 Qwen2强势来袭,AIBOX支持本地化部署
Qwen2强势来袭,AIBOX支持本地化部署
Qwen2 是阿里通义推出的新一代多语言预训练模型,经过更深入的预训练和指令调整,在多个基准评测结果中表现出色,尤其在代码和数学方面有显著提升,同时拓展了上下文长度支持,最高可达128K。目前 AIBOX-1684X 已适配 Qwen2 系列模型,并已集成在 FireflyChat 对话应用中,开机即可体验。
模型基础更新
预训练和指令微调模型
Qwen2系列包含5个尺寸的预训练和指令微调模型,所有尺寸模型都使用了 GQA(分组查询注意力)机制,方便用户体验到推理加速和显存占用降低的优势。
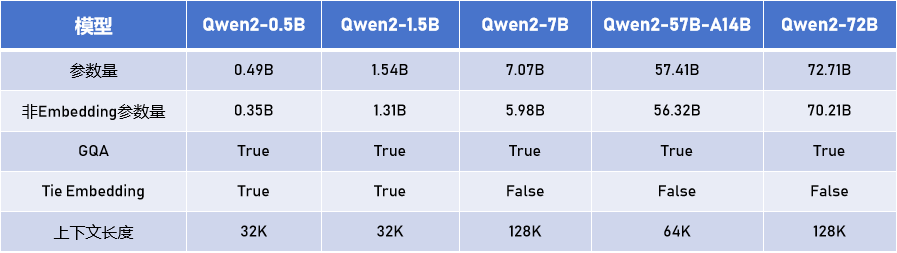
加强27种语言的训练数据
Qwen团队通过扩展多语言预训练和指令微调数据的规模,针对除中英文以外的27种语言进行加强,提升模型的多语言能力。

模型多方面测评

基准测评结果
相比 Qwen1.5,得益于预训练数据及训练方法的优化,Qwen2 在大模型实现大幅度的效果提升。在针对预训练语言模型的评估中,Qwen2-72B 在包括自然语言理解、知识、代码、数学及多语言等多项能力上均表现卓越。
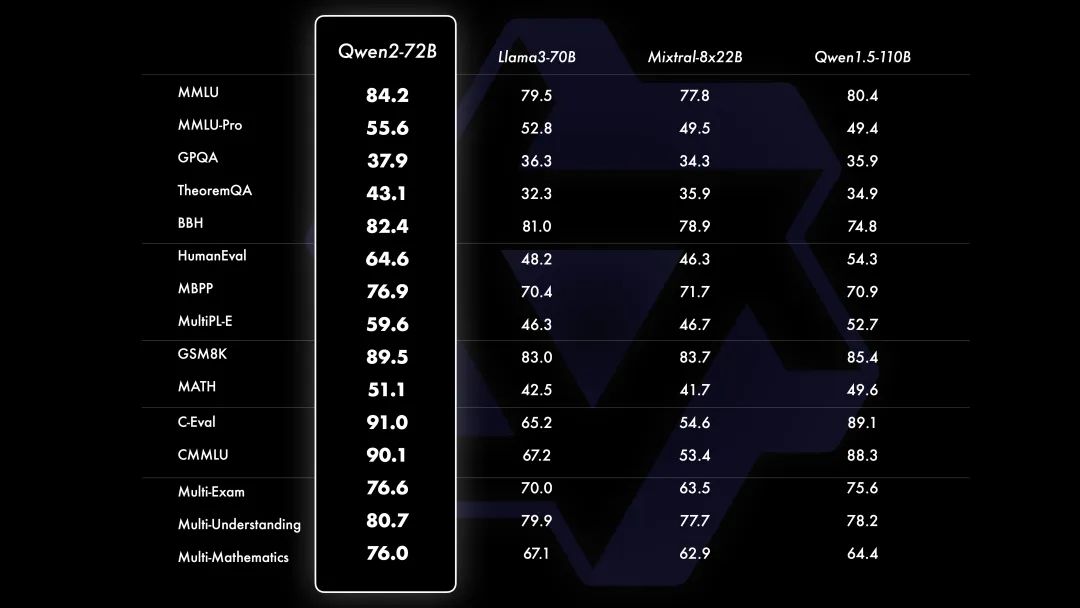
小模型方面,相比近期推出的领先模型,Qwen2-7B-Instruct 依然能在多个评测上取得显著的优势,尤其是代码及中文理解。
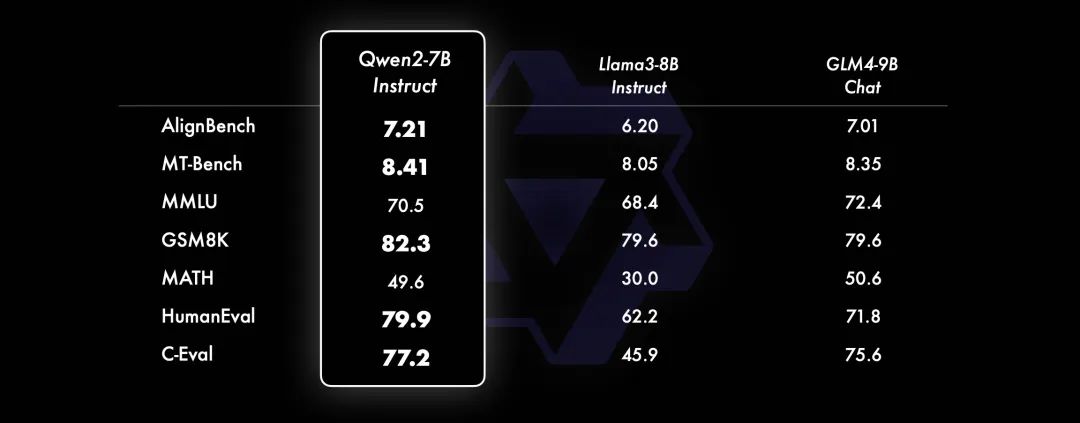
代码和数学能力显著提升
代码方面,沿用 Qwen1.5 的代码能力,实现 Qwen2 在多种编程语言上的效果提升;数学方面,投入了大规模且高质量的训练数据提升 Qwen2-72B-Instruct 的数学解题能力。

长文本处理
Qwen2 系列模型中较为关注的功能是它能够理解和处理扩展的上下文序列,对于冗长文档的应用程序,Qwen2 可以提供更准确、全面的响应,实现长文本自然语言高效处理。在Needle in a Haystack的测试集上显示:Qwen2-7B-Instruct 几乎完美地处理长达128k的上下文。
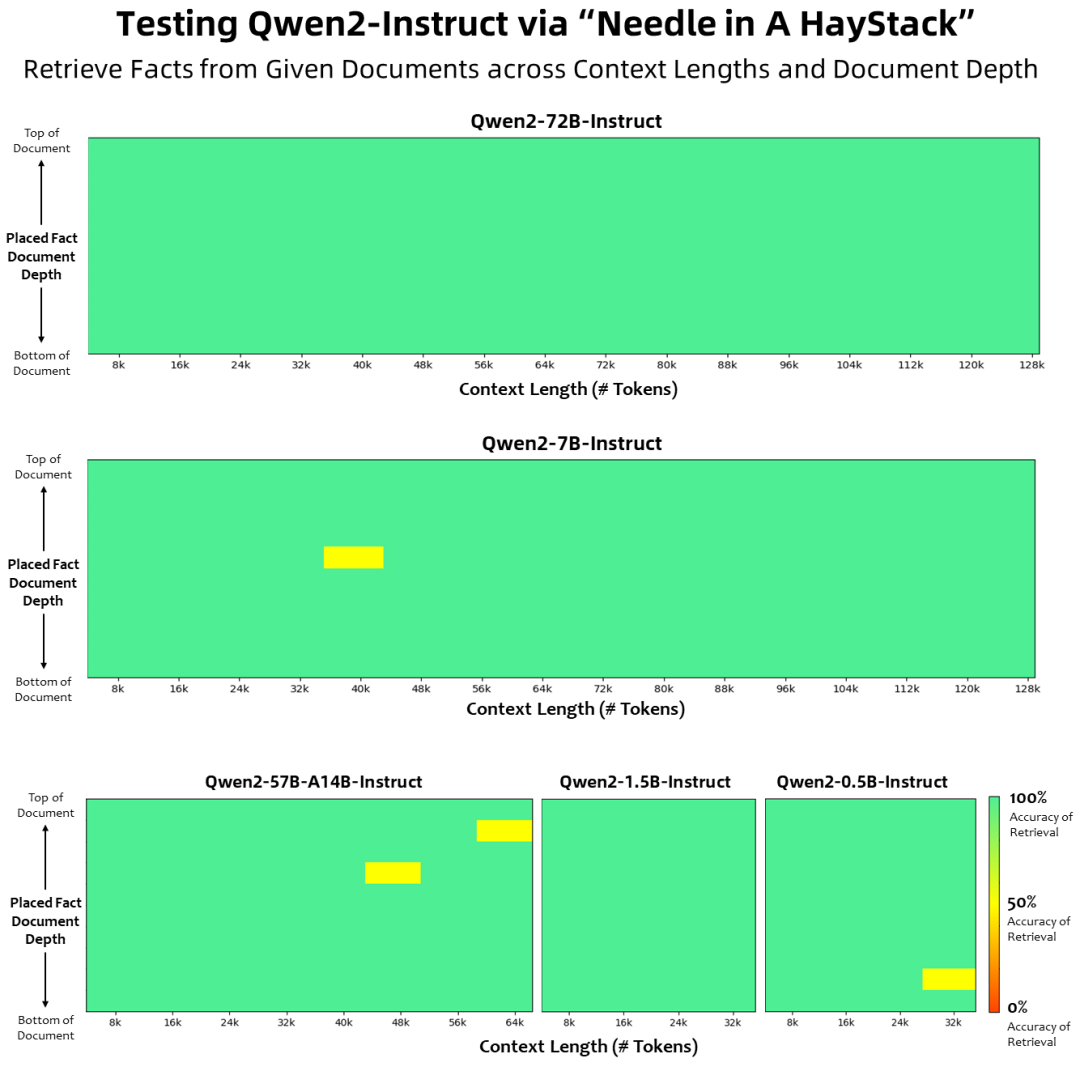
Qwen2-7B本地化部署
-
人工智能
+关注
关注
1791文章
47183浏览量
238252 -
模型
+关注
关注
1文章
3226浏览量
48807 -
语言模型
+关注
关注
0文章
520浏览量
10268
发布评论请先 登录
相关推荐
爱普生科技+本地化引领五大创新
Visual Components数字化工厂仿真软件本地化服务:亿达四方的优势
PerfXCloud重磅升级 阿里开源最强视觉语言模型Qwen2-VL-7B强势上线!
号称全球最强开源模型 ——Qwen2.5 系列震撼来袭!PerfXCloud同步上线,快来体验!
阿里Qwen2-Math系列震撼发布,数学推理能力领跑全球
AIBOX青春版上线!1399把AI带回家

基于Qwen-Agent与OpenVINO构建本地AI智能体

涂鸦HEDV本地化部署方案,助你低成本实现定制化开发!

阿里通义千问Qwen2大模型发布并同步开源
阿里通义千问Qwen2大模型发布
【AIBOX上手指南】快速部署Llama3
【AIBOX】装在小盒子的AI足够强吗?
AIBOX-1684X:把大语言模型“装”进小盒子
源2.0适配FastChat框架,企业快速本地化部署大模型对话平台






 工商网监
工商网监
评论