 利用大模型服务一线小哥的探索与实践
利用大模型服务一线小哥的探索与实践
一、小哥作业+大模型
2022年OpenAI基于GPT推出了聊天机器人ChatGPT,带来了非常惊艳的语言理解、内容生成、知识推理等能力,能够准确理解人的语言、意图,并能够回答出清晰、完整的内容,让人很难分辨出沟通交流的是人类还是机器人。
大模型会尝试基于已有的内容,生成内容的延续。基于预训练阶段加入的海量文章、电子图书、网页内容等等,大模型给出最接近我们期望的内容。比如我们提供的内容是“北京是...”,大模型扫描海量内容进行排名,为了让内容更有创造力,大模型使用了巫术,一般采用基于可配置参数(top K, top P, Temperature) 的概率随机采样来选择单词,而不是总采用排名最高的单词。通过延续生成了“北京是一座充满活力的城市”。人类反馈强化学习(RLHF)即基于人类反馈对大语言模型进行强化学习,通过人工标注来构建奖惩网络,强化学习基于奖惩网络对模型进行迭代优化,改善生成内容的质量。
快递快运终端系统是快递小哥、快运司机、网点管理者日常使用的系统,是物流作业人员最多、作业流程最末端、服务形态最多元的系统。大模型带来了新的方法来解决小哥提出的问题、遇到的异常、需要的支持,并提供帮助网点管理者进行运营和经营管理的工具。
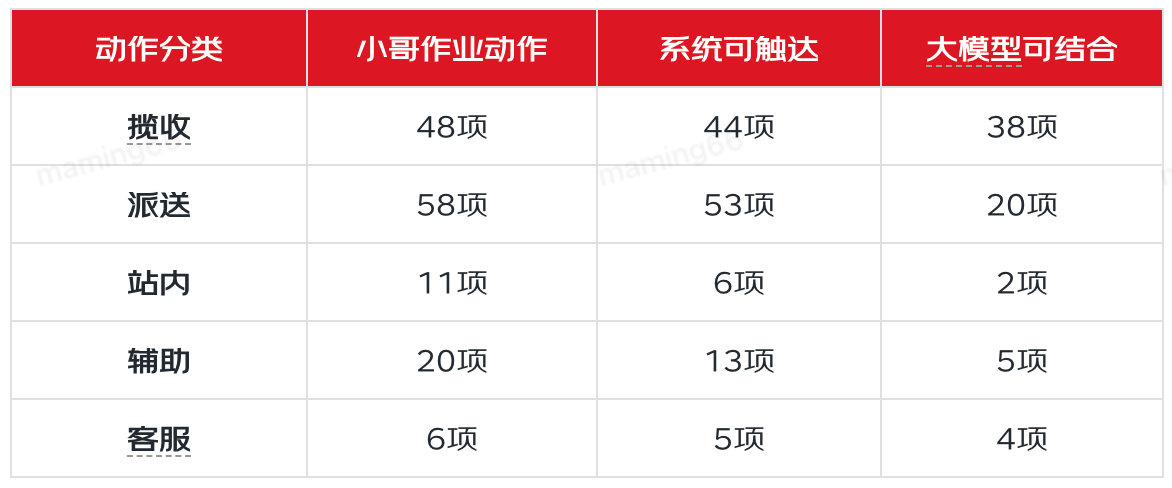
提升小哥作业效率,就需要了解小哥日常工作中有哪些作业动作,然后根据作业动作的特点,来分析大模型有什么样的机会来实现效率提升。通过调研和分析,小哥有143项作业动作,可分类为:揽收、派送、站内、辅助、客户服务五大类,其中22项动作是系统外的线下动作,其他动作中有69项被认为有大模型结合的机会。在69项中我们选取了小哥揽收信息录入、外呼、发短信、查询运单信息、聚合查询、知识问答、精准提示等场景,通过大模型与大数据、GIS、语音等技术的结合,为小哥提供高效、易用的作业工具。
二、智能操作
小哥日常作业中,会频繁给客户打电话、发短信。出于客户个人隐私安全的考虑,面单中隐藏了电话,所以外呼前需要小哥一次次在系统中查找电话,经常是扫单号、在详情页点击外呼按钮、拨打电话等一系列动作。通过小哥语音,大模型可以帮助我们分析小哥的意图,识别出拨打电话,就可以通过语音中提到的运单尾号、地址等特征完成外呼。
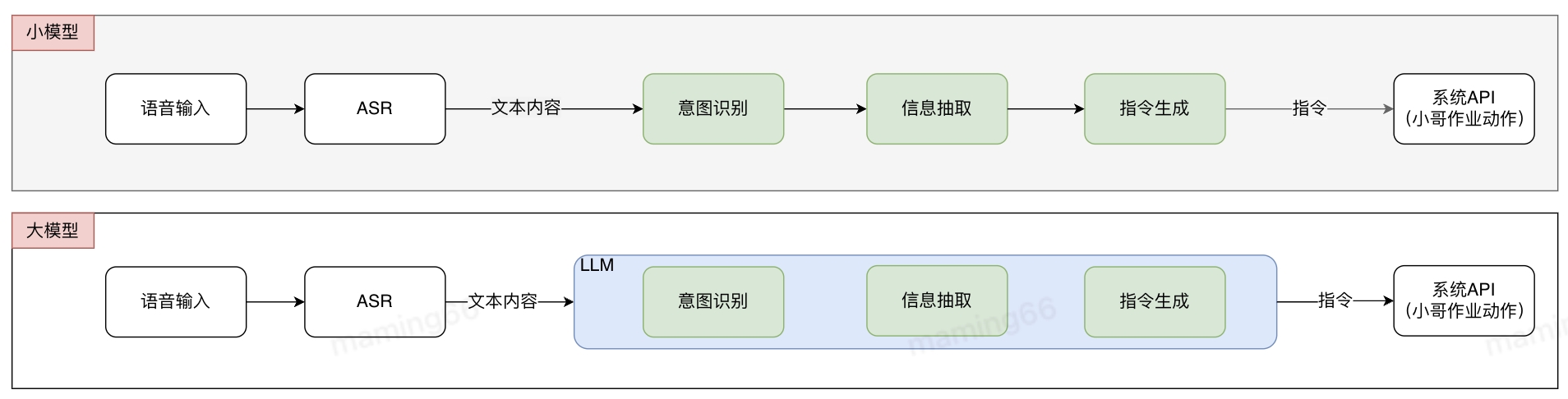
基于常规算法的解决方式是多个小模型组合成pipline,各小模型分别进行标注和训练,pipline存在误差传递问题。使用大模型后,不需要进行标记和训练,可以直接投入使用,减少了算法开发的难度和周期,提升研发交付效率。在接收到小哥语音输入后,语音识别(ASR)将语音转化为文字,文字通过大模型意图识别、信息抽取等方式生成指令,并调用系统API实现作业功能。
小哥智能助手中智能操作的实现方法如下:
在小哥发短信时,需要查找电话,在短信界面编辑文字,通过语音+大模型,识别小哥需要给客户发短信,并通过大模型对短信内容进行再加工,完成正式的短信编写。
在填写揽收信息时,小哥需要频繁切换电子称、卷尺、工业机来完成称重量方和信息录入等作业动作,同时揽收还需要填写托寄物、时效产品、增值服务等内容,如果通过语音+大模型,就可以减少工业机的多次输入,会直接识别语音,分析出小哥的输入意图和内容,将信息正确填写。
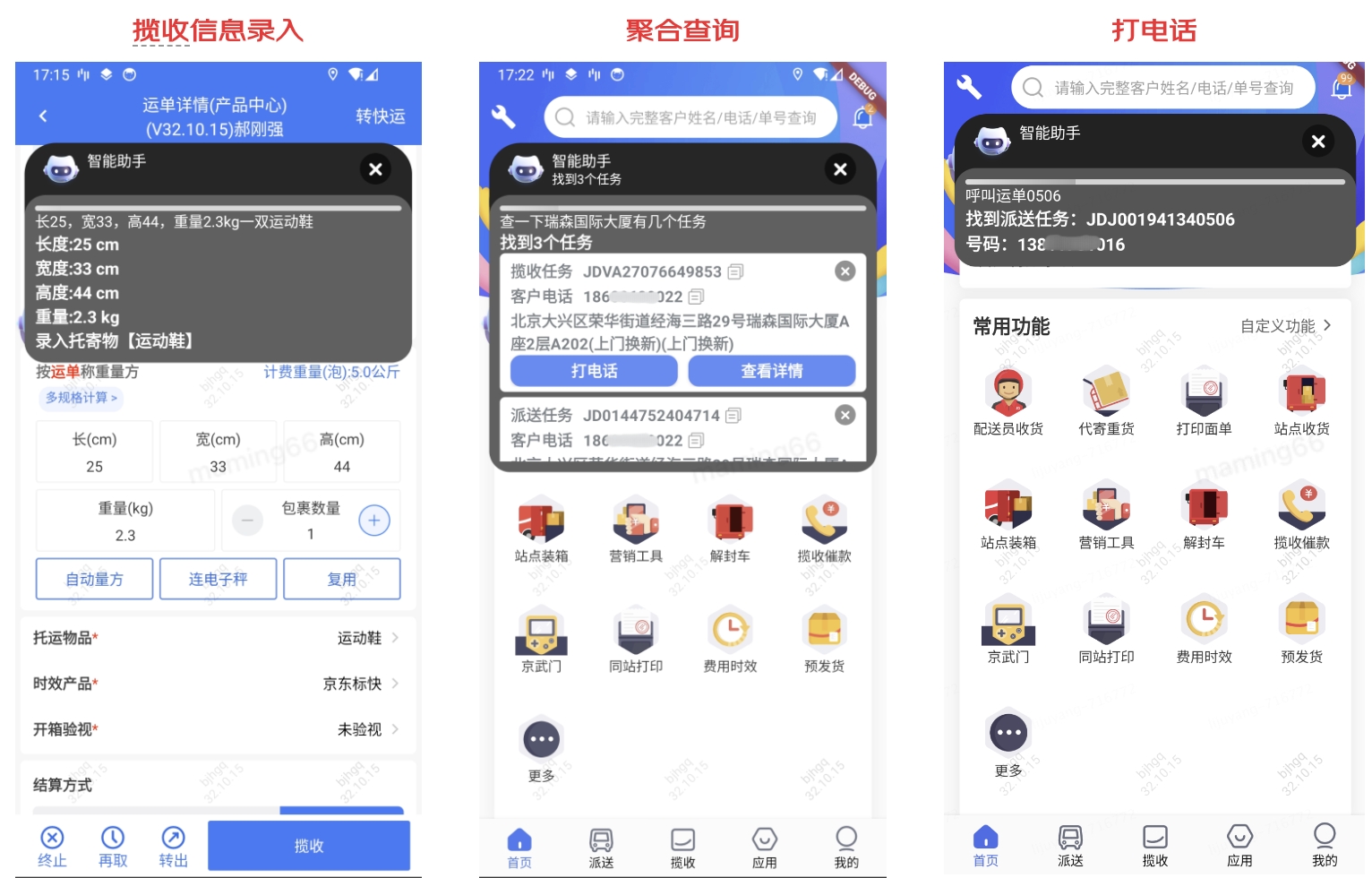
小哥查询信息,也可以通过语音输入,大模型识别意图,进行结果的反馈。如下是通过大模型实现的意图识别示例:

三、智能问答
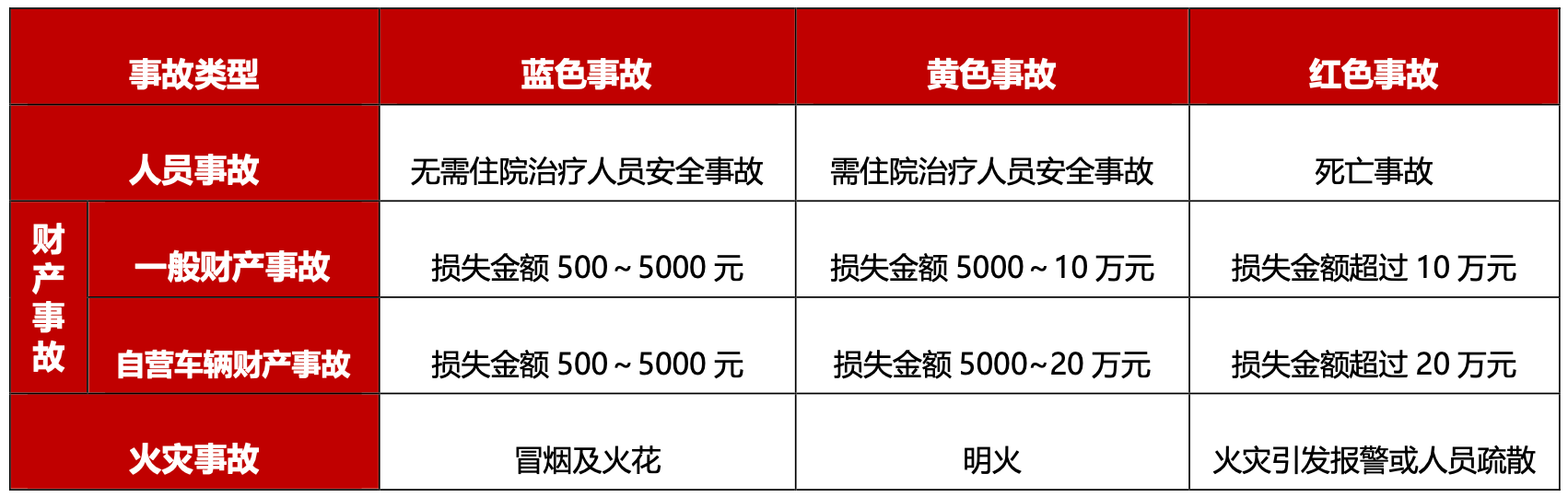
业务快速发展的同时,也对小哥作业提出了非常高的要求,据不完全统计,仅终端相关文件就有915个,如货物处理规程、安全操作标准、KA客户服务要求等等。对于小哥来说,记忆并掌握这么多业务要求无疑是一项巨大的挑战,小哥对标准作业流程或规范了解不全面,会影响服务质量,也会影响一线作业效率,造成时间和成本浪费。
小哥不了解流程、规则或者遇到运营问题,目前通过问站长/站助/其他小哥、提报IT工单、联系终端小秘等方式解决,但是被咨询人也会因为对业务规则、流程了解不全面而无法给出正确的回答。大模型出现后能够更清晰的理解小哥的问题和意图,提供更加简洁的回答,提高回答的准确率,降低了小哥的理解成本。
通过Prompt+检索增强生成(RAG)实现了第一阶段的智能问答。之所以需要检索增强生成是因为大模型目前存在幻觉、知识过时等问题,RAG实现从外部知识库中检索相关信息进行回答,提高答案的准确性。
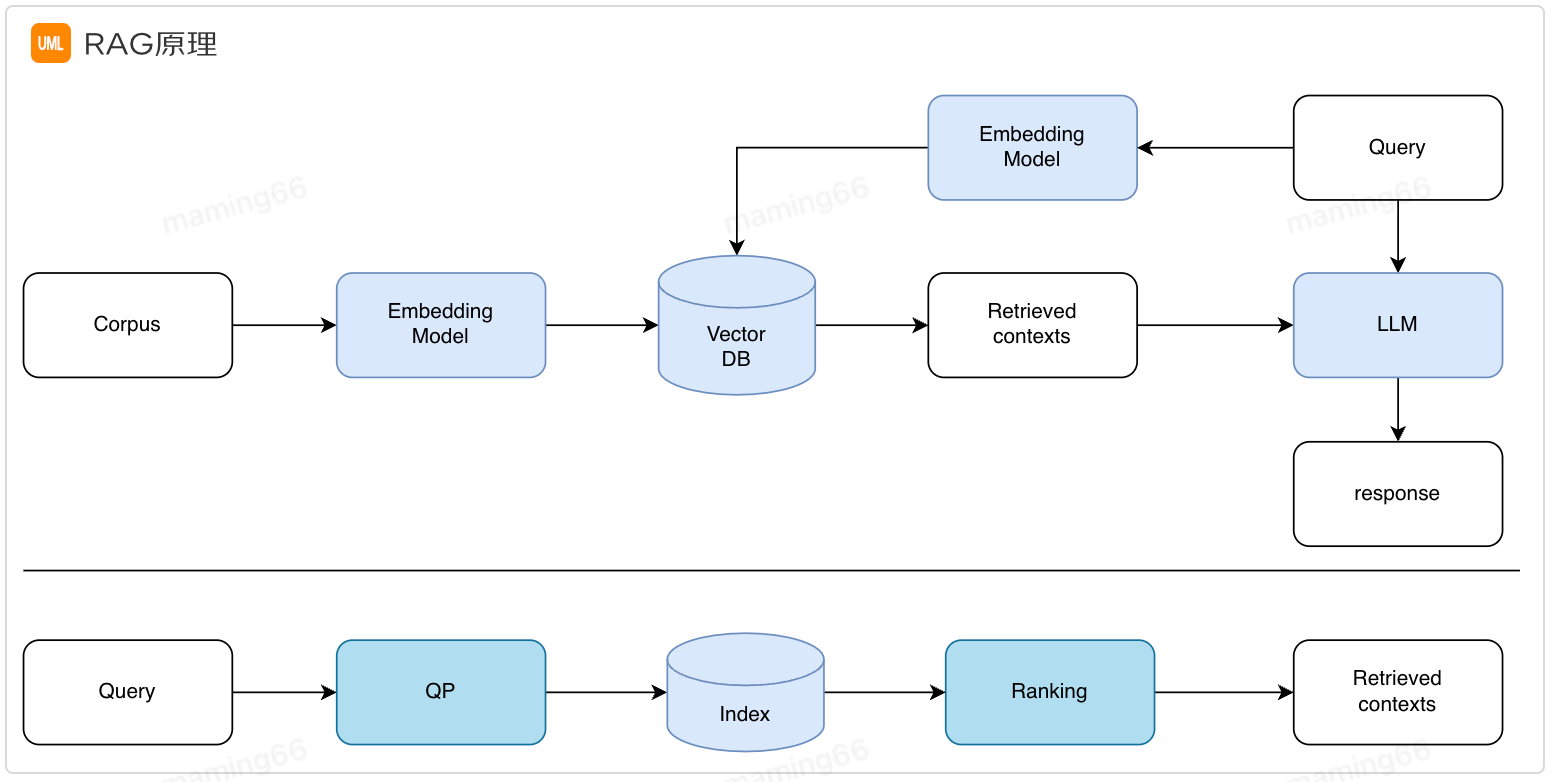
小哥智能助手中智能问答的实现方法如下:
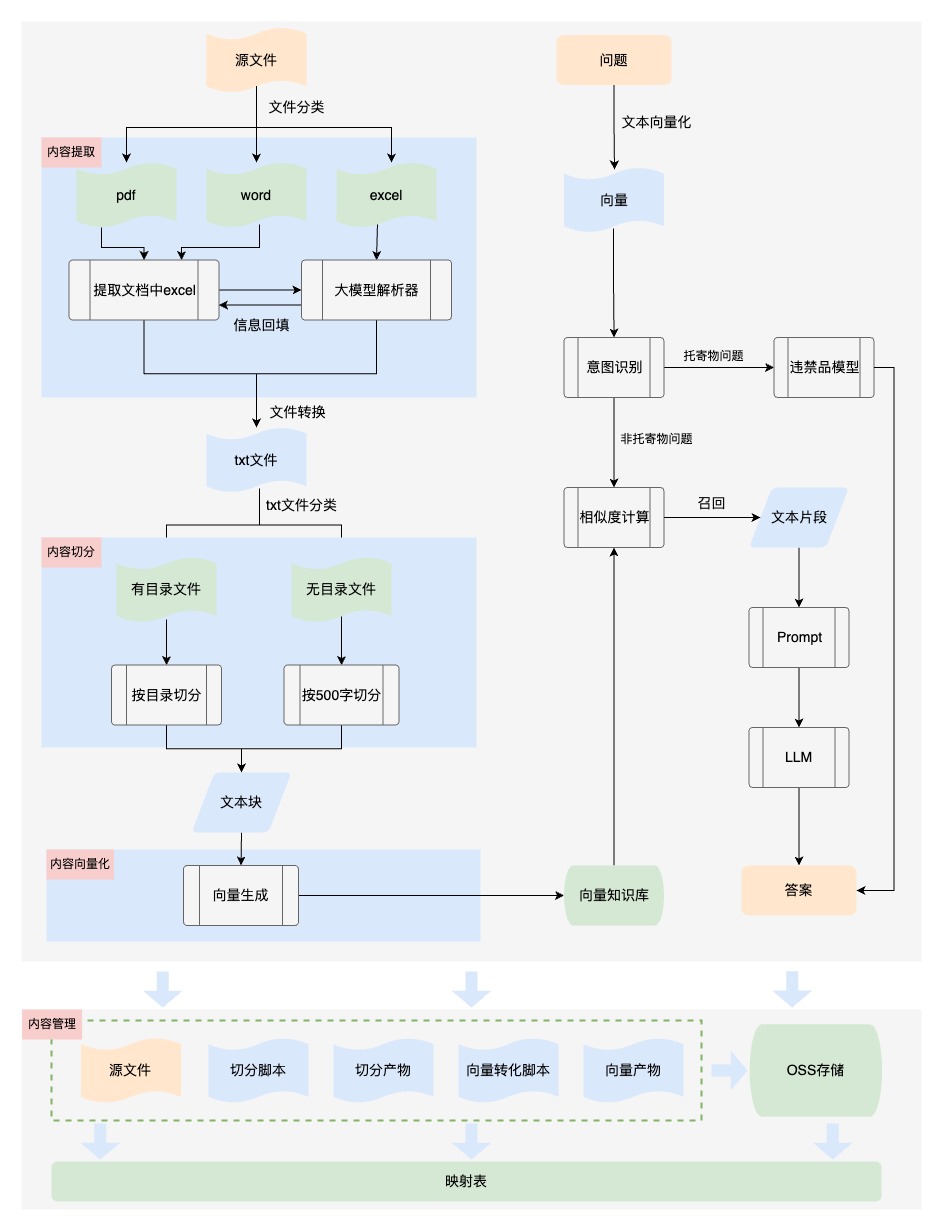
【内容提取】业务文档格式多样,也包含各种内容元素,比如包含表格的文档,只进行文字提取,无法保证内容的结构性、可读性,输入给大模型后无法理解,导致回答不准确。所以我们对文件内容进行提取时,将文件中的表格转换为语义化的内容,保证知识的可读性。如下是业务文档中的表格内容:

【内容切分】大模型能够找到的相关知识的质量和数量决定了回答的正确性和完整性,但是由于大模型token的数量限制,我们必须将文档内容切分。最初我们设置300个字符为一个知识块进行切分,从回答的效果上看,有很多问题回答的内容不完整,因为单纯的按照字数切分会破坏内容的完整性,需要引入段落切分,保持段落完整性。

具体实现方法如下:
a. 内容提取
第一版采用了DocumentLoaderUtil直接提取文本,将文本信息存入txt文件,具体实现方式如下:
from src.document_loader.document_loader import DocumentLoaderUtil processor = DocumentLoaderUtil(file_path=path_ori, pic_save_dir=dir_save_picture) texts = processor.load() texts = json.dumps(texts, ensure_ascii=False, indent=4) with open(os.path.join(dir_save_text, f"{os.path.basename(path_ori)}.txt"), "w") as f: f.write(texts)
优化后处理DOCX文件:
1.读取文档信息时,遇到表格,将表格单独存储到excel中,并在文本中使用特殊占位符标注表格位置;
2.结合大模型对表格进行语义化处理,使表格信息转化成语义化文本;
3.根据特殊占位符将语义化文本回填至文档对应位置;
# 提取word中的表格 def extract_tables_to_excel(docx_path, excel_result_path): doc = Document(docx_path) docx_name = os.path.splitext(os.path.basename(docx_path))[0] folder_path = os.path.join(excel_result_path, docx_name) if not os.path.exists(folder_path): os.makedirs(folder_path) table_count = 0 for table in doc.tables: table_count += 1 data = [[cell.text for cell in row.cells] for row in table.rows] df = pd.DataFrame(data) # 保存DataFrame到Excel文件 excel_path = os.path.join(folder_path, f"【表格{table_count}】.xlsx") df.to_excel(excel_path, index=False, header=False) return folder_path # 根据占位符插入表格内容 def replace_marker_in_txt(file_path, marker, replacement_text): # 读取原始文件内容 with open(file_path, 'r+', encoding='utf-8') as file: content = file.read() if replacement_text is None: replacement_text = '' # 替换特定标记 content = content.replace(marker, replacement_text) file.seek(0) file.write(content) file.truncate() # txt中插入表格 def insertTable(folder_path, txt_path): for filename in os.listdir(folder_path): filepath = os.path.join(folder_path, filename) filename_without_extension, _ = os.path.splitext(filename) # 处理表格为语义化文本 result = excel_to_txt_single(filepath) # 占位符替换处理后的文本 replace_marker_in_txt(txt_path, filename_without_extension, result)
优化后处理PDF文件:
1.读取文档信息提取表格,结合大模型对表格进行语义化处理,使表格信息转化成语义化文本;
2.寻找表格内容并替换内容;
# 处理pdf
def process_pdf(file_path, file_name, output_directory, save_directory, txt_file):
individual_file_names = save_pdf_tables_to_excel(file_path, file_name, output_directory)
content = DocumentLoaderUtil(file_path, save_directory).load()
content = [doc['page_content'] for doc in content]
with open(txt_file, 'w', encoding='utf-8') as f:
for line in content:
f.write(line + 'n')
replace_similar_module_in_txt(individual_file_names, txt_file, file_path)
# 特殊pdf二次处理
def handle_exception(extension, file_path, file_name, output_directory, save_directory):
try:
if extension == '.pdf':
individual_file_names = save_pdf_tables_to_excel(file_path, file_name, output_directory)
text, txt_file = convert_pdf_to_txt(file_path, os.path.join(save_directory, 'txt'))
else:
return
with open(txt_file, 'w', encoding='utf-8') as output_file:
output_file.write(text)
replace_similar_module_in_txt(individual_file_names, txt_file, file_path)
except FileNotFoundError as e:
with open('error.md', 'a') as file:
file.write(f"文件未找到错误:{file_path}n")
except Exception as e:
with open('error.md', 'a') as file:
file.write(f"handle_exception处理异常时发生错误:{file_path}n")
# 查找表格位置并替换为语义化内容
def replace_similar_module_in_txt(individual_file_names, txt_file, file_path):
# 读取文本文件的原始内容
with open(txt_file, 'r', encoding='utf-8') as file:
txt_content = file.read()
for excel_path in individual_file_names:
excel_content = read_excel_content(excel_path)
# 查找最相似的片段
most_similar_part = find_most_similar_part(txt_content, excel_content, threshold=0.02)
if most_similar_part:
# 替换成语义化文本
replacement_text = excel_to_txt_single(excel_path)
txt_content = safe_replace(txt_content, most_similar_part, replacement_text)
else:
# 找不到时 将内容追加到文档后
replacement_text = excel_to_txt_single(excel_path)
txt_content += replacement_text
with open(txt_file, 'w', encoding='utf-8') as file:
file.write(txt_content)
b. 内容切分
第一版按照字符数切分,固定300字符+15%的滑动窗口。核心代码如下:
from src.text_splitter.text_splitter import TextSplitterUtil
splitter_name = "RecursiveCharacterTextSplitter"
splitter_args = {
"chunk_size": 300,
"chunk_overlap": round(300 * 0.15),
"length_function": len,
}
splitter = TextSplitterUtil(splitter_name, splitter_args)
with open(os.path.join(dir_save_text, f"{os.path.basename(path_ori)}.txt")) as f:
texts = json.load(f)
texts_splitted = splitter.create_documents(
texts=[t["page_content"] for t in texts],
metadatas=[{"source": f"{path_ori}_{ti}"} for ti, t in enumerate(texts)],
)
print(texts_splitted)
优化后按照段落+500字符+10%的重叠进行切分。经过测试回归发现,效果明显提升。
import os
import json
import re
import csv
# 按优先级顺序存储正则表达式
def find_all_matches(doc, patterns):
last_end = 0
matches = []
# 搜索所有的匹配项
for pattern in patterns:
for match in pattern.finditer(doc):
start, end = match.span()
# 如果当前匹配块前有未匹配的内容,则将其作为单独的匹配块
if start > last_end:
matches.append(doc[last_end:start])
matches.append(match.group())
last_end = end
if last_end < len(doc):
matches.append(doc[last_end:])
return matches
def trim_regex_title(path_ori):
with open(path_ori, 'r', encoding='utf-8') as file:
document = file.read()
# 使用非贪婪匹配 .*? 来捕获标题后的内容,直到遇到下一个标题或文档末尾
# 初始化 matches 为空列表,用于存储找到的匹配项
# 按优先级顺序存储正则表达式
patterns = [
re.compile(r'((?:一、|二、|三、|四、|五、|六、|七、|八、|九、|十、|d+.)[^n]+)([sS]*?)(?=n(?:一、|二、|三、|四、|五、|六、|七、|八、|九、|十、|d+.)[^n]+|$)'),
re.compile(r'(n.+?)(?=n.+|$)'),
re.compile(r'(?s)(nd+.d+s+.*?)(?=nd+.d+s+|$)')
]
matches = find_all_matches(document, patterns)
page_contents = []
for match in matches:
section_content = match.strip()
page_contents.append({
'page_content': section_content,
'metadata': {
'source': path_ori,
},
})
# 组装成500字
# 创建一个空列表用于存储处理后的page_checks
page_checks = []
# 用于累积不足500字符的内容
accumulated_content = ""
for page in page_contents:
page_content = page['page_content']
# 如果当前行内容加上累积的内容超过500字符,则需要分割
if len(accumulated_content) + len(page_content) > 500:
# 如果之前有累积的内容,先处理
if accumulated_content:
page_check_dict = {
"page_content": accumulated_content,
"metadata": {"source": path_ori}
}
page_checks.append(page_check_dict)
accumulated_content = ""
# 处理当前行的内容
start_index = 0
while start_index < len(page_content):
end_index = min(start_index + 500, len(page_content))
page_check_dict = {
"page_content": page_content[start_index:end_index],
"metadata": {"source": path_ori}
}
page_checks.append(page_check_dict)
# 更新start_index以便获取下一个500字符的片段,与前一个片段有50字符重叠
start_index += 450
else:
# 如果当前累积内容与新行内容总和不超过500字符 继续累积内容
if len(accumulated_content) + len(page_content) < 500:
accumulated_content += page_content
else:
# 累积内容已足够,创建一个page_check
page_check_dict = {
"page_content": accumulated_content,
"metadata": {"source": path_ori}
}
page_checks.append(page_check_dict)
accumulated_content = page_content
# 处理文件末尾的累积内容
if accumulated_content:
page_check_dict = {
"page_content": accumulated_content,
"metadata": {"source": path_ori}
}
page_checks.append(page_check_dict)
return page_checks
c. 向量化 Embedding
用户的问题往往非常口语化,而文档和知识往往都是非常的专业和正式。比如用户的问题是:“我去年已经离职了,现在自己干,如何交公积金?”。从文档中需要检索出“灵活就业人员”办理公积金的材料和流程。内容检索只能进行精确匹配,对于近义词、语义关联词的检索效果较差。文本向量化后,搜索就可以通过计算词语之间的相似度,实现对近义词和语义关联词的模糊匹配,从而扩大了搜索的覆盖范围并提高了准确性。Embedding 就是将这些离散的文本内容转换成连续的向量。我们将向量存储到Vearch库中,选择相似度top9的向量对应的内容文本输入给大模型,通过Prompt进行回答。
from src.embedding.get_embedding import get_openai_embedding
model_key = "xxxx"
model_name = "text-embedding-ada-002-2"
texts_embedding = [
get_openai_embedding(
text=t.page_content, model_name=model_name, model_key=model_key
)
for t in texts_splitted
]
d. 内容管理
我们为向量创建索引,以便于检索和更新,同时将各阶段产物包括源文件、切分脚本、切分文本块、向量嵌入脚本、向量存储通过oss进行管理,并建立映射表。当业务知识进行更新时,可以对向量库中的内容进行更新替换。

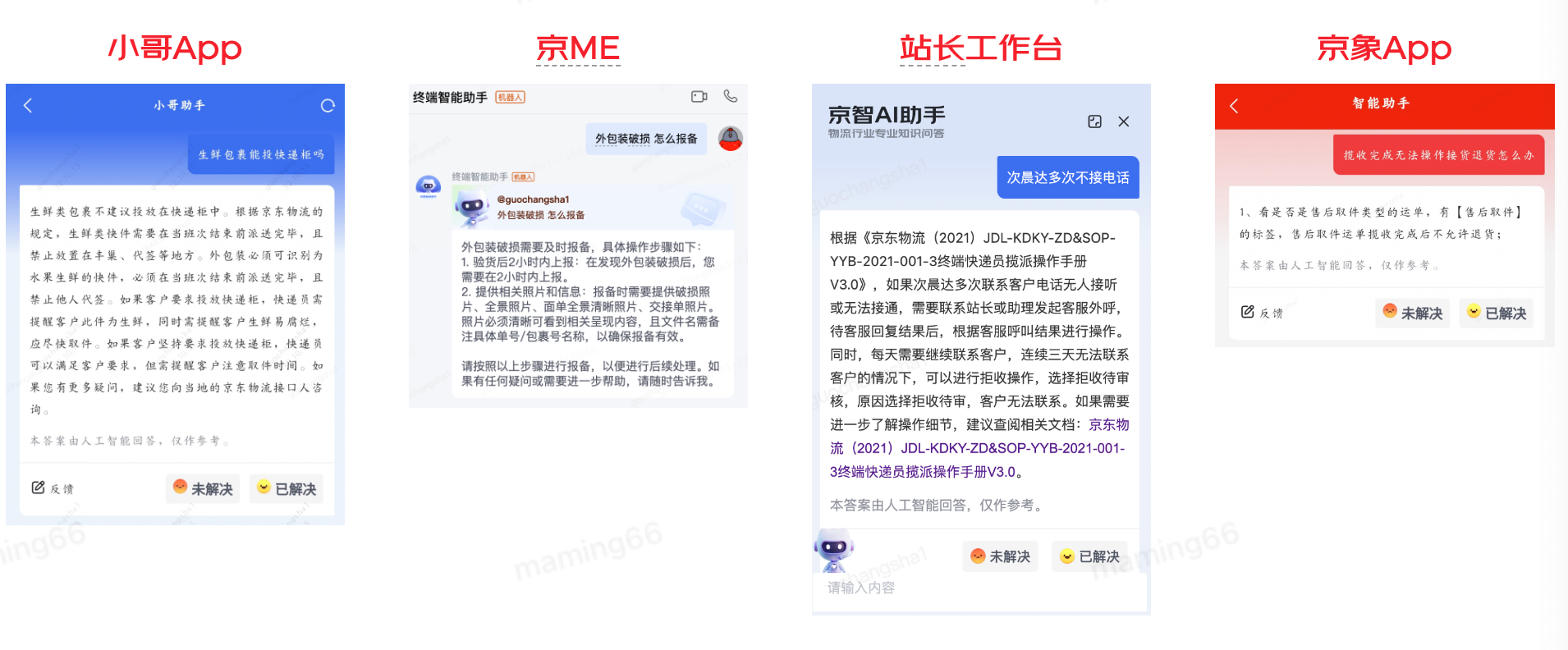
通过持续优化智能问答准确率90%,目前已接入小哥App、京ME、站长工作台、京象App等,功能如下:
四、智能提示
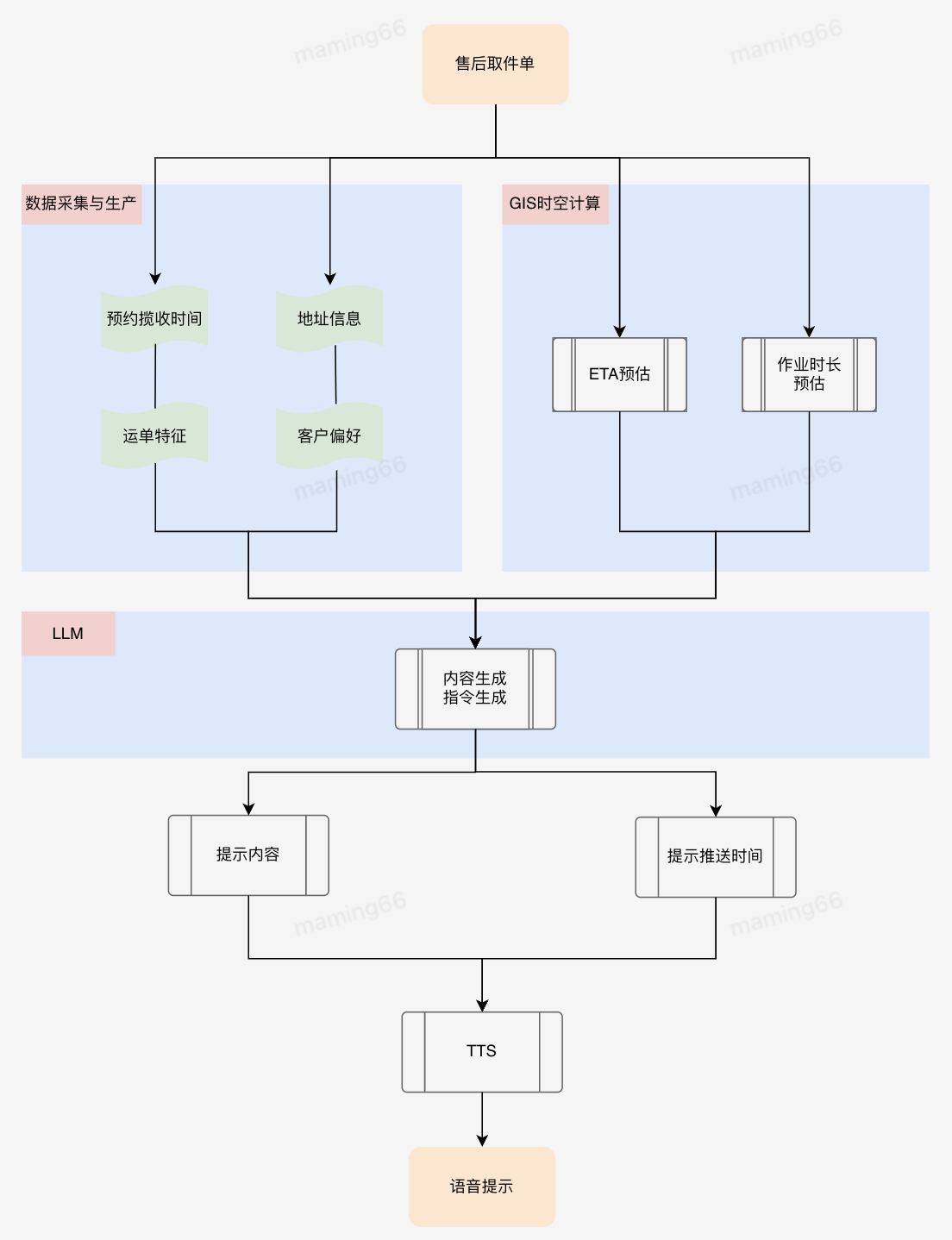
小哥作业流程规范,以及履约中的时效预测和提醒等等,都可以使用大模型将复杂的业务文档和流程规范转化为小哥容易理解和执行的操作提示,在任务下发、临期提醒方面也可以发挥大模型的理解和总结能力,使小哥关注到最需要关注的信息,帮助小哥做进一步的作业决策。比如KA商家对揽收打包方式、交接方式有各自不同的定制化需求,如果通过小哥记忆或者查资料的方式了解揽收打包要求,非常麻烦且耗时,利用大模型总结KA商家操作要求,通过语音合成(TTS)引导小哥按照客户要求作业,能够提升业务的履约质量。

小哥智能助手中智能提示的实现方法,以售后取件单下发为例:
提示的差异对比如下:

五、智能体
以GPTs为代表的大模型智能体带给了人们非常震撼的功能效果,引起的社会关注度远超之前任何一项技术的出现。但是OpenAI也坦言在智能体这个领域,自己并没有比其他公司掌握的更多,这也是目前很多科技公司在同一起跑线上奋力奔跑的机遇。
An agent is anything that can be viewed as perceiving its environment through sensors and acting upon that environment through actuators.
—— Stuart J. Russell and Peter Norvig
在智能操作、问答、提示的实践过程中,我们积累了模型、Prompt、知识库、微调等相关经验,但是在模型编排、领域模型训练、安全性等方面需要进一步学习和应用。同时我们也在探索终端智能体对业务异常分析、定位和解决的能力。
审核编辑 黄宇
-
机器人
+关注
关注
211文章
28479浏览量
207423 -
GPT
+关注
关注
0文章
354浏览量
15420 -
OpenAI
+关注
关注
9文章
1099浏览量
6569 -
大模型
+关注
关注
2文章
2477浏览量
2838
发布评论请先 登录
相关推荐
USB一线通监控副屏设计方案
名单公布!【书籍评测活动NO.49】大模型启示录:一本AI应用百科全书
神话游戏热浪推动文化输出,第一线全栈云网安服务助力游戏企业加速全球化部署

工程智能发展之路(二):利用大模型打造新一代工业智能的数字底座
大语言模型:原理与工程实践+初识2
【大语言模型:原理与工程实践】大语言模型的应用
【大语言模型:原理与工程实践】大语言模型的评测
【大语言模型:原理与工程实践】大语言模型的基础技术
【大语言模型:原理与工程实践】揭开大语言模型的面纱
【大语言模型:原理与工程实践】探索《大语言模型原理与工程实践》
搭载集创北方OLED触控芯片的国产一线品牌高端超薄笔电正式上市
名单公布!【书籍评测活动NO.31】大语言模型:原理与工程实践
名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践
应用大模型提升研发效率的实践与探索






 工商网监
工商网监
评论