 2024多样性算力产业峰会:江波龙解码AI存储方案的未来之路
2024多样性算力产业峰会:江波龙解码AI存储方案的未来之路
6月18日,多样性算力产业峰会2024在北京圆满举行,江波龙企业级存储事业部市场总监曹浔峰受邀出席本次峰会并发表了《大模型时代AI存储方案挑战与创新》主题演讲,深入探讨了多样性算力产业的发展趋势和创新应用。

曹浔峰在演讲中指出,随着AI中大语言模型人工智能参数量呈指数级增长,AI应用的复杂度也日益增加,这对AI训练过程中所需的缓存存储容量和性能提出了更高的要求。然而,尽管AI应用发展迅速,但相关的缓存硬件技术和产品的发展速度并未与之同步,这导致了AI模型训练过程中的性能瓶颈问题。曹浔峰深入分析了这一问题,并针对数据缓存、传输和存储的瓶颈提出了具体的解决方案。
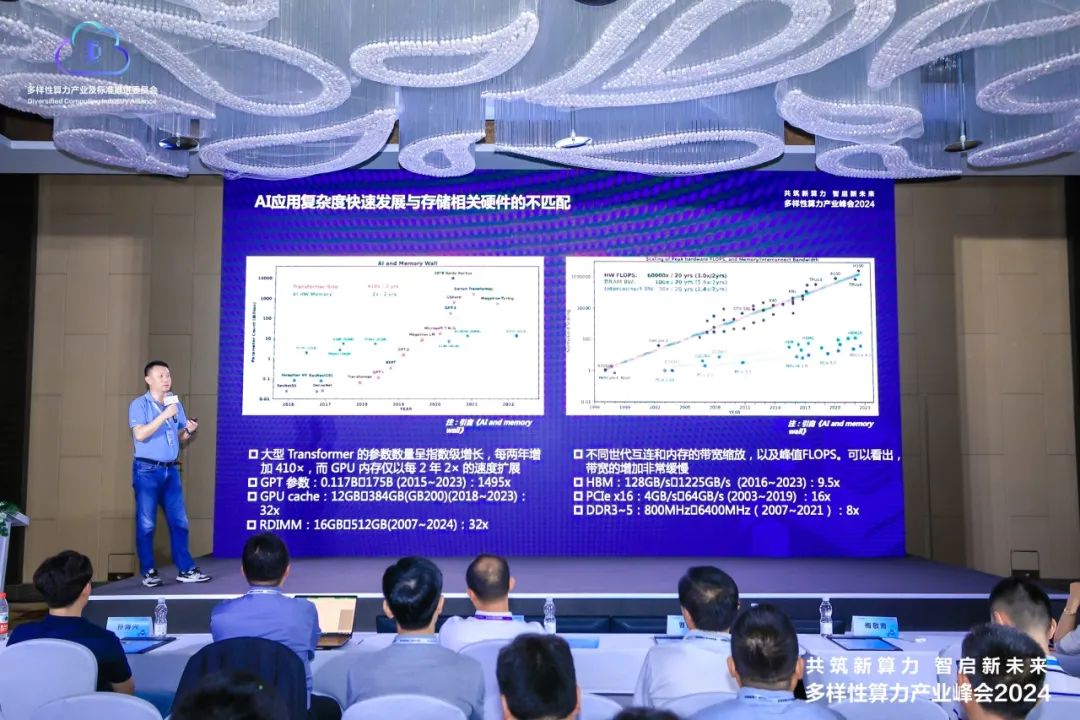
在AI应用的实践中,原始数据通常需要经历精细的清洗和预处理流程,以转化为符合AI训练要求的高质量数据集。随后,这些数据集通过网络传输至AI服务器的本地SSD存储,再通过PCIe通道upload至GPU HBM缓存中进行训练。训练过程产生的中间数据量是训练初始数据的4~7倍。依靠目前GPU配备的数十GB HBM容量来存储这些数据是远远不够的,因此需要利用系统内存RDIMM或性能和延时接近的高速存储器设备作为补充。
曹浔峰指出,随着AI训练模型参数量增长至千亿或万亿级别,HBM缓存和RDIMM容量不足将会成为训练效率的瓶颈。在3D-stacked DRAM内存成本高企的情况下,采用高性能、大容量的CXL存储器或是8x GPU卡AI服务器理想的缓存优化解决方案。同时,江波龙正在预研能够支持AIC和E3.S的JBOM系统,结合即将到来支持CXL2.0的服务器系统,将为万卡AI训练集群提供更具成本效益的内存池化共享硬件解决方案。
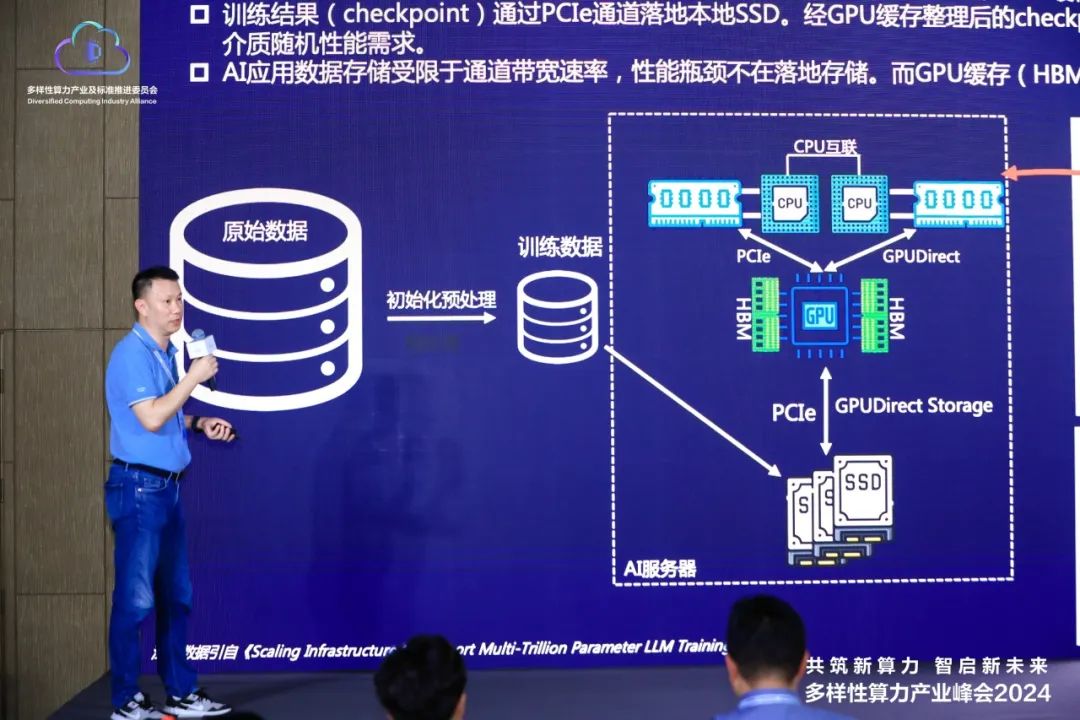
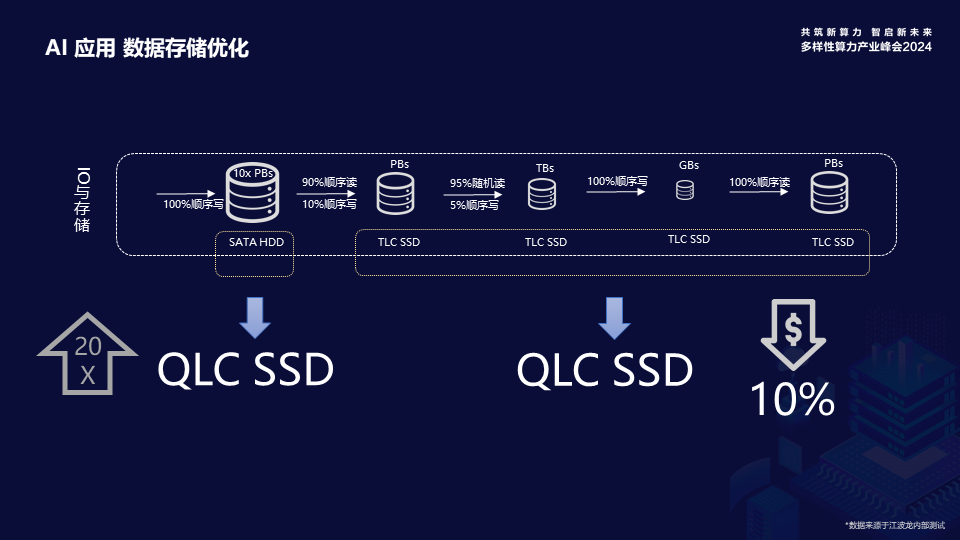
曹浔峰还分享了对AI应用数据存储优化的思考。他提到,AI训练应用对数据存储的访问主要为顺序读写操作,而QLC在顺序读写性能上与TLC接近,且成本更低。随着PCIe Gen5带宽的提升,QLC技术能够满足训练过程中Checkpoint数据存储高带宽高并发的存储需求,因此,QLC SSD有望替代当前主流的TLC SSD,成为大语言模型AI训练应用的更优选择。
曹浔峰重点介绍了江波龙的企业级存储发展历程。经过不断地技术创新,江波龙已成功构建了完整的企业级存储布局,涵盖了NAND Flash+DRAM多颗粒类型产品,至今已经成功推出了包括企业级PCIe 4.0 NVMe SSD、企业级SATA SSD、企业级RDIMM、CXL 2.0内存拓展模块在内的多款高性能产品。
其中,江波龙今年推出的FORESEE CXL 2.0内存拓展模块,则是面向AI应用的存储优化的成果之一。一方面,该产品支持内存池化共享,能够基于16Gb SDP颗粒实现192GB大容量,相比业界同期水平实现成本大幅度下降的优势。另一方面,产品基于 DDR5 DRAM开发,支持PCIe 5.0×8接口,理论带宽高达32GB/s,可与支持CXL规范及E3.S接口的背板和服务器主板实现无缝连接,并减少高昂的内存成本和闲置的内存资源,大幅提高内存利用率,从而有效拓展AI服务器的内存容量并提升带宽性能,为应用场景提供更具弹性和扩展性的存储解决方案。

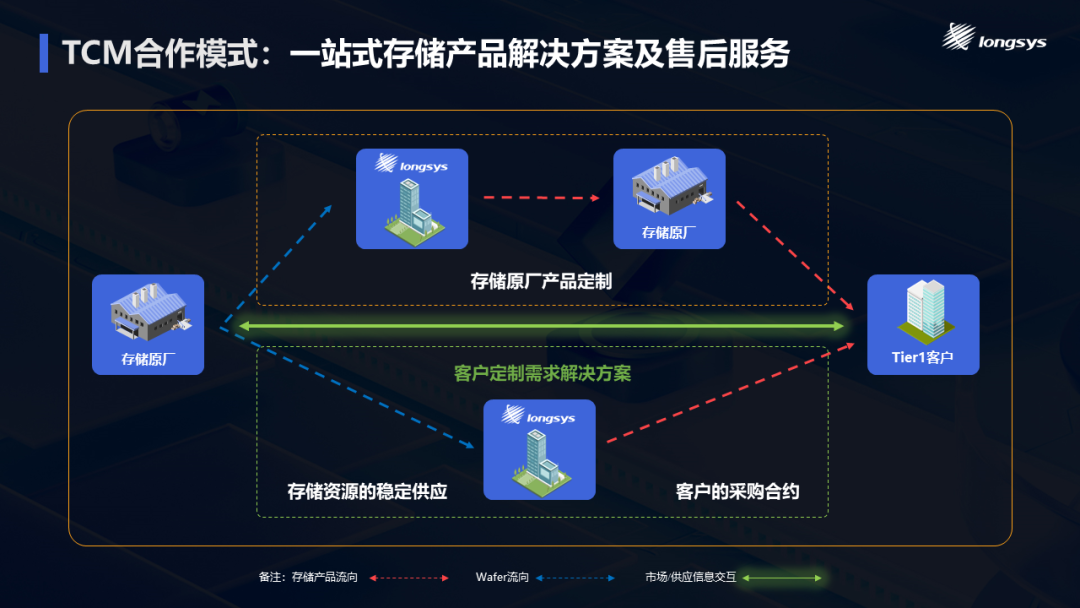
在演讲的最后,曹浔峰提到了公司面向行业领先客户正在积极推进从传统产品销售模式向TCM(Technology Contract Manufacture, 技术合约制造)合作模式的转型升级。这一转型旨在简化存储晶圆厂与终端客户之间的沟通流程,解决因中间环节繁杂而导致的“断层”问题,并有效应对下游应用市场对存储产品的多样化、定制化和创新化需求。通过TCM合作模式,江波龙将基于上游存储晶圆厂或下游Tier1客户的产品需求,高效完成存储产品的一站式交付,从而提高存储产业链从原厂、产品开发、封装测试、产品制造到行业应用的效率和效益。
多样性算力产业正迎来高速发展的黄金时期,创新技术层出不穷,新业态和新模式竞相迸发。在这一进程中,存储技术扮演着至关重要的角色。江波龙将持续为计算产业发展贡献新的动力,开创更多的合作机会,共同塑造计算产业的新未来。
-
存储
+关注
关注
13文章
4316浏览量
85866 -
AI
+关注
关注
87文章
30927浏览量
269178 -
江波龙
+关注
关注
4文章
271浏览量
26997
发布评论请先 登录
相关推荐
江波龙全栈定制方案亮相2024数字科技生态大会,PTM赋能电信云服务

江波龙全栈定制方案亮相2024数字科技生态大会,PTM赋能电信云服务

2024 MWC上海:江波龙探索存储技术新趋势

2024 MWC上海:江波龙探索存储技术新趋势


得瑞领新邀您共赴多样性算力产业峰会2024,探讨未来算力新趋势
2024高通汽车技术与合作峰会:江波龙全面展示汽车存储解决方案


CFMS2024:江波龙解码如何打破存储模组厂的经营魔咒

江波龙亮相CES2024,前沿存储技术备受瞩目






 工商网监
工商网监
评论