 特征工程与数据预处理全解析:基础技术和代码示例
特征工程与数据预处理全解析:基础技术和代码示例
在机器学习和数据科学的世界里,数据的质量是建模成功与否的关键所在。这就是特征工程和数据预处理发挥作用的地方。本文总结的这些关键步骤可以显著提高模型的性能,获得更准确的预测,我们将深入研究处理异常值、缺失值、编码、特征缩放和特征提取的各种技术。
异常值异常值是数据集中与其他观测值显著不同的数据点。它们可能是由测量误差、罕见事件或仅仅是数据自然变化的一部分引起的。识别和处理异常值是至关重要的,因为它们会扭曲统计分析并对模型性能产生负面影响。
有几种方法可以检测异常值:1、视觉方法:箱形图、散点图、直方图2、统计方法:Z-score: Z-score > 3或< -3的点通常被认为是异常值。四分位间距(IQR):低于Q1-1.5 * IQR或高于Q3 + 1.5 *IQR的数据点通常被视为异常值。3、机器学习方法:孤立森林、单类SVM、局部离群因子(LOF)而最常用的方法之一是使用四分位间距(IQR)方法
def outlier_thresholds(dataframe, col_name, q1=0.25, q3=0.75): quartile1 = dataframe[col_name].quantile(q1) quartile3 = dataframe[col_name].quantile(q3) interquantile_range = quartile3 - quartile1 up_limit = quartile3 + 1.5 * interquantile_range low_limit = quartile1 - 1.5 * interquantile_range return low_limit, up_limit
def check_outlier(dataframe, col_name): low_limit, up_limit = outlier_thresholds(dataframe, col_name) if dataframe[(dataframe[col_name] > up_limit) | (dataframe[col_name] < low_limit)].any(axis=None): return True else: return False
该函数计算IQR并将异常值定义为低于Q1-1.5 * IQR或高于Q3 + 1.5 * IQR的数据点。这个方法简单快速,效果也很好。
异常值处理
1、删除离群值
删除异常值是一种直截了当的方法,但应该谨慎行事。只有在以下情况下才考虑删除:
确定异常值是由于数据错误造成的。
数据集足够大,删除几个点不会显著影响你的分析。
- 异常值不能代表正在研究的人群。
删除方法也很简单:
def remove_outlier(dataframe, col_name): low_limit, up_limit = outlier_thresholds(dataframe, col_name) df_without_outliers = dataframe[~((dataframe[col_name] < low_limit) | (dataframe[col_name] > up_limit))] return df_without_outliers
2、带阈值的重新分配可以将这些值限制在某个阈值,而不是删除。这种方法也被称为winsorization。以下是使用threshold重新赋值的代码示例:
def replace_with_thresholds(dataframe, variable): low_limit, up_limit = outlier_thresholds(dataframe, variable) dataframe.loc[(dataframe[variable] < low_limit), variable] = low_limit dataframe.loc[(dataframe[variable] > up_limit), variable] = up_limit
多元离群分析:局部离群因子
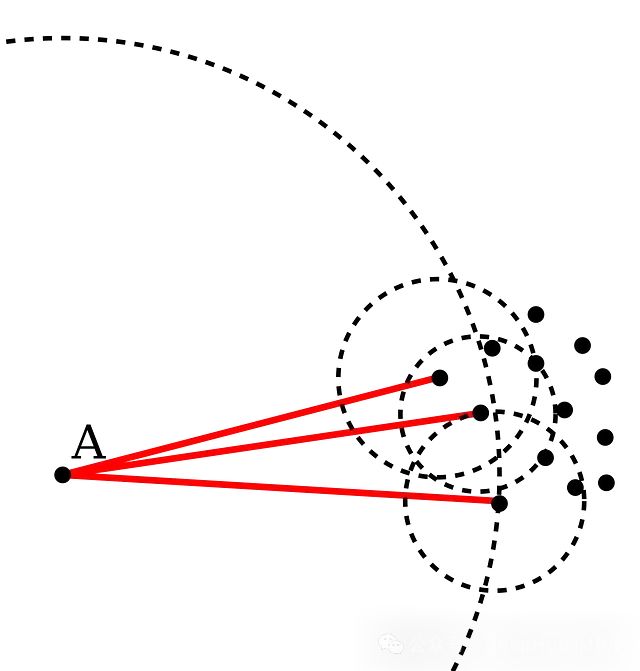 LOF算法:图像中的A点比其邻近点的密度更稀疏,距离更远。在这种情况下,可以说点A是一个异常值。
LOF算法:图像中的A点比其邻近点的密度更稀疏,距离更远。在这种情况下,可以说点A是一个异常值。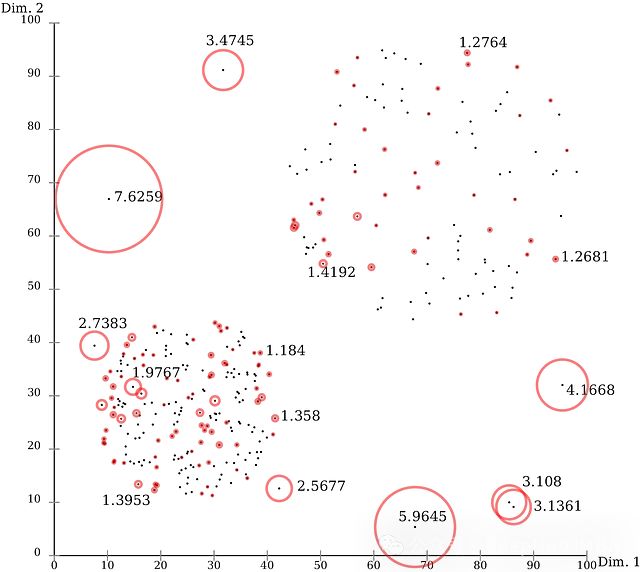 LOF是一种通过测量数据点相对于其邻居的局部偏差来识别异常值的算法。LOF将一个点的局部密度与其相邻点的局部密度进行比较,从而识别出密度明显低于相邻点的样本。以下是多元离群分析的代码示例:
LOF是一种通过测量数据点相对于其邻居的局部偏差来识别异常值的算法。LOF将一个点的局部密度与其相邻点的局部密度进行比较,从而识别出密度明显低于相邻点的样本。以下是多元离群分析的代码示例:
from sklearn.neighbors import LocalOutlierFactor
def detect_outliers_lof(data, n_neighbors=20): lof = LocalOutlierFactor(n_neighbors=n_neighbors, contamination='auto') outlier_labels = lof.fit_predict(data) return outlier_labels == -1 # True for outliers, False for inliers
缺失值缺失值是现实世界数据集中常见的问题,处理丢失数据时要考虑的一个重要问题是丢失数据的随机性。在Python中,你可以使用pandas轻松检测缺失值:
def missing_values_table(dataframe, na_name=False): na_columns = [col for col in dataframe.columns if dataframe[col].isnull().sum() > 0]
n_miss = dataframe[na_columns].isnull().sum().sort_values(ascending=False) ratio = (dataframe[na_columns].isnull().sum() / dataframe.shape[0] * 100).sort_values(ascending=False) missing_df = pd.concat([n_miss, np.round(ratio, 2)], axis=1, keys=['n_miss', 'ratio']) print(missing_df, end="\n")
if na_name: return na_columns
缺失值处理
1、删除缺失值:如果缺失值的数量相对于数据集大小较小,则删除可能是一种有效的策略。
def remove_missing(df, threshold=0.7): return df.dropna(thresh=int(threshold*len(df)), axis=1).dropna()
2、用简单的方法填充简单的插值方法包括用均值、中位数或众数填充:
def simple_impute(dataframe):
cat_cols = [col for col in dataframe.columns if dataframe[col].dtypes == "O"] num_but_cat = [col for col in dataframe.columns if dataframe[col].nunique() < cat_th and dataframe[col].dtypes != "O"] cat_but_car = [col for col in dataframe.columns if dataframe[col].nunique() > car_th and dataframe[col].dtypes == "O"] cat_cols = cat_cols + num_but_cat cat_cols = [col for col in cat_cols if col not in cat_but_car]
num_cols = [col for col in dataframe.columns if dataframe[col].dtypes != "O"] num_cols = [col for col in num_cols if col not in num_but_cat]
df[num_cols] = df[num_cols].fillna(df[num_cols].median()) df[cat_cols] = df[cat_cols].fillna(df[cat_cols].mode().iloc[0])
return df
3、分类变量分解中的值对于数值变量,可以根据相关分类变量的平均值或中位数填充缺失值:
def categorical_impute(df, col_1, col_2, method="mean"): df[col_1].fillna(df.groupby(col_2)[col_1].transform(method)) return df
4、预测赋值填充KNN Imputer (K-Nearest Neighbors Imputer)是一种处理数据集中缺失数据的方法:它基于k近邻算法。对于每个缺失值的样本,它找到K个最相似的完整样本。然后使用这些邻居的值来估计和填充缺失的数据。输入值通常是相邻值的平均值或中值。当丢失的数据不是随机的并且依赖于其他特征时,它特别有用。KNN Imputer比mean或median imputation等简单的imputation方法更准确,特别是对于特征之间的关系很重要的数据集。但是对于大型数据集来说,它的计算成本很高。
from sklearn.impute import KNNImputer
def knn_impute(dataframe, n_neighbors=5):
cat_cols = [col for col in dataframe.columns if dataframe[col].dtypes == "O"] num_but_cat = [col for col in dataframe.columns if dataframe[col].nunique() < cat_th and dataframe[col].dtypes != "O"] cat_but_car = [col for col in dataframe.columns if dataframe[col].nunique() > car_th and dataframe[col].dtypes == "O"] cat_cols = cat_cols + num_but_cat cat_cols = [col for col in cat_cols if col not in cat_but_car]
num_cols = [col for col in dataframe.columns if dataframe[col].dtypes != "O"] num_cols = [col for col in num_cols if col not in num_but_cat]
df = pd.get_dummies(dataframe[cat_cols + num_cols], drop_first=True)
# Standardization of Variables scaler = MinMaxScaler() df = pd.DataFrame(scaler.fit_transform(df), columns=df.columns) df.head()
# Implementation of KNN
imputer = KNNImputer(n_neighbors=n_neighbors)
return pd.DataFrame(imputer.fit_transform(df), columns=df.columns)
编码
编码是将分类变量转换为可以提供给机器学习算法使用的格式的过程。一般包括标签编码:为类别分配唯一的数字标签。独热编码:将分类变量转换为二进制向量。稀有编码:当一个分类变量有一些在数据集中很少出现的类别时,使用这种技术。这些编码有助于将各种数据类型转换为数字格式,使机器学习模型能够提取模式并更准确地进行预测。标签编码: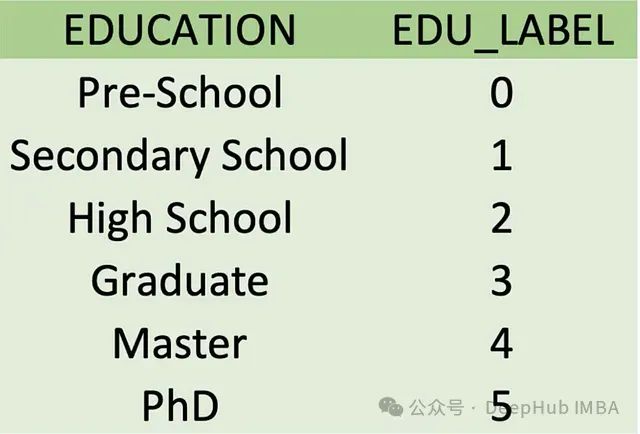 标签编码用于将分类数据转换为算法可以处理的数字格式。它的工作原理是为分类变量中的每个类别分配一个唯一的整数。此方法对于类别有自然顺序的有序数据特别有用,例如评级。但是标签编码可能会在不存在的类别之间引入人为的顺序关系,这对于某些算法来说可能是有问题的。
标签编码用于将分类数据转换为算法可以处理的数字格式。它的工作原理是为分类变量中的每个类别分配一个唯一的整数。此方法对于类别有自然顺序的有序数据特别有用,例如评级。但是标签编码可能会在不存在的类别之间引入人为的顺序关系,这对于某些算法来说可能是有问题的。
from sklearn.preprocessing import LabelEncoder
def label_encoder(dataframe, binary_col): labelencoder = LabelEncoder() dataframe[binary_col] = labelencoder.fit_transform(dataframe[binary_col]) return dataframe
binary_cols = [col for col in df.columns if df[col].dtype not in [int, float] and df[col].nunique() == 2]
for col in binary_cols: label_encoder(df, col)
独热编码:独热编码是一种用于数字表示分类数据的技术,适用于需要数字输入的机器学习算法。在这种方法中,特征中的每个唯一类别成为一个新的二进制列。对于给定的类别,相应的列被设置为1(或“hot”),而所有其他列都被设置为0。这种方法允许在不暗示类别之间的任何顺序关系的情况下表示类别变量。它在处理标称数据时特别有用,因为类别没有固有的顺序或层次结构。但是如果分类数据中的类别较多会增加稀疏性。
def one_hot_encoder(dataframe, categorical_cols, drop_first=True): dataframe = pd.get_dummies(dataframe, columns=categorical_cols, drop_first=drop_first) return dataframe
ohe_cols = [col for col in df.columns if 10 >= df[col].nunique() > 2]
one_hot_encoder(df, ohe_cols).head()
稀有编码: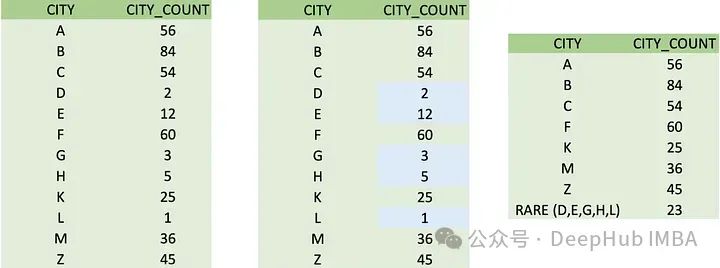 机器学习中的稀有编码通常是指用于处理分类变量中罕见或不常见类别的技术。当一个分类变量有一些在数据集中很少出现的类别时,使用这种技术可以防止过拟合,降低这些罕见类别给模型带来的噪声。
机器学习中的稀有编码通常是指用于处理分类变量中罕见或不常见类别的技术。当一个分类变量有一些在数据集中很少出现的类别时,使用这种技术可以防止过拟合,降低这些罕见类别给模型带来的噪声。
- 将不常见的类别分组:将不常见的类别合并到一个“其他”类别中。
- 基于频率的编码:用数据集中的频率替换稀有类别。
- 基于相似性的编码:根据与更常见的类别的相似性对罕见类别进行分组。
设置频率阈值(例如,少于1%的出现)来定义什么构成“罕见”类别。这样有助于降低模型的复杂性,改进泛化,并处理测试数据中未见过的类别。
cat_cols = [col for col in dataframe.columns if dataframe[col].dtypes == "O"] num_but_cat = [col for col in dataframe.columns if dataframe[col].nunique() < cat_th and dataframe[col].dtypes != "O"] cat_but_car = [col for col in dataframe.columns if dataframe[col].nunique() > car_th and dataframe[col].dtypes == "O"] cat_cols = cat_cols + num_but_cat cat_cols = [col for col in cat_cols if col not in cat_but_car]
def rare_analyser(dataframe, target, cat_cols): for col in cat_cols: print(col, ":", len(dataframe[col].value_counts())) print(pd.DataFrame({"COUNT": dataframe[col].value_counts(), "RATIO": dataframe[col].value_counts() / len(dataframe), "TARGET_MEAN": dataframe.groupby(col)[target].mean()}), end="\n\n\n")
rare_analyser(df, "TARGET", cat_cols)
def rare_encoder(dataframe, rare_perc): temp_df = dataframe.copy()
rare_columns = [col for col in temp_df.columns if temp_df[col].dtypes == 'O' and (temp_df[col].value_counts() / len(temp_df) < rare_perc).any(axis=None)]
for var in rare_columns: tmp = temp_df[var].value_counts() / len(temp_df) rare_labels = tmp[tmp < rare_perc].index temp_df[var] = np.where(temp_df[var].isin(rare_labels), 'Rare', temp_df[var])
return temp_df
new_df = rare_encoder(df, 0.01)
特征缩放
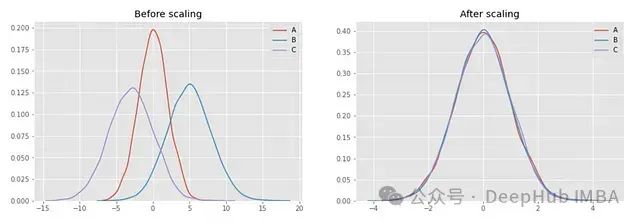 特征缩放是一种用于机器学习的预处理技术,用于标准化数据的自变量或特征的范围。因为特征在相同条件下可以减少算法的训练时间。当变量被标准化时,减少由缩放特征产生的误差的努力会更容易。因为在同一条件下可以确保所有特征对模型的性能贡献相同,防止较大的特征主导学习过程。这对输入特征的尺度敏感的算法尤其重要,例如基于梯度下降的算法和基于距离的算法。当特征处于相似规模时,许多机器学习算法表现更好或收敛更快。但是应分别应用于训练集和测试集,以避免数据泄漏。
特征缩放是一种用于机器学习的预处理技术,用于标准化数据的自变量或特征的范围。因为特征在相同条件下可以减少算法的训练时间。当变量被标准化时,减少由缩放特征产生的误差的努力会更容易。因为在同一条件下可以确保所有特征对模型的性能贡献相同,防止较大的特征主导学习过程。这对输入特征的尺度敏感的算法尤其重要,例如基于梯度下降的算法和基于距离的算法。当特征处于相似规模时,许多机器学习算法表现更好或收敛更快。但是应分别应用于训练集和测试集,以避免数据泄漏。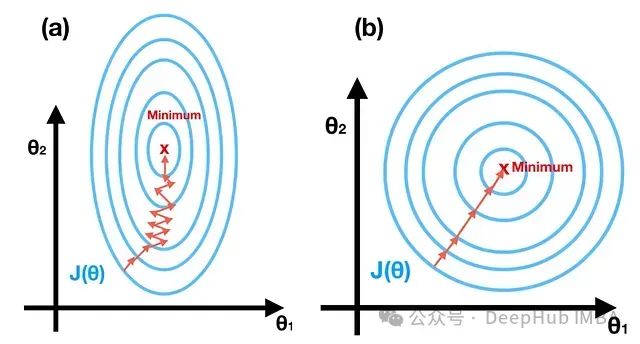 Standard Scaling标准化对特征进行缩放,使它们的均值为0,方差为1。
Standard Scaling标准化对特征进行缩放,使它们的均值为0,方差为1。
from sklearn.preprocessing import StandardScaler
def standard_scale(df, columns): scaler = StandardScaler() df[columns] = scaler.fit_transform(df[columns]) return df
Robust ScalingRobust Scaling使用对异常值具有鲁棒性的统计信息。
from sklearn.preprocessing import RobustScaler
def robust_scale(df, columns): scaler = RobustScaler() df[columns] = scaler.fit_transform(df[columns]) return df
Min-Max ScalingMinMax Scaling将特征缩放到一个固定的范围,通常在0到1之间。
from sklearn.preprocessing import MinMaxScaler
def minmax_scale(df, columns): scaler = MinMaxScaler() df[columns] = scaler.fit_transform(df[columns]) return df
分箱分箱是通过创建一组区间将连续变量转换为分类变量的过程。
import numpy as np
def binning(df, column, bins, labels=None): df[f'{column}_binned'] = pd.qcut(df[column], bins=bins, labels=labels) return df
特征提取
 特征提取是机器学习和数据分析中的一项重要技术。它包括选择原始数据并将其转换为一组更有用的特征,这些特征可用于进一步处理或分析。特征提取的目的是,降低数据的维数,这样可以简化模型,提高性能。文本统计特征创建二进制特征可以突出显示数据中的重要特征。
特征提取是机器学习和数据分析中的一项重要技术。它包括选择原始数据并将其转换为一组更有用的特征,这些特征可用于进一步处理或分析。特征提取的目的是,降低数据的维数,这样可以简化模型,提高性能。文本统计特征创建二进制特征可以突出显示数据中的重要特征。
def create_binary_feature(df, column, condition): df[f'{column}_flag'] = np.where(condition(df[column]), 1, 0) return df
例如对于下面的文本 文本数据通常包含有价值的信息,这些信息可以提取为数字特征。
文本数据通常包含有价值的信息,这些信息可以提取为数字特征。
# Letter Count
df["NEW_NAME_COUNT"] = df["Name"].str.len()
# Word Count
df["NEW_NAME_WORD_COUNT"] = df["Name"].apply(lambda x: len(str(x).split(" ")))
# Capturing Special Structures
df["NEW_NAME_DR"] = df["Name"].apply(lambda x: len([x for x in x.split() if x.startswith("Dr")]))
df.groupby("NEW_NAME_DR").agg({"Survived": ["mean","count"]})
# Deriving Variables with Regex
df['NEW_TITLE'] = df.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
df[["NEW_TITLE", "Survived", "AGE"]].groupby(["NEW_TITLE"]).agg({"Survived": "mean", "AGE": ["count", "mean"]})
时间序列变量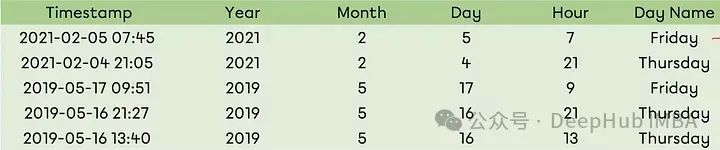 对于时间序列可以将日期变量分解为与分析相关的各种子组件。
对于时间序列可以将日期变量分解为与分析相关的各种子组件。
def date_features(df, date_column): df[f'{date_column}_year'] = df[date_column].dt.year df[f'{date_column}_month'] = df[date_column].dt.month df[f'{date_column}_day'] = df[date_column].dt.day df[f'{date_column}_dayofweek'] = df[date_column].dt.dayofweek return df
这样就可以针对不同的时间进行处理。
总结特征工程和数据预处理是任何机器学习中的关键步骤。它们可以通过确保数据干净、结构良好和信息丰富来显著提高模型的性能。本文介绍了如何处理异常值和缺失值、编码分类变量、缩放数值特征和创建新特征——为准备机器学习任务的数据奠定了坚实的基础。
我们这里也只是介绍一些简单常见的技术,使用更复杂和更具体技术将取决于数据集和试图解决的问题。
作者:Kursat Dinc
本文来源:DeepHub IMBA
-
检测
+关注
关注
5文章
4511浏览量
91714 -
机器学习
+关注
关注
66文章
8438浏览量
133007 -
数据预处理
+关注
关注
1文章
20浏览量
2797
发布评论请先 登录
相关推荐
数据预处理故障信息获取
全志R128芯片 如何在FreeRTOS下对代码源文件进行快速预处理?
dvteclipse代码预处理的简单操作方法推荐
机器学习算法学习之特征工程1

机器学习算法学习之特征工程2

机器学习算法学习之特征工程3







 工商网监
工商网监
评论