 缓存有大key?你得知道的一些手段
缓存有大key?你得知道的一些手段

背景:
最近系统内缓存CPU使用率一直报警,超过设置的70%报警阀值,针对此场景,需要对应解决缓存是否有大key使用问题,扫描缓存集群的大key,针对每个key做优化处理。
以下是扫描出来的大key,此处只放置了有效关键信息。
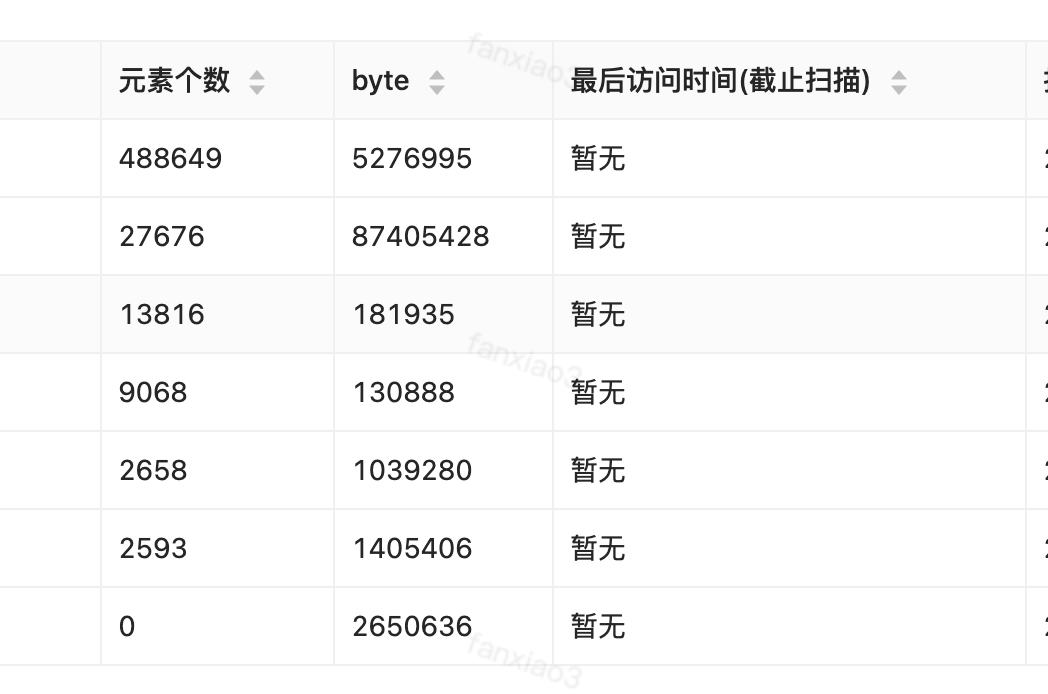
图1
大key介绍:
想要解决大key,首先我们得知道什么定义为大key。
什么是大KEY:
大key 并不是指 key 的值很大,而是 key 对应的 value 很大(非常占内存)。此处为中间件给出的定义:
•单个String类型的Key大小达到20KB并且OPS高
•单个String达到100KB
•集合类型的Key总大小达到1MB
•集合类型的Key中元素超过5000个
大KEY带来的影响:
知道了大key的定义,那么我们也得知道大key的带来的影响:
•客户端超时阻塞。 Redis 执行命令是单线程处理,然后在大 key处理时会比较耗时,那么就会发生阻塞 ,期间就会各种业务超时出现。
•引发网络阻塞。每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于服务器来说是灾难性的。
•阻塞工作线程。如果使用 del 删除大 key 时,会阻塞工作线程,无法处理后续的命令。
•内存分布不均。集群各分片内存使用不均。某个分片占用内存较高或OOM,发送缓存区增大等,导致该分片其他Key被逐出,同时也会造成其他分片的资源浪费。
大KEY解决手段:
1、历史key未使用
场景描述:
针对这种key场景,其实存在着历史原因,可能是伴随着某个业务下线或者不使用,往往对应实现的缓存操作代码会删除,但是对于缓存数据往往不会做任何处理,久而久之,这种脏数据会一直堆积,占用着资源。那么如果确定已经无使用,并且可以确认有持久化数据(如mysql、es等)备份的话,可以直接将对应key删除。
实例经验:
如图1上面的元素个数488649,其实整个系统查看了下,没有使用的地方,最近也没有访问,相信也是因为一直没有用到, 否则系统内一旦用了这个key来操作hgetall、smembers等,那么缓存服务应该就会不可用了。
2、元素数过多
场景描述:
针对于Set、HASH这种场景,如果元素数量超过5000就视为大的key,以上面图1为例,可以看到元素个数有的甚至达到了1万以上。针对这种的如果对应value值不大,我们可以采取平铺的形式,
实例经验:
比如系统内历史的设计是存储下每个品牌对应的名称,那么就设置了统一的key,然后不同的品牌id作为fild,操作了hSet和hGet来存储获取数据,降低查询外围服务的频率。但是随着品牌数量的增长,导致元素逐步增多,元素个数就超过了大key的预设值了。这种根据场景,我们其实存储本身只有一个品牌名称,那么我们就针对于品牌id对应加上一个统一前缀作为唯一key,采用平铺方式缓存对应数据即可。那么针对这种数据的替换,我这里也总结了下具体要实现的步骤:
修改代码查询和赋值逻辑:
•把原始的hGet的逻辑修改为get获取;
•把原始hSet的逻辑修改为set赋值。
历史数据刷新到新缓存key:
为了避免上线之后出现缓存雪崩,因为替换了新的key,我们需要通过现有的HASH的数据刷新到新的缓存中,所以需要历史数据处理。
通过hGetAll获取所以元素数据
循环缓存元素数据操作存储新的缓存key和value。
public String refreshHistoryData(){
try {
String key = "historyKey";
Map< String, String > redisInfoMap= redisUtils.hGetAll(key);
if (redisInfoMap.isEmpty()){
return "查询缓存无数据";
}
for (Map.Entry< String, String > entry : redisInfoMap.entrySet()) {
String redisVal = entry.getValue();
String filedKey = entry.getKey();
String newDataRedisKey = "newDataKey"+filedKey;
redisUtils.set(newDataRedisKey,redisVal);
}
return "success";
}catch (Exception e){
LOG.error("refreshHistoryData 异常:",e);
}
return "failed";
}
注意:这里一定要先刷历史数据,再上线代码业务逻辑的修改。防止引发缓存雪崩
3、大对象转换存储形式
场景描述:
复杂的大对象可以尝试将对象分拆成几个key-value, 使用mGet和mSet操作对应值或者pipeline的形式,最后拼装成需要返回的大对象。这样意义在于可以分散单次操作的压力,将操作压力平摊到多个redis实例中,降低对单个redis的IO影响;
实例经验:
这里以系统内订单对象为例:订单对象Order基础属性有几十个,如订单号、金额、时间、类型等,除此之外还要包含订单下的商品OrderSub、预售信息PresaleOrder、发票信息OrderInvoice、订单时效OrderPremiseInfo、订单轨迹OrderTrackInfo、订单详细费用OrderFee等信息。
那么对于每个订单相关信息,我们可以设置为单独的key,把订单信息和几个相关的关联数据每个按照单独key存储,接着通过mGet方式获取每个信息之后,最后封装成整体Order对象。下面仅展示关键伪代码以mSet和mGet实现:
缓存定义:
public enum CacheKeyConstant {
/**
* 订单基础缓存key
*/
REDIS_ORDER_BASE_INFO("ORDER_BASE_INFO"),
/**
* 订单商品缓存key
*/
ORDER_SUB_INFO("ORDER_SUB_INFO"),
/**
* 订单预售信息缓存key
*/
ORDER_PRESALE_INFO("ORDER_PRESALE_INFO"),
/**
* 订单履约信息缓存key
*/
ORDER_PREMISE_INFO("ORDER_PREMISE_INFO"),
/**
* 订单发票信息缓存key
*/
ORDER_INVOICE_INFO("ORDER_INVOICE_INFO"),
/**
* 订单轨迹信息缓存key
*/
ORDER_TRACK_INFO("ORDER_TRACK_INFO"),
/**
* 订单详细费用信息缓存key
*/
ORDER_FEE_INFO("ORDER_FEE_INFO"),
;
/**
* 前缀
*/
private String prefix;
/**
* 项目统一前缀
*/
public static final String COMMON_PREFIX = "XXX";
CacheKeyConstant(String prefix){
this.prefix = prefix;
}
public String getPrefix(String subKey) {
if(StringUtil.isNotEmpty(subKey)){
return COMMON_PREFIX + prefix + "_" + subKey;
}
return COMMON_PREFIX + prefix;
}
public String getPrefix() {
return COMMON_PREFIX + prefix;
}
}
缓存存储:
/** * @description 刷新订单到缓存 * @param order 订单信息 */ public boolean refreshOrderToCache(Order order){ if(order == null || order.getOrderId() == null){ return ; } String orderId = order.getOrderId().toString(); //设置存储缓存数据 Map< String,String > cacheOrderMap = new HashMap< >(16); cacheOrderMap.put(CacheKeyConstant.ORDER_BASE_INFO.getPrefix(orderId), JSON.toJSONString(buildBaseOrderVo(order))); cacheOrderMap.put(CacheKeyConstant.ORDER_SUB_INFO.getPrefix(orderId), JSON.toJSONString(order.getCustomerOrderSubs())); cacheOrderMap.put(CacheKeyConstant.ORDER_PRESALE_INFO.getPrefix(orderId), JSON.toJSONString(order.getPresaleOrderData())); cacheOrderMap.put(CacheKeyConstant.ORDER_INVOICE_INFO.getPrefix(orderId), JSON.toJSONString(order.getOrderInvoice())); cacheOrderMap.put(CacheKeyConstant.ORDER_TRACK_INFO.getPrefix(orderId), JSON.toJSONString(order.getOrderTrackInfo())); cacheOrderMap.put(CacheKeyConstant.ORDER_PREMISE_INFO.getPrefix(orderId), JSON.toJSONString( order.getPresaleOrderData())); cacheOrderMap.put(CacheKeyConstant.ORDER_FEE_INFO.getPrefix(orderId), JSON.toJSONString(order.getOrderFeeVo())); superRedisUtils.mSetString(cacheOrderMap); }
缓存获取:
/** * @description 通过订单号获取缓存数据 * @param orderId 订单号 * @return Order 订单实体信息 */ public Order getOrderFromCache(String orderId){ if(StringUtils.isBlank(orderId)){ return null; } //定义查询缓存集合key List< String > queryOrderKey = Arrays.asList(CacheKeyConstant.ORDER_BASE_INFO.getPrefix(orderId),CacheKeyConstant.ORDER_SUB_INFO.getPrefix(orderId), CacheKeyConstant.ORDER_PRESALE_INFO.getPrefix(orderId),CacheKeyConstant.ORDER_INVOICE_INFO.getPrefix(orderId),CacheKeyConstant.ORDER_TRACK_INFO.getPrefix(orderId), CacheKeyConstant.ORDER_PREMISE_INFO.getPrefix(orderId),CacheKeyConstant.ORDER_FEE_INFO.getPrefix(orderId)); //查询结果 List< String > result = redisUtils.mGet(queryOrderKey); //基础信息 if(CollectionUtils.isEmpty(result)){ return null; } String[] resultInfo = result.toArray(new String[0]); //基础信息 if(StringUtils.isBlank(resultInfo[0])){ return null; } BaseOrderVo baseOrderVo = JSON.parseObject(resultInfo[0],BaseOrderVo.class); Order order = coverBaseOrderVoToOrder(baseOrderVo); //订单商品 if(StringUtils.isNotBlank(resultInfo[1])){ List< OrderSub > orderSubs =JSON.parseObject(result.get(1), new TypeReference< List< OrderSub >>(){}); order.setCustomerOrderSubs(orderSubs); } //订单预售 if(StringUtils.isNotBlank(resultInfo[2])){ PresaleOrderData presaleOrderData = JSON.parseObject(resultInfo[2],PresaleOrderData.class); order.setPresaleOrderData(presaleOrderData); } //订单发票 if(StringUtils.isNotBlank(resultInfo[3])){ OrderInvoice orderInvoice = JSON.parseObject(resultInfo[3],OrderInvoice.class); order.setOrderInvoice(orderInvoice); } //订单轨迹 if(StringUtils.isNotBlank(resultInfo[5])){ OrderTrackInfo orderTrackInfo = JSON.parseObject(resultInfo[5],OrderTrackInfo.class); order.setOrderTrackInfo(orderTrackInfo); } //订单履约信息 if(StringUtils.isNotBlank(resultInfo[6])){ List< OrderPremiseInfo > orderPremiseInfos =JSON.parseObject(result.get(6), new TypeReference< List< OrderPremiseInfo >>(){}); order.setPremiseInfos(orderPremiseInfos); } //订单费用明细信息 if(StringUtils.isNotBlank(resultInfo[7])){ OrderFeeVo orderFeeVo = JSON.parseObject(resultInfo[7],OrderFeeVo.class); order.setOrderFeeVo(orderFeeVo); } return order; }
注意:获取缓存的结果跟传入的key的顺序保持对应即可。
缓存util方法封装:
/**
*
* @description 同时将多个 key-value (域-值)对设置到缓存中。
* @param mappings 需要插入的数据信息
*/
public void mSetString(Map< String, String > mappings) {
CallerInfo callerInfo = Ump.methodReg(UmpKeyConstants.REDIS.REDIS_STATUS_READ_MSET);
try {
redisClient.getClientInstance().mSetString(mappings);
} catch (Exception e) {
Ump.funcError(callerInfo);
}finally {
Ump.methodRegEnd(callerInfo);
}
}
/**
*
* @description 同时将多个key的结果返回。
* @param queryKeys 查询的缓存key集合
*/
public List< String > mGet(List< String > queryKeys) {
CallerInfo callerInfo = Ump.methodReg(UmpKeyConstants.REDIS.REDIS_STATUS_READ_MGET);
try {
return redisClient.getClientInstance().mGet(queryKeys.toArray(new String[0]));
} catch (Exception e) {
Ump.funcError(callerInfo);
}finally {
Ump.methodRegEnd(callerInfo);
}
return new ArrayList< String >(queryKeys.size());
}
这里附上通过pipeline的util封装,可参考。
/** * @description pipeline放松查询数据 * @param redisKeyList * @return java.util.List< java.lang.String > */ public List< String > getValueByPipeline(List< String > redisKeyList) { if(CollectionUtils.isEmpty(redisKeyList)){ return null; } List< String > resultInfo = new ArrayList< >(redisKeyList); CallerInfo callerInfo = Ump.methodReg(UmpKeyConstants.REDIS.REDIS_STATUS_READ_GET); try { PipelineClient pipelineClient = redisClient.getClientInstance().pipelineClient(); //添加批量查询任务 List< JimFuture > futures = new ArrayList< >(); redisKeyList.forEach(redisKey -> { futures.add(pipelineClient.get(redisKey.getBytes())); }); //处理查询结果 pipelineClient.flush(); //可以等待future的返回结果,来判断命令是否成功。 for (JimFuture future : futures) { resultInfo.add(new String((byte[])future.get())); } } catch (Exception e) { log.error("getValueByPipeline error:",e); Ump.funcError(callerInfo); return new ArrayList< >(redisKeyList.size()); }finally { Ump.methodRegEnd(callerInfo); } return resultInfo; }
注意:Pipeline不建议用来设置缓存值,因为本身不是原子性的操作。
4、压缩存储数据
压缩方法结果:
单个元素时:

| 压缩方法 | 压缩前大小Byte | 压缩后大小Byte | 压缩耗时 | 解压耗时 | 压缩解压后比对结果 |
| DefaultOutputStream | 446(0.43kb) | 254 (0.25kb) | 1ms | 0ms | 相同 |
| GzipOutputStream | 446(0.43kb) | 266 (0.25kbM) | 1ms | 1ms | 相同 |
| ZlibCompress | 446(0.43kb) | 254 (0.25kb) | 1ms | 0ms | 相同 |
四百个元素集合:

| 压缩方法 | 压缩前大小Byte | 压缩后大小Byte | 压缩耗时 | 解压耗时 | 压缩解压后比对结果 |
| DefaultOutputStream | 6732(6.57kb) | 190 (0.18kb) | 2ms | 0ms | 相同 |
| GzipOutputStream | 6732(6.57kb) | 202 (0.19kb) | 1ms | 1ms | 相同 |
| ZlibCompress | 6732(6.57kb) | 190 (0.18kb) | 1ms | 0ms | 相同 |
四万个元素集合时:

| 压缩方法 | 压缩前大小Byte | 压缩后大小Byte | 压缩耗时 | 解压耗时 | 压缩解压后比对结果 |
| DefaultOutputStream | 640340(625kb) | 1732 (1.69kb) | 37ms | 2ms | 相同 |
| GzipOutputStream | 640340(625kb) | 1744 (1.70kb) | 11ms | 3ms | 相同 |
| ZlibCompress | 640340(625kb) | 1732 (1.69kb) | 69ms | 2ms | 相同 |
压缩代码样例
DefaultOutputStream
public static byte[] compressToByteArray(String text) throws IOException {
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
Deflater deflater = new Deflater();
DeflaterOutputStream deflaterOutputStream = new DeflaterOutputStream(outputStream, deflater);
deflaterOutputStream.write(text.getBytes());
deflaterOutputStream.close();
return outputStream.toByteArray();
}
public static String decompressFromByteArray(byte[] bytes) throws IOException {
ByteArrayInputStream inputStream = new ByteArrayInputStream(bytes);
Inflater inflater = new Inflater();
InflaterInputStream inflaterInputStream = new InflaterInputStream(inputStream, inflater);
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int length;
while ((length = inflaterInputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, length);
}
inflaterInputStream.close();
outputStream.close();
byte[] decompressedData = outputStream.toByteArray();
return new String(decompressedData);
}
GZIPOutputStream
public static byte[] compressGzip(String str) {
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
GZIPOutputStream gzipOutputStream = null;
try {
gzipOutputStream = new GZIPOutputStream(outputStream);
} catch (IOException e) {
throw new RuntimeException(e);
}
try {
gzipOutputStream.write(str.getBytes("UTF-8"));
} catch (IOException e) {
throw new RuntimeException(e);
}finally {
try {
gzipOutputStream.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
return outputStream.toByteArray();
}
public static String decompressGzip(byte[] compressed) throws IOException {
ByteArrayInputStream inputStream = new ByteArrayInputStream(compressed);
GZIPInputStream gzipInputStream = new GZIPInputStream(inputStream);
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int length;
while ((length = gzipInputStream.read(buffer)) > 0) {
outputStream.write(buffer, 0, length);
}
gzipInputStream.close();
outputStream.close();
return outputStream.toString("UTF-8");
}
ZlibCompress
public byte[] zlibCompress(String message) throws Exception {
String chatacter = "UTF-8";
byte[] input = message.getBytes(chatacter);
BigDecimal bigDecimal = BigDecimal.valueOf(0.25f);
BigDecimal length = BigDecimal.valueOf(input.length);
byte[] output = new byte[input.length + 10 + new Double(Math.ceil(Double.parseDouble(bigDecimal.multiply(length).toString()))).intValue()];
Deflater compresser = new Deflater();
compresser.setInput(input);
compresser.finish();
int compressedDataLength = compresser.deflate(output);
compresser.end();
return Arrays.copyOf(output, compressedDataLength);
}
public static String zlibInfCompress(byte[] data) {
String s = null;
Inflater decompresser = new Inflater();
decompresser.reset();
decompresser.setInput(data);
ByteArrayOutputStream o = new ByteArrayOutputStream(data.length);
try {
byte[] buf = new byte[1024];
while (!decompresser.finished()) {
int i = decompresser.inflate(buf);
o.write(buf, 0, i);
}
s = o.toString("UTF-8");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
o.close();
} catch (IOException e) {
e.printStackTrace();
}
}
decompresser.end();
return s;
}
可以看到压缩效率比较好,压缩效率可以从几百kb压缩到几kb内;当然也是看具体场景。不过这里就是最好是避免调用量大的场景使用,毕竟解压和压缩数据量大会比较耗费cpu性能。如果是黄金链路使用,还需要具体配合压测,对比前后接口性能。
5、替换存储方案
如果数据量庞大,那么其实本身是不是就不太适合redis这种缓存存储了。可以考虑es或者mongo这种文档式存储结构,存储大的数据格式。
总结:
redis缓存的使用是一个支持业务和功能高并发的很好的使用方案,但是随着使用场景的多样性以及数据的增加,可能逐渐的会出现大key,日常使用中都可以注意以下几点:
1.分而治之:如果需要存储大量的数据,避免直接放到缓存中。可以将其拆分成多个小的value。就像是咱们日常吃饭,盛到碗里,一口一口的吃,俗话说的好呀:“细嚼慢咽”。
2.避免使用不必要的数据结构。例如,如果只需要存储一个字符串结构的数据,就不要过度设计,使用Hash或者List等数据结构。
3.定期清理过期的key。如果Redis中存在大量的过期key,就会导致Redis的性能下降,或者场景非必要以缓存来持久存储的,可以添加过期时间,定时清理过期的key,就像是家中的日常垃圾类似,定期的清洁和打扫,居住起来咱们才会更加舒服和方便。
4.对象压缩。将大的数据压缩成更小的数据,也是一种好的解决方案,不过要注意压缩和解压的频率,毕竟是比较耗费cpu的。
以上是我根据现有实际场景总结出的一些解决手段,记录了这些大key的优化经验,希望可以在日常场景中帮助到大家。大家有其他的好的经验,也可以分享出来。
审核编辑 黄宇
-
缓存
+关注
关注
1文章
248浏览量
27841 -
key
+关注
关注
0文章
53浏览量
13390 -
Redis
+关注
关注
0文章
396浏览量
12278
发布评论请先 登录
基于javaPoet的缓存key优化实践

你总得知道你为什么要用Cortex-M
硬盘缓存有什么用
区块链的事实你知道哪一些
CPU缓存是什么意思_CPU缓存有什么作用
你知道开关电源布局以及印制板布线的一些原则吗





评论