 如何训练和优化神经网络
如何训练和优化神经网络

一、引言
神经网络是人工智能领域的重要分支,广泛应用于图像识别、自然语言处理、语音识别等多个领域。然而,要使神经网络在实际应用中取得良好效果,必须进行有效的训练和优化。本文将从神经网络的训练过程、常用优化算法、超参数调整以及防止过拟合等方面,详细阐述如何训练和优化神经网络。
二、神经网络的训练过程
数据预处理
在训练神经网络之前,首先需要对数据进行预处理。数据预处理包括数据清洗、数据增强、数据归一化等操作。数据清洗旨在去除数据中的噪声和异常值;数据增强可以通过对原始数据进行变换(如旋转、缩放、翻转等)来增加数据的多样性;数据归一化则可以将数据缩放到同一尺度上,便于神经网络的学习。
前向传播
前向传播是神经网络训练的基础。在前向传播过程中,输入数据经过神经网络的各个层(包括输入层、隐藏层和输出层),逐层计算得到最终的输出。在前向传播过程中,每一层的输出都作为下一层的输入。通过前向传播,我们可以得到神经网络在给定输入下的预测输出。
计算损失函数
损失函数用于衡量神经网络的预测输出与真实输出之间的差异。常用的损失函数包括均方误差(MSE)、交叉熵损失(Cross-Entropy Loss)等。根据具体的任务和数据特点选择合适的损失函数是训练神经网络的关键之一。
反向传播
反向传播是神经网络训练的核心。在反向传播过程中,我们根据损失函数计算得到的梯度信息,从输出层开始逐层向前传播,更新神经网络中的权重和偏置参数。通过反向传播,我们可以不断优化神经网络的参数,使其更好地拟合训练数据。
三、常用优化算法
随机梯度下降(SGD)
随机梯度下降是最常用的优化算法之一。在SGD中,我们每次从训练数据中随机选取一个样本或一小批样本,计算其梯度并更新神经网络参数。SGD具有简单、高效的特点,但在实际应用中可能面临收敛速度慢、容易陷入局部最优解等问题。
动量(Momentum)
动量算法在SGD的基础上引入了动量项,使得参数更新具有一定的惯性。动量算法可以加速SGD的收敛速度,并在一定程度上缓解陷入局部最优解的问题。
Adam优化器
Adam优化器结合了Momentum和RMSprop的思想,通过计算梯度的一阶矩估计和二阶矩估计来动态调整学习率。Adam优化器具有自适应学习率、收敛速度快等特点,在实际应用中表现出较好的性能。
四、超参数调整
超参数是神经网络训练过程中需要手动设置的参数,如学习率、批次大小、迭代次数等。超参数的选择对神经网络的性能有着重要影响。常用的超参数调整方法包括网格搜索、随机搜索和贝叶斯优化等。在调整超参数时,需要根据具体任务和数据特点进行权衡和选择。
五、防止过拟合
过拟合是神经网络训练中常见的问题之一,表现为模型在训练数据上表现良好,但在测试数据上性能较差。为了防止过拟合,我们可以采取以下措施:
增加训练数据量:通过增加训练数据量可以提高模型的泛化能力,减少过拟合现象。
正则化:正则化是一种通过向损失函数中添加惩罚项来限制模型复杂度的方法。常用的正则化方法包括L1正则化、L2正则化和Dropout等。
提前停止:在训练过程中,当模型在验证集上的性能开始下降时,提前停止训练可以防止模型过拟合。
集成学习:集成学习通过将多个模型的预测结果进行组合来降低过拟合风险。常用的集成学习方法包括Bagging和Boosting等。
六、总结与展望
训练和优化神经网络是一个复杂而有趣的过程。通过合理的数据预处理、选择合适的优化算法、调整超参数以及采取防止过拟合的措施,我们可以使神经网络在实际应用中取得更好的性能。未来,随着深度学习技术的不断发展,我们有理由相信神经网络将在更多领域展现出其强大的潜力。同时,我们也需要关注神经网络训练过程中的一些挑战和问题,如计算资源消耗、模型可解释性等,为神经网络的进一步发展提供有力支持。
-
神经网络
+关注
关注
42文章
4844浏览量
108218 -
算法
+关注
关注
23文章
4810浏览量
98623 -
人工智能
+关注
关注
1821文章
50385浏览量
267117
发布评论请先 登录
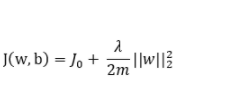
在Ubuntu20.04系统中训练神经网络模型的一些经验
粒子群优化模糊神经网络在语音识别中的应用
当训练好的神经网络用于应用的时候,权值是不是不能变了?
【案例分享】ART神经网络与SOM神经网络
如何构建神经网络?
matlab实现神经网络 精选资料分享
如何进行高效的时序图神经网络的训练
基于粒子群优化的条件概率神经网络的训练方法
Kaggle知识点:训练神经网络的7个技巧




评论