 全国产RK3568J + FPGA的PCIe、FSPI通信实测数据分享!
全国产RK3568J + FPGA的PCIe、FSPI通信实测数据分享!


测试数据汇总
案例 | 时钟频率 | 理论速率 | 测试结果 |
FSPI通信案例 | 150MHz | 71.53MB/s | 读速率:67.452MB/s 写速率:52.638MB/s |
PCIe通信案例 | 100MHz | 803.09MB/s | 读速率:595.24MB/s 写速率:791.14MB/s |
备注:
(1)当TLP header size =16Byte时,PCIe理论传输速率为:782.50MB/s;(2)当TLP header size =12Byte时,PCIe理论传输速率为:803.09MB/s;
FSPI、PCIe总线介绍
FSPI(Flexible Serial Peripheral Interface)是一种高速、全双工、同步的串行通信总线,在RK3568J处理器中就有FSPI控制器,可用来连接FSPI设备。它具备如下特点:
(1)支持串行NOR FLASH、串行NAND FLASH;
(2)支持SDR模式;
(3)支持单线、双线以及四线模式。

图1FSPI数据传输波形图
PCIe,即PCI-Express(peripheral component interconnect express)是一种高速串行计算机扩展总线标准。主要用于扩充计算机系统总线数据吞吐量以及提高设备通信速度。
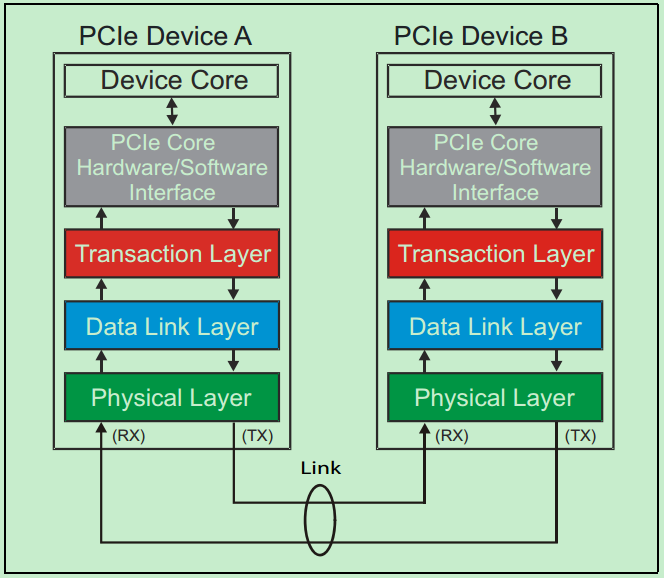
图2PCIe数据传输图
硬件平台介绍
硬件方案:创龙科技TL3568F-EVM评估板(瑞芯微RK3568J + 紫光同创Logos-2)。
TL3568F-EVM评估板简介:
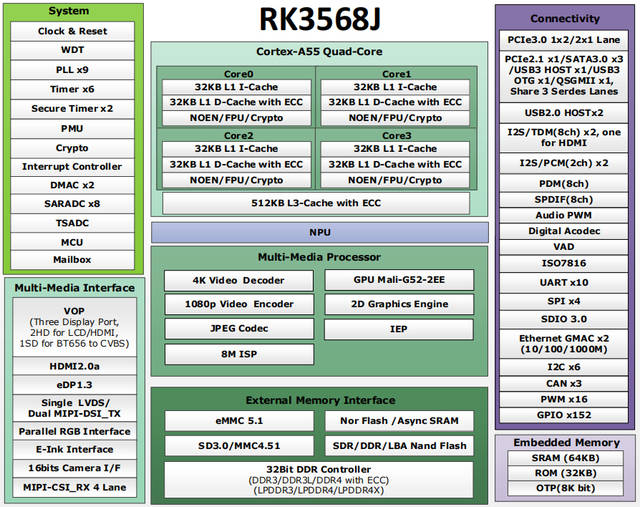
创龙科技TL3568F-EVM是一款基于瑞芯微RK3568J/RK3568B2四核ARM Cortex-A55处理器 + 紫光同创Logos-2 PG2L50H/PG2L100H FPGA设计的异构多核国产工业评估板,由核心板和评估底板组成,ARM Cortex-A55处理单元主频高达1.8GHz/2.0GHz。核心板ARM、FPGA、ROM、RAM、电源、晶振、连接器等所有元器件均采用国产工业级方案,国产化率100%。同时,评估底板大部分元器件亦采用国产工业级方案。
RK3568J + FPGA典型应用场景
RK3568J + FPGA应用场景十分广泛,涵盖小电流选线、继电保护测试仪、运动控制器、医疗内窥镜、血液分析仪、目标识别跟踪等领域,可满足多种工业应用要求。
案例测试
下文主要介绍基于瑞芯微RK3568J与紫光同创Logos-2(硬件平台:创龙科技TL3568F-EVM评估板)的FSPI、PCIe通信案例,按照创龙科技提供的案例用户手册进行操作得出测试结果。
基于RK3568J + FPGA的FSPI通信案例
(1)案例说明
ARM端运行Linux系统,基于FSPI总线对FPGA DRAM进行读写测试。
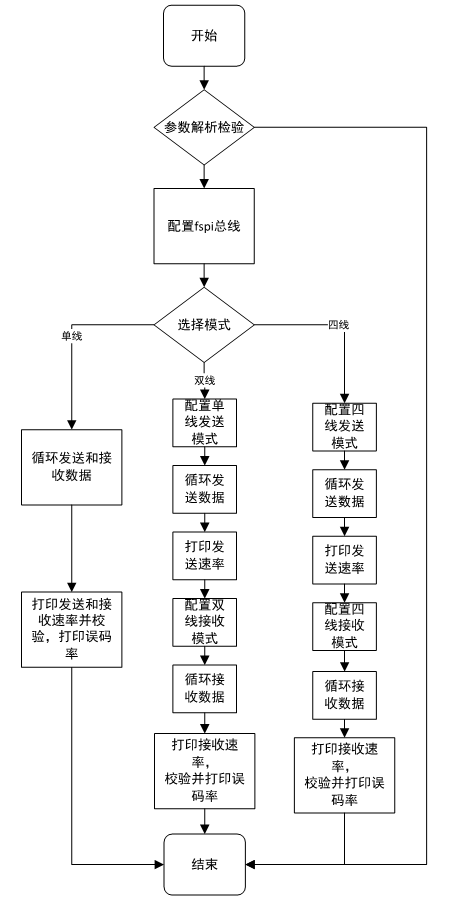
图4ARM端程序流程图
ARM端实现SPI Master功能,原理说明如下:
a)打开SPI设备节点,如:/dev/spidev4.0。
b)使用ioctl配置FSPI总线,如FSPI总线极性和相位、通信速率、数据长度等。
c)选择模式为单线模式、双线模式或四线模式。当设置FSPI为四线模式时,发送数据为四线模式,接收数据为四线模式。
d)发送数据至FSPI总线,以及从FSPI总线读取数据。
e)校验数据,然后打印读写速率、误码率。
FPGA端实现SPI Slave功能,原理说明如下:
a)FPGA将SPI Master发送的数据保存至DRAM。
b)SPI Master发起读数据时,FPGA从DRAM读取数据通过FSPI总线传输至SPI Master。
(2)测试结果
ARM通过FSPI总线(四线模式)写入2048Byte随机数据至FPGA DRAM,然后读出数据、进行数据校验,同时打印FSPI总线读写速率和误码率。
从下图可知,本次实测写速率为11.035MB/s,读速率为24.414MB/s,误码率为0.00%。
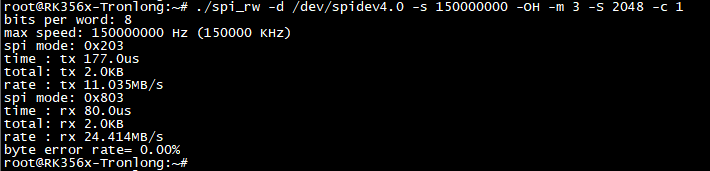
图5
若设置FSPI总线通信时钟频率为150MHz,ARM通过FSPI总线写入1MByte随机数据至FPGA DRAM,然后读出数据,循环100次,不做数据检验,最后打印FSPI总线读写速率和误码率。
最终,本次测试设置FSPI总线通信时钟频率为150MHz,则FSPI四线模式理论通信速率为:(150000000 / 1024 / 1024 / 8 x 4)MB/s ≈ 71.53MB/s。从下图可知,本次实测写速率为52.638MB/s,读速率为67.452MB/s,比较接近理论通信速率。
备注:本案例设计FPGA BRAM大小2048Byte,一次写入1MByte数据量会导致BRAM数据溢出,因此误码率较高。配置一次写入1MByte数据量只是为了验证FSPI的最大通信速率,不考虑误码率。
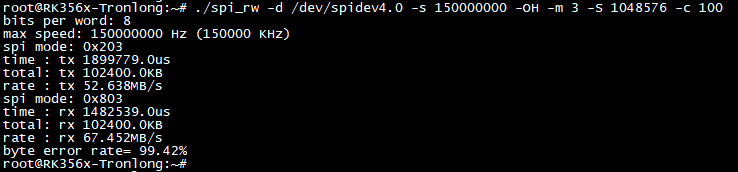
图6
基于RK3568J + FPGA的PCIe通信案例
(1)案例说明
ARM端基于PCIe总线对FPGA DRAM进行读写测试。应用程序通过ioctl函数发送命令开启DMA传输数据后,等待驱动上报input事件;当应用层接收到input事件,说明DMA传输数据完成。
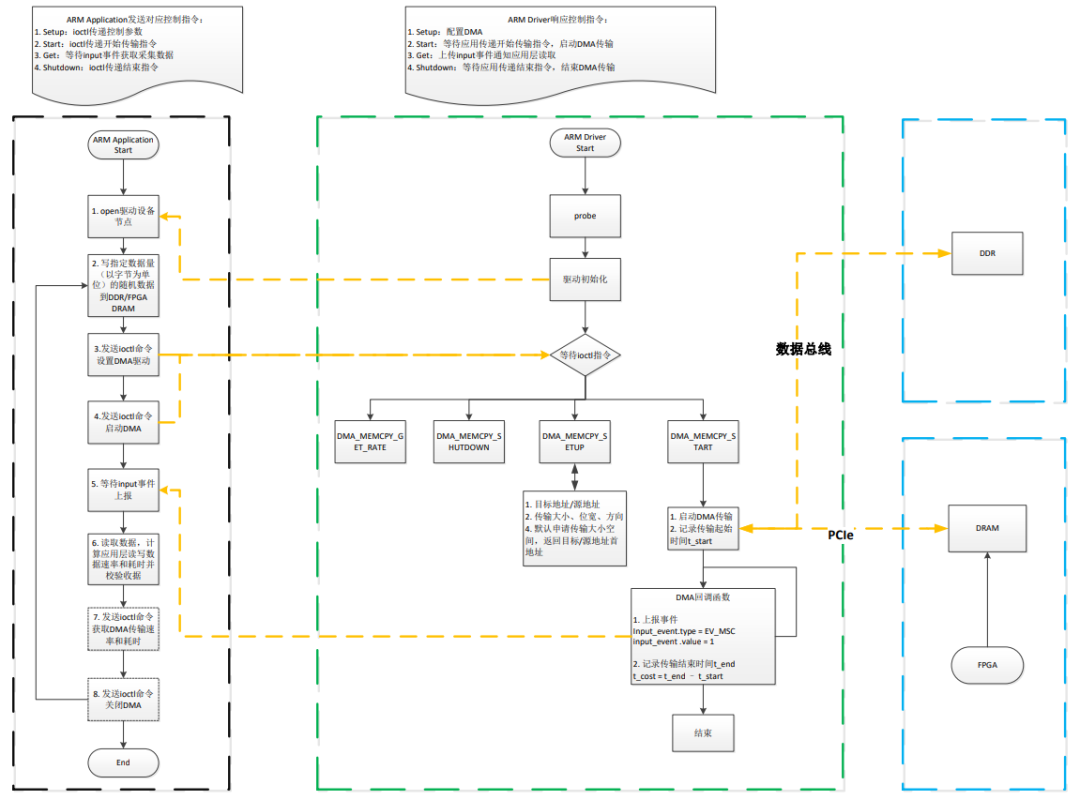
图7程序流程图
ARM端原理说明如下:
a)采用DMA方式;
b)将数据写至dma_memcpy驱动申请的连续内存空间(位于DDR);
c)配置DMA,如源地址、目标地址、传输的数据大小等;
d)写操作:通过ioctl函数启动DMA,通过PCIe总线将数据搬运至FPGA DRAM;
e)程序接收驱动上报input事件后,将通过ioctl函数获取DMA搬运数据耗时,并计算DMA传输速率(即写速率);
f)读操作:通过ioctl函数启动DMA,通过PCIe总线将FPGA DRAM中的数据搬运至dma_memcpy驱动申请的连续内存空间(位于DDR);
g)程序接收驱动上报input事件后,将数据从内核空间读取至用户空间,然后校验数据,同时通过ioctl函数获取DMA搬运数据耗时,并计算DMA传输速率(即读速率)。
FPGA端原理说明如下:
a)实现PCIe Endpoint功能;
b)处理PCIe RC端发起的PCIe BAR0空间读写事务;
c)将PCIe BAR0读写数据缓存至FPGA DRAM中。
(2)测试结果
将随机数据先写入FPGA DRAM,再从FPGA DRAM读出。测试完成后,程序将会打印最终测试结果,包含读写平均传输耗时、读写平均传输速率、读写错误统计等信息。

图8
表 2测试结果说明
write/read | 写操作 | 读操作 |
time | DMA传输耗时,本次测试为79us | DMA传输耗时,本次测试为105us |
rate | DMA传输速率,本次测试为791.14MB/s | DMA传输速率,本次测试为595.24MB/s |
app time | 应用层写数据至驱动Buffer耗时,本次测试为55us | 应用层从驱动Buffer读取数据耗时,本次测试为288us |
app rate | 应用层写数据至驱动Buffer速率,本次测试为1132.10MB/s | 应用层从驱动Buffer读取数据速率,本次测试为217.99MB/s |
write_error/read_error | 写数据过程中出错次数,本次测试为0 | 读数据过程中出错次数,本次测试为0 |
-
FPGA
+关注
关注
1663文章
22494浏览量
638982 -
测试
+关注
关注
9文章
6376浏览量
131641 -
RK3568
+关注
关注
5文章
654浏览量
8104
发布评论请先 登录
瑞芯微RK3568J如何“调节主频”,实现功耗降低?一文教会您!

RK3568J“麒麟”+“翼辉”国产系统正式发布,“鸿蒙”也正在路上!
国产RK3568J基于FSPI的ARM+FPGA通信方案分享
3568F-ARM+FPGA通信案例开发手册
3568F--基于Pango Design Suite的FPGA程序加载与固化
3568F-FPGA案例开发手册
全国产!瑞芯微RK3568J/RK3568B2工业核心板规格书
请查收“国产化率认证报告”(100%)——RK3568J工业核心板
RK3568J“麒麟”+“翼辉”国产系统正式发布,“鸿蒙”也正在路上!
创龙科技的RK3568J工业核心板技术参数解析

实测780MB/s!基于RK3568J与FPGA的PCIe通信案例详解

RK3568J“麒麟”+“翼辉”国产系统正式发布,“鸿蒙”也正在路上!
全国产RK3568J + FPGA的PCIe、FSPI通信实测数据分享!
深度对比!瑞芯微RK3562J比RK3568J好在哪里?
瑞芯微 RK3568J 视频图像处理框架全解析



评论