我们的铁路、公路、水利、电力等行业一样,被称为基础设施。但算力是新型基础设施,和这些传统基础设施相比,仍存在非常大的差异性。而这些差异性,也基本上就是算力基础设施存在的风险和挑战。
本章节,我们就算力基础设施的风险和挑战进行分析,无法面面俱到,仅限抛砖引玉。关于算力基础设施的风险和挑战,希望能够得到全行业的重视。全行业一起努力,能够构建符合技术和市场规律,并且能够支撑国家数字经济快速发展的新型算力基础设施。
2.1 算力难以标准化
如果算力可以公平且标准化的度量,那么算力就可以像电力一样,大规模生产和消费。但实际的情况,远比想象的要复杂的多。
我们通过两个案例进行分析。
首先是CPU处理器的案例。CPU是最通用的处理器,没有之一。我们以CPU中两个重要的部件进行分析:
- Cache,多核CPU中通常集成了L1-L3三级Cache。如果遇到流式数据处理,此刻Cache几乎没有价值;如果是循环等结构的业务算法,Cache的价值就非常大。反过来,流式数据处理,会优先选择Cache尽可能小一些的处理器;而循环类结构的业务算法,会优先选择大Cache的处理器。
- 协处理器,CPU内部也集成协处理器,如Intel AVX/AMX指令协处理器。如果是传统的控制类任务,就不需要AVX/AMX协处理器。但如果是视频、图像等任务,就需要AVX;如果是AI类处理,就需要AMX。反过来说,如果是控制类的任务,AVX/AMX协处理器对我来说没有价值,如果仍需要为这些协处理器的算力付费,则是相对不公平的。客户会优选没有AVX、AMX等协处理器的CPU处理器。
第二个案例,CPU vs 专用处理器。如果同样的1000TOPS算力(折合成TOPS统一单位),CPU算力和专用处理器的算力哪个更好?一般来说,CPU算力更好,因为CPU算力更加通用,可以用在几乎所有场景,并且对软件和软件开发者的要求更低。而专用处理器,仅能支持某个特定场景,甚至某个特定算法算力,对其他的业务场景来说,价值几乎为零。这样的话,这两种算力,能卖相同的价格吗?我们假设CPU 1000TOPS算力价格为1000元/月,那么,专用处理器 1000TOPS算力的价格10块钱,都不一定能找到合适的客户。
算力为什么难以标准化?本质的原因在于计算引擎和业务算法的耦合性。在加减乘数等基本指令的通用CPU基础上,做的任何优化,其实都是面向某些特定规律的计算或算法优化。这些加速计算引擎只有找到匹配的业务算法,才能发挥价值;反过来,如果没有匹配的业务算法,计算引擎的价值就很低很低。
简单总结如下:
- 一方面,计算引擎微架构的复杂性,决定了计算性能的测量是一件非常复杂、难以面面俱到并且足够公平的事情。
- 另一方面,计算的通用性,或者说对业务算法的广泛覆盖性,也是一个非常重要的维度。而这个维度,在算力计量之外。
- 此外,计算引擎和业务算法的耦合性,决定了算力的价值到底能发挥几何。计算引擎大体上可以分为三类:通用的CPU、并行计算的GPU等、以及专用加速的各种DSA/ASIC,这些计算引擎的算力无法完全按照算力来折算,而要根据算法和计算引擎的匹配,来计算实际算力。
- 那么,我们是否可以以业务算法为基准,谁能够更快速的完成一个特点单位的业务算法,谁的性能就好,谁的价值就高。答案也是否定的。因为业务算法千千万,单个业务算法无法评价,所有的算法加权综合评价也意义不大。对具体的业务客户来说,自己的算法能不能更快速更低成本的计算,才是需要关心的事情。
- 还有一个重要的方面,业务算法本身的价值。比如,同样的算力,如果用于AI计算,一般来说,价值要高一些。如果用于网络 存储计算,则价值要低一些。这些也会影响到专用加速器算力的价格定义。
- 等等。
总结一下,我们认为,计算是一件非常复杂的事情,算力(也即计算的能力)的标准化,几乎是一个伪命题。
2.2 业务的算力需求指数级增长
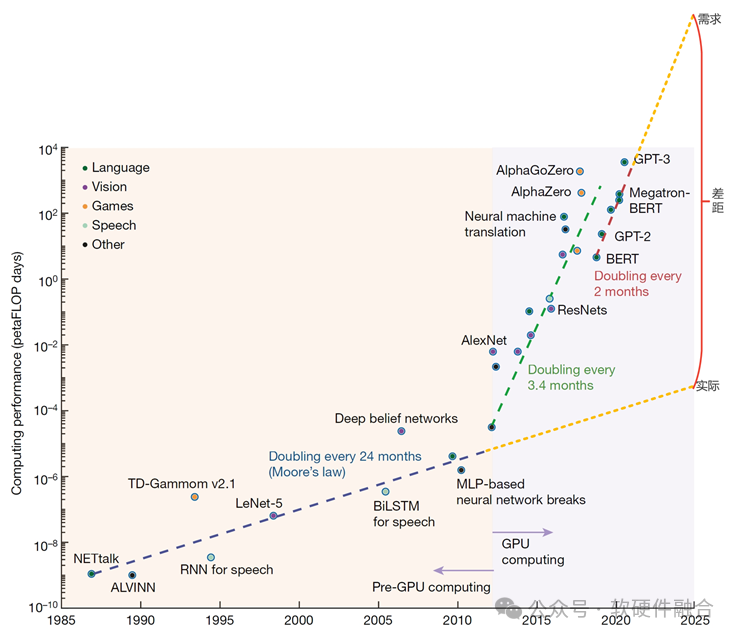 从上图可以看到,从2012年深度学习的兴起,算力需求逐渐增强,跳脱摩尔定律约束,需要GPU加速处理器,以及Scale out的集群计算。这一时期,算力需求每3.4个月翻倍。从2018年开始,随着大模型的流行,算力需求进一步加速,每2个月就会翻倍。与此同时,Scale Out也越来越难以为继,集群规模从千卡到万卡,再到十万卡。集群规模的不断扩大,使得AI计算的成本越来越成为天文数字。例如,微软与OpenAI制定的新一代AI算力芯片和基础设施项目星际之门,预计耗资1000亿美元;目标参数规模为1000万亿,是GPT4的10000倍。业务需求和算力基础设施的差距成指数级增长,两者之间的矛盾进一步加剧。要想根本性的解决问题,一方面需要单节点的计算架构的创新(Scale Up创新),也需要更高效的集群网络解决方案,进一步支持更大规模的集群计算(Scale Out创新)。
从上图可以看到,从2012年深度学习的兴起,算力需求逐渐增强,跳脱摩尔定律约束,需要GPU加速处理器,以及Scale out的集群计算。这一时期,算力需求每3.4个月翻倍。从2018年开始,随着大模型的流行,算力需求进一步加速,每2个月就会翻倍。与此同时,Scale Out也越来越难以为继,集群规模从千卡到万卡,再到十万卡。集群规模的不断扩大,使得AI计算的成本越来越成为天文数字。例如,微软与OpenAI制定的新一代AI算力芯片和基础设施项目星际之门,预计耗资1000亿美元;目标参数规模为1000万亿,是GPT4的10000倍。业务需求和算力基础设施的差距成指数级增长,两者之间的矛盾进一步加剧。要想根本性的解决问题,一方面需要单节点的计算架构的创新(Scale Up创新),也需要更高效的集群网络解决方案,进一步支持更大规模的集群计算(Scale Out创新)。
2.3 算力技术体系的门槛非常之高
算力涉及芯片、硬件及基础设施、软件以及业务四个主要的方案,每一项都非常的复杂,且有极高的技术门槛:
芯片,是计算(算力)的硬件载体。随着芯片工艺进入10nm以内,逐渐接近物理极限,芯片制造的门槛越来越高,一代新工艺投入通常在千亿美金级别。单芯片所能容纳的晶体管数量已经达到数百亿级,再加上Chiplet先进封装的加持,未来,单个芯片的晶体管数量会突破万亿级大关。这么庞大的晶体管数量,如果进行芯片的系统架构和微架构设计,也是非常大的挑战。
硬件设备和外围基础设施。在智算时代,硬件设备的功耗都非常的恐怖。传统CPU服务器单台功率在300W左右,而目前主流GPU服务器的功耗都达到了10KW左右,整整提升了30倍以上。于是,传统的风冷散热已经逐渐走出历史舞台,更高技术要求的液冷成为了主流。此外,数据中心的功耗越来越大,绿色数据中心越来越成为必然的要求。如何降低PUE,需要数据中心基础设施统筹的技术革新和综合能耗优化,甚至需要能源和电力产业的配合。
软件,是计算的灵魂。系统级软件如操作系统(如Linux)、集群操作系统(如Kubernetes),以及其他基础软件、数据库软件、中间件软件,以及加速计算框架、业务框架等等,软件生态五花八门。每一项都非常的复杂,每一项其生态的形成都经过了漫长而艰难的阶段。
业务。新的技术、新的场景、新的业务落地,有非常大的难度。特别是跟硬件关联度非常大,受硬件物理条件的约束的场景,如自动驾驶智能汽车、XR元宇宙、人形机器人等。如何实现软硬件深度协同和融合的综合算力技术体系,受到很多现实的约束,实现的难度巨大,需要更多的创新驱动。
总之,从算力芯片,到硬件以及相关软件和开发框架,软硬件体系极度庞大和复杂,技术门槛非常高。
2.4 算力技术迭代很快
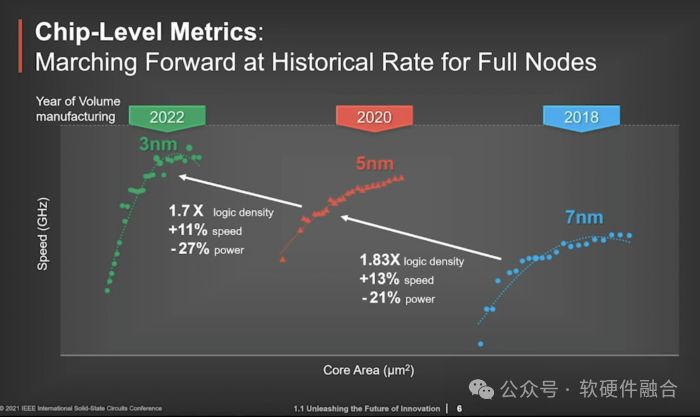
TSMC 3nm工艺已经量产,2nm、1nm也都在未来几年的路线图中。并且,TSMC已经开始在攻关0.1nm工艺,半导体工艺即将进入亚纳米(埃米)时代。在存储领域,近些年来还兴起了3D封装技术,使得集成电路从二维进入三维。在封装领域,Chiplet先进封装机制,把多个芯片裸DIE集成到一起,从3D到4D,都进一步增强了单位面积的晶体管集成度。
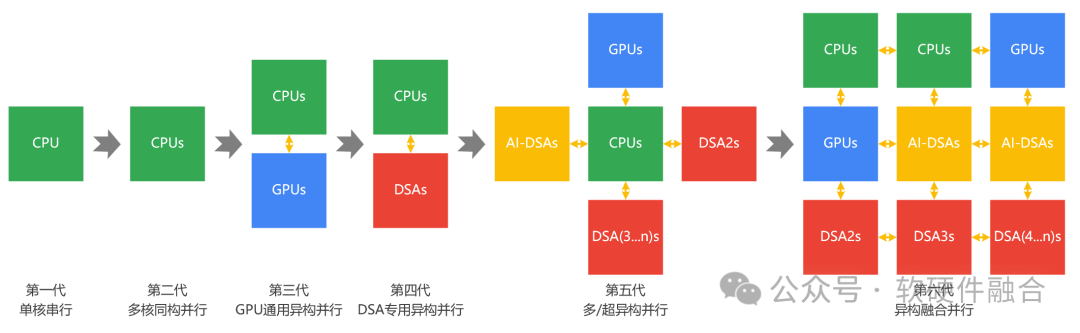
随着单芯片所能容纳的晶体管数量逐渐增加,计算的架构也越来越复杂,逐渐从CPU同构、CPU+GPU的异构,走向了CPU+GPU+DSAs的异构融合。2023年9月15日,在湖南长沙的世界计算大会上,《异构融合计算技术白皮书》由工信部电子五所发布(关注软硬件融合公众号,回复“白皮书”,可下载此白皮书)。

算力芯片的设计模式,已经从“硬件定义软件”转向“软件定义硬件”。传统的算力芯片设计模式,是先有芯片,然后是驱动和开发框架,再然后是基于框架的软件任务。但这种方式,每家芯片公司都是一个独立的架构,独立的生态。一方面,构建生态的门槛非常高,另一方面,这种方式对客户非常不友好。特别是在计算的主流方式从单机走向大规模集群计算的当下,客户既倾向于统一的计算平台,又不想被特定的厂家绑定。软件定义硬件的方式,是客户和芯片供应商最大的公约数。
这里就计算的形态再做进一步展开。随着大模型的发展,计算需求的规模越来越大,和单颗芯片所能提供的性能差距的数量级,也在不断增加。千卡集群、万卡集群,甚至十万卡、百万卡集群也已经在路上。超大规模集群计算,甚至跨云边端的融合计算,已经成为了计算的主流形态。
摩尔定律告诉我们,每18-24个月芯片的性能就会翻倍。NVIDIA黄仁勋的黄氏定律告诉我们,计算性能会每一年翻一倍。这两个定律意味着,算力芯片的迭代周期是1-2年一代。
软件的迭代就更快了,软件开发更是讲究“小步快跑”,通常是2-3个月一个小迭代,一年一个大迭代,不然就赶不上业务快速发展的需要。
2.5 算力基础设施的生命周期非常短
传统基础设施,技术更新换代较慢,传统基础设施的生命周期很长,通常在50年以上,有的甚至100年以上。
而受算力各项技术的快速更新迭代,特别是摩尔定律和黄氏定律的影响,算力基础设施的生命周期通常4-5年。因为,4-5年时间之后,硬件的可靠性会越来越差,并且计算的各项支出越来越不够经济,必须要更换更加先进的计算设备和相应的软硬件技术栈。
3、开放的技术栈,开放的产业链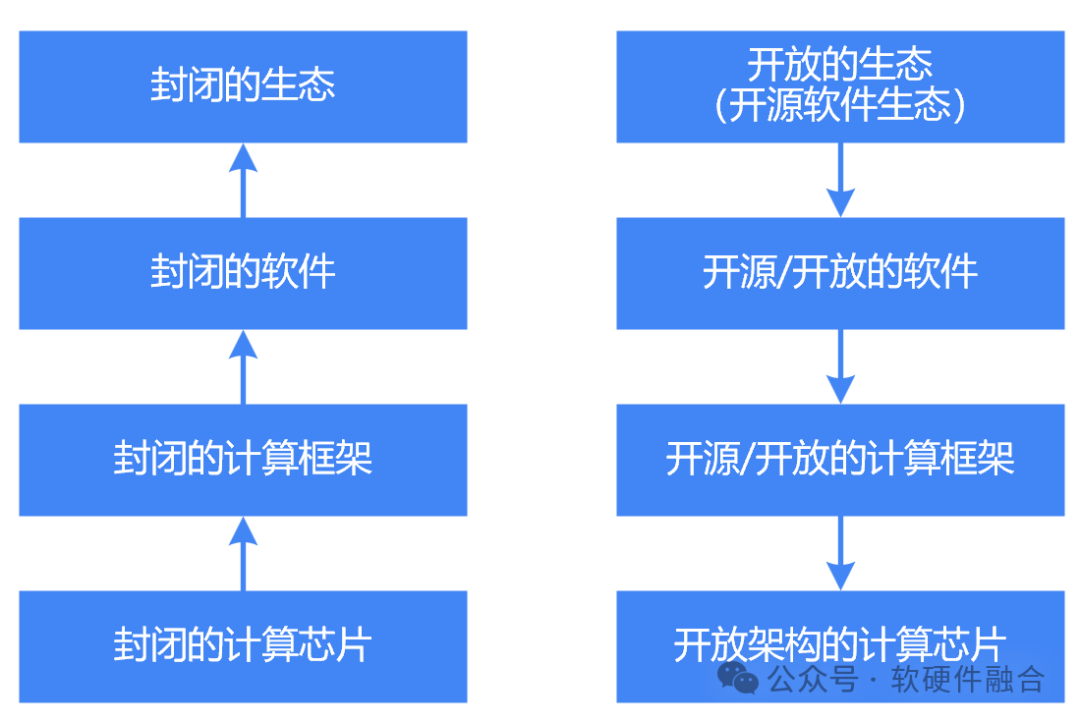
国产算力芯片最大的困境在于生态:构建一个新的计算生态,门槛非常高,千亿级投入都不一定成功。但行业除了NVIDIA CUDA生态之外,还有一个更加强大的生态,即全球几乎所有互联网公司(客户)都支持的开源软件生态。基于开源软件,实现开源软件定义的开放硬件,形成一个更加开放更加强大的开源的技术(栈)生态。
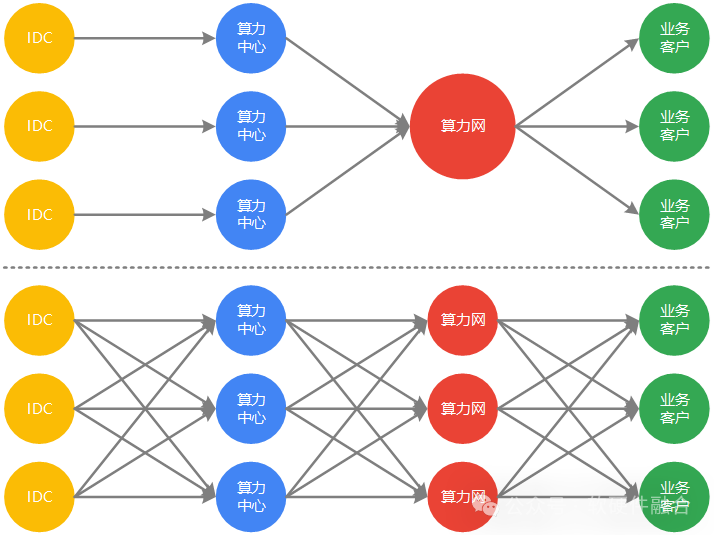 国家多个部委发文,说要构建全国一体化算力网。但一体化算力网,并不意味着是一家公司独大,而是意味着算力的充分利用和价值的最大化发挥。我们认为,未来也是类似公有云的竞争态势,最终形成5家左右具有全国甚至全球影响力的算力网公司,以及10家以上具有行业和领域特色的专业算力网公司。总之,整个产业链是开放的:
国家多个部委发文,说要构建全国一体化算力网。但一体化算力网,并不意味着是一家公司独大,而是意味着算力的充分利用和价值的最大化发挥。我们认为,未来也是类似公有云的竞争态势,最终形成5家左右具有全国甚至全球影响力的算力网公司,以及10家以上具有行业和领域特色的专业算力网公司。总之,整个产业链是开放的:
IDC,聚焦数据中心的基础设施;自身的基础设施可以服务公有云和算力中心等各类客户。
算力中心,聚焦算力生产。通过融合计算的综合算力创新优化,实现算力的最高性能和最低成本,以及超大规模。算力可以卖给任何一家算力网公司,以及直接卖给大客户。
算力网,聚焦业务落地。主要聚焦PaaS服务和算力解决方案,服务好客户业务落地。
业务客户,可以从自建的私有云、公有云以及算力网获得优质而低成本的且“无处不在,随时随地可获取”的算力,服务好自身的业务。
只有开放,才能最大限度的发挥各自的创造力和和市场竞争价值,才能最大限度的实现技术的快速进步,才能实现算力芯片和算力产业链的独立自主,甚至全球领先。
在线研讨会 | 深入了解Imagination APXM-6200:全新性能密集型应用CPU
-
电网
+关注
关注
13文章
2073浏览量
59190 -
人工智能
+关注
关注
1791文章
47294浏览量
238576 -
算力
+关注
关注
1文章
982浏览量
14824
发布评论请先 登录
相关推荐
企业AI算力租赁模式的好处
智算中心崛起:数字化时代的新核心基础设施

中金数据乌兰察布零碳算力基地首批算力机房验收交付

AI驱动下的数字经济:智能社会基础设施与算力革新
IaaS+on+DPU(IoD)+下一代高性能算力底座技术白皮书
中科驭数:DPU是构建高效智算中心基础设施的必选项
联想全栈算力基础设施发布 跻身中国第一阵营再启新程








 工商网监
工商网监
评论