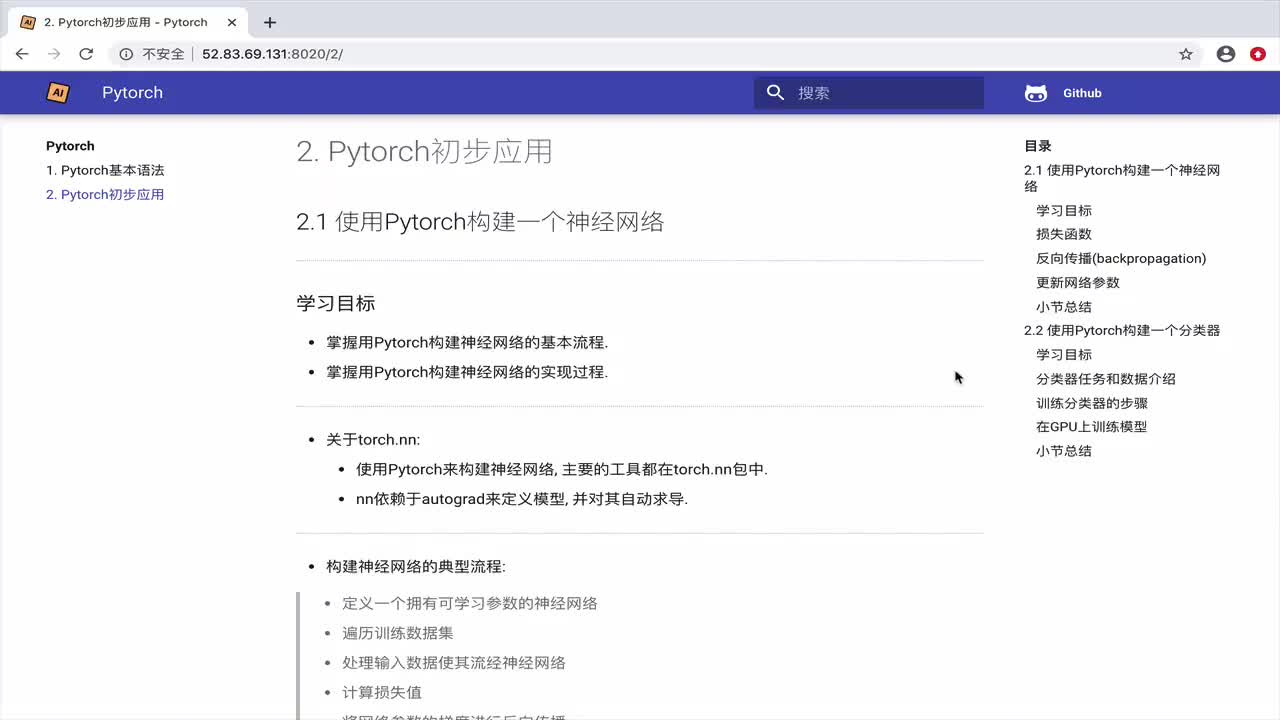
 使用PyTorch构建神经网络
使用PyTorch构建神经网络
PyTorch是一个流行的深度学习框架,它以其简洁的API和强大的灵活性在学术界和工业界得到了广泛应用。在本文中,我们将深入探讨如何使用PyTorch构建神经网络,包括从基础概念到高级特性的全面解析。本文旨在为读者提供一个完整的、技术性的指南,帮助理解并实践PyTorch在神经网络构建中的应用。
一、PyTorch基础
1.1 PyTorch简介
PyTorch由Facebook AI Research开发,是一个开源的机器学习库,它提供了强大的GPU加速和自动求导功能,非常适合用于构建和训练神经网络。PyTorch的设计哲学是“让事情变得简单且快速”,其动态计算图特性使得在调试和实验时更加灵活。
1.2 环境搭建
在开始使用PyTorch之前,需要确保已经安装了Python环境以及PyTorch库。PyTorch支持多种安装方式,包括pip安装、conda安装以及从源代码编译。以下是一个使用pip安装PyTorch的示例命令:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
注意,根据具体的CUDA版本和操作系统,可能需要安装不同版本的PyTorch。
二、神经网络基础
2.1 神经网络概述
神经网络是由多个神经元(也称为节点)相互连接而成的一种计算模型,它模仿了人类大脑处理信息的方式。神经网络可以分为输入层、隐藏层和输出层。每一层都包含一定数量的神经元,神经元之间通过权重和偏置进行连接。
2.2 激活函数
激活函数是神经网络中非常重要的组成部分,它决定了神经元是否应该被激活。常见的激活函数包括Sigmoid、ReLU、Tanh等。ReLU(Rectified Linear Unit)是目前最流行的激活函数之一,它具有计算简单、收敛速度快等优点。
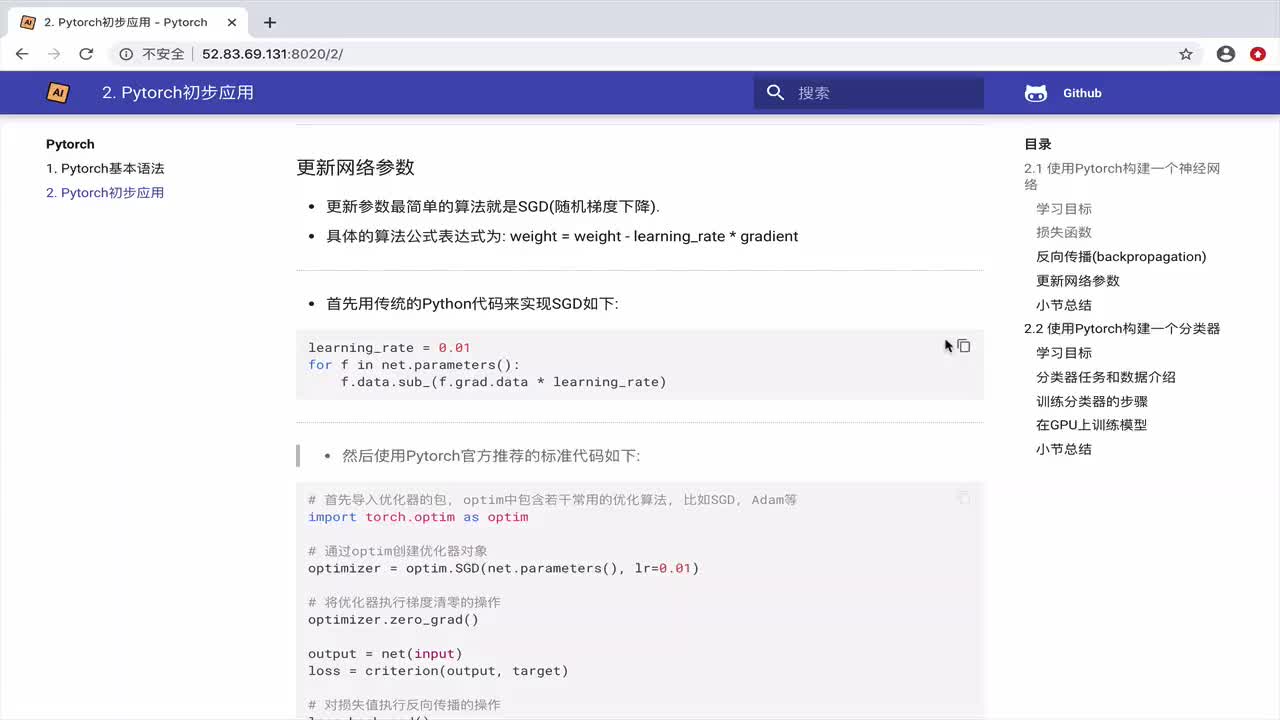
2.3 损失函数和优化器
损失函数用于衡量模型预测值与真实值之间的差距,常见的损失函数包括均方误差(MSE)、交叉熵损失(Cross Entropy Loss)等。优化器则用于更新模型的参数以最小化损失函数,常见的优化器包括SGD(随机梯度下降)、Adam等。
三、使用PyTorch构建神经网络
3.1 导入必要的库
在构建神经网络之前,首先需要导入PyTorch以及其他必要的库。以下是一个常见的导入语句示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
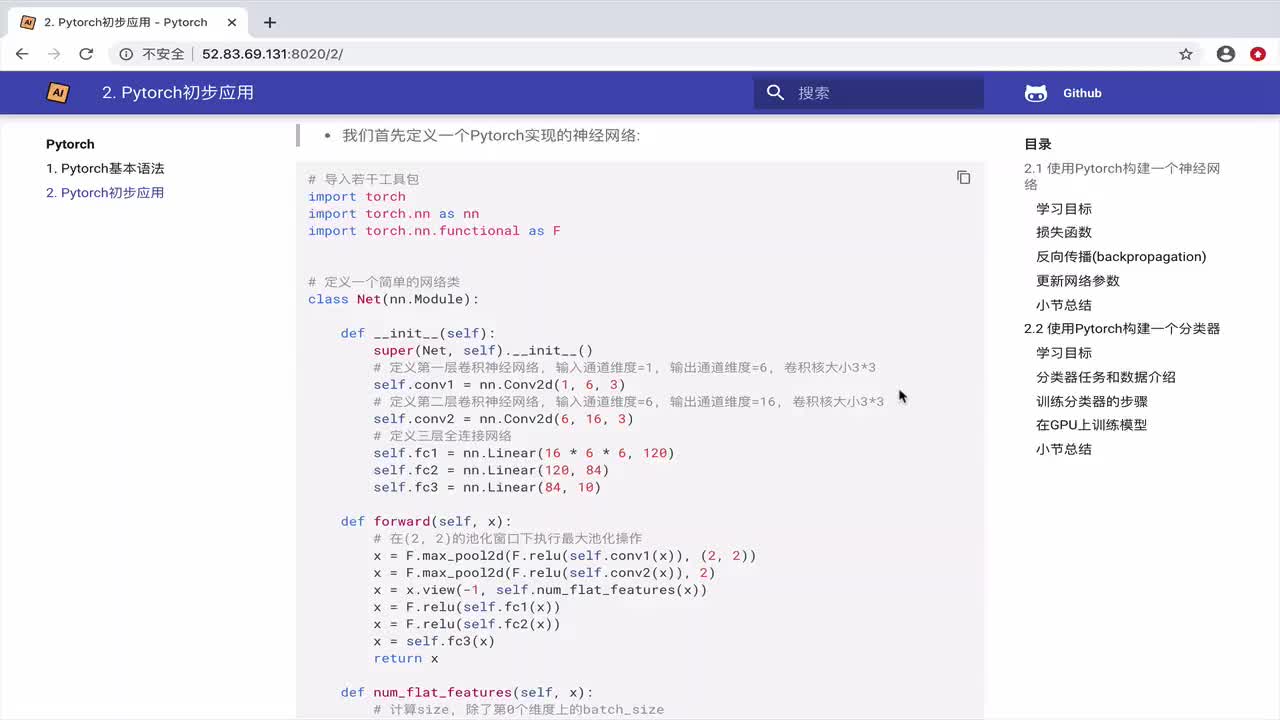
3.2 定义神经网络模型
在PyTorch中,神经网络模型通常通过继承nn.Module类来定义。在__init__方法中,我们定义网络的各个层;在forward方法中,我们定义数据的前向传播过程。以下是一个简单的全连接神经网络示例:
class NeuralNetwork(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(NeuralNetwork, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
3.3 数据加载和预处理
在训练神经网络之前,需要加载和预处理数据。PyTorch提供了torchvision.datasets和torch.utils.data.DataLoader来方便地加载和预处理数据。以下是一个使用MNIST数据集的示例:
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)
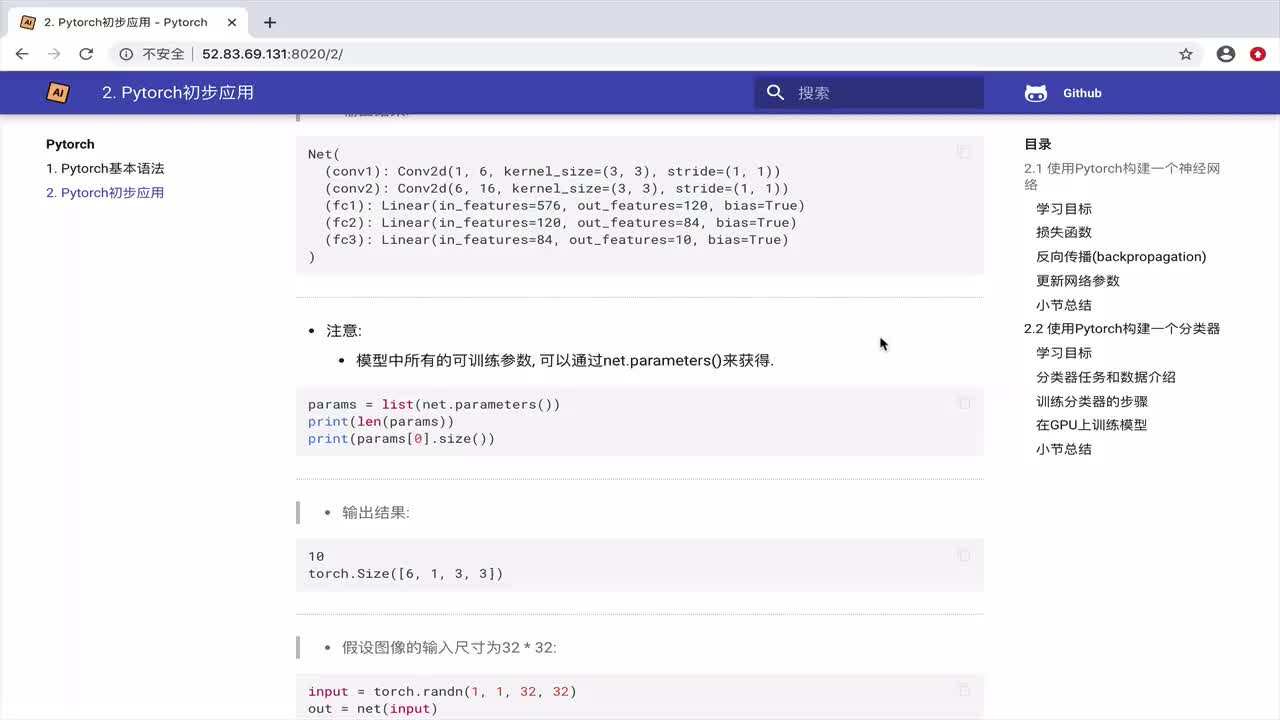
3.4 初始化模型、损失函数和优化器
在定义好神经网络模型后,需要初始化模型、损失函数和优化器。以下是一个示例:
model = NeuralNetwork(input_size=784, hidden_size=128, num_classes=10).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.
3.5 训练模型
模型训练是神经网络构建过程中最关键的一步。在PyTorch中,我们通常通过迭代训练数据集来训练模型,并在每个迭代中执行前向传播、计算损失、执行反向传播以及更新模型参数。以下是一个训练模型的典型流程:
# 确保设备正确设置,以利用GPU(如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 将模型和数据移至设备
model = model.to(device)
# 训练循环
num_epochs = 5
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# 将输入数据移至设备
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad() # 清除之前的梯度
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新权重
# 打印训练信息(可选)
if (i+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}')
### 3.6 评估模型
训练完成后,我们需要评估模型在测试集上的性能。评估过程与训练过程类似,但不包含反向传播和参数更新步骤。
```python
# 评估模型
model.eval() # 设置模型为评估模式
with torch.no_grad(): # 禁用梯度计算,节省内存和计算时间
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100 * correct // total}%')
### 3.7 保存和加载模型
在训练完成后,我们通常会将模型保存到文件中,以便将来进行预测或进一步训练。PyTorch提供了`torch.save`函数来保存模型。
```python
# 保存模型
torch.save(model.state_dict(), 'model.pth')
# 加载模型
model = NeuralNetwork(input_size=784, hidden_size=128, num_classes=10).to(device)
model.load_state_dict(torch.load('model.pth'))
model.eval()
四、PyTorch进阶特性
4.1 自动求导(Autograd)
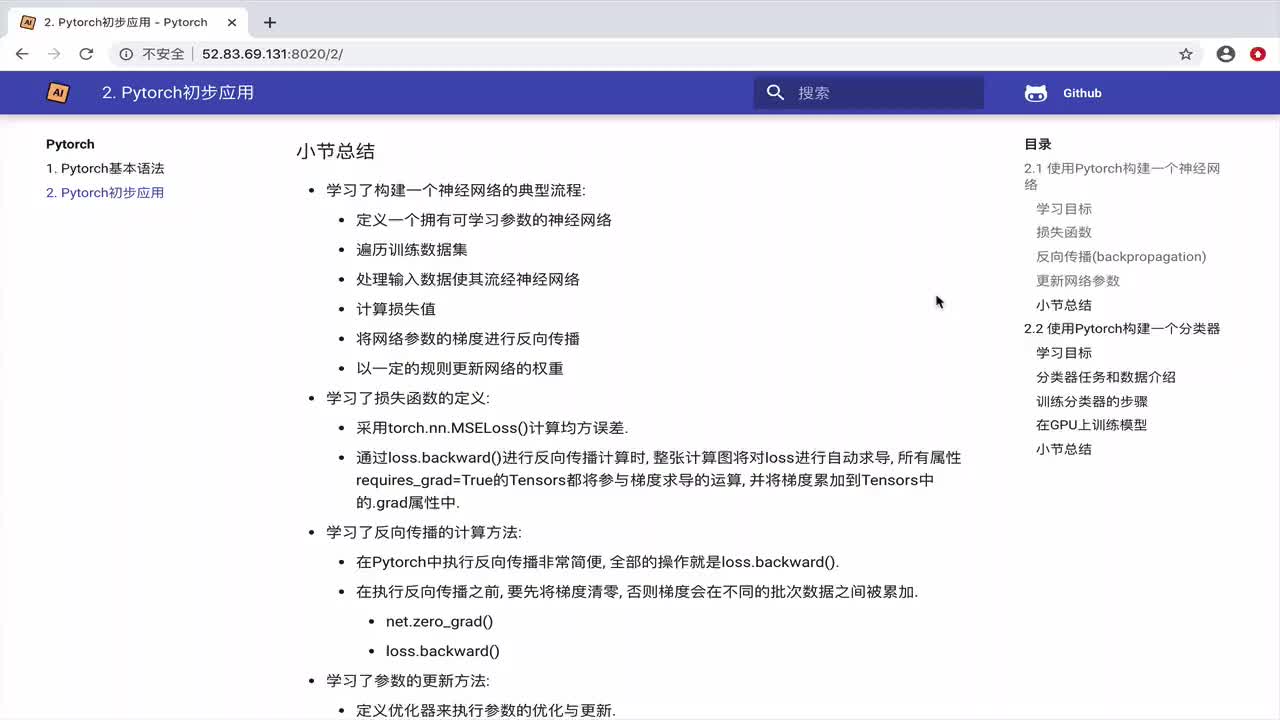
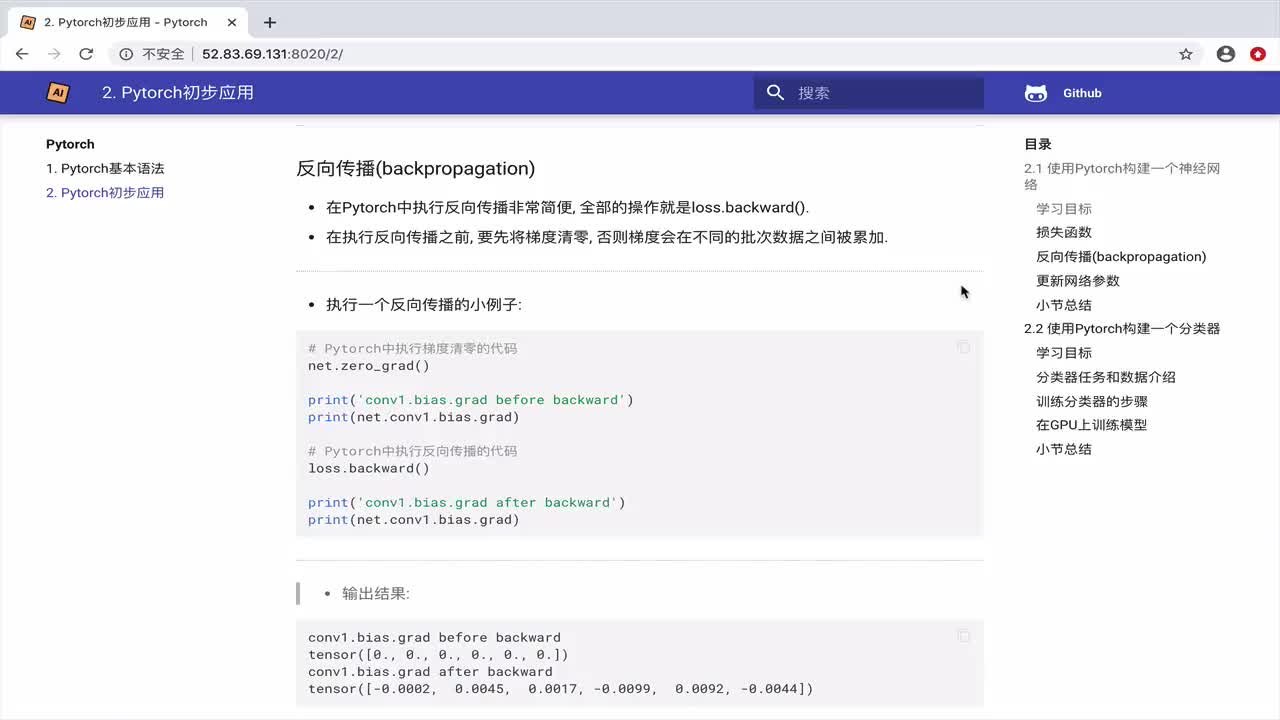
PyTorch的自动求导系统autograd是神经网络训练过程中的核心。它能够自动计算梯度,极大地简化了神经网络的实现。在上面的例子中,我们并没有直接操作梯度,而是调用了loss.backward()来自动计算梯度,并通过optimizer.step()来更新参数。
4.2 动态计算图
与TensorFlow等静态计算图框架不同,PyTorch使用动态计算图。这意味着计算图是在运行时构建的,这使得PyTorch在调试和实验时更加灵活。然而,这也意味着PyTorch在某些情况下可能不如静态计算图框架高效。
4.3 分布式训练
随着模型和数据集规模的不断增大,分布式训练变得越来越重要。PyTorch提供了强大的分布式训练支持,包括数据并行、模型并行等多种策略。通过torch.nn.parallel和torch.distributed模块,用户可以轻松实现分布式训练。
4.4 自定义层和模块
PyTorch的nn.Module基类提供了高度的灵活性,允许用户定义自己的层和模块。这使得PyTorch能够轻松地适应各种复杂的神经网络架构和特殊需求。
五、PyTorch的高级特性和技巧
5.1 模型剪枝和量化
为了将模型部署到资源受限的设备上(如手机或嵌入式设备),模型剪枝和量化是两种常用的技术。剪枝涉及移除模型中不重要的权重,而量化则是将模型中的浮点数权重和激活转换为较低精度的整数。PyTorch通过torch.quantization模块提供了对模型量化和剪枝的支持。
5.2 模型的可视化
理解复杂的神经网络结构对于调试和性能优化至关重要。PyTorch没有内置的直接模型可视化工具,但你可以使用第三方库如TensorBoard(虽然它原本是为TensorFlow设计的,但也可以与PyTorch一起使用)或torchviz来可视化模型的结构和计算图。
6.3 迁移学习
迁移学习是一种将在一个任务上学到的知识应用到另一个相关但不同的任务上的技术。在PyTorch中,你可以很容易地加载预训练的模型(如ResNet、VGG等),并在自己的数据集上进行微调。这可以显著提高模型在新任务上的性能,同时减少训练时间和所需的数据量。
5.4 自定义损失函数
虽然PyTorch提供了许多常用的损失函数(如交叉熵损失、均方误差损失等),但在某些情况下,你可能需要定义自己的损失函数。在PyTorch中,你可以通过继承torch.nn.Module类并实现forward方法来定义自己的损失函数。
5.5 使用混合精度训练
混合精度训练是一种利用半精度(FP16)或更低精度(如FP8或INT8)来加速训练过程的技术。虽然较低精度的计算可能会导致数值稳定性问题,但现代GPU对半精度计算进行了优化,可以显著加快训练速度。PyTorch通过torch.cuda.amp(自动混合精度)模块提供了对混合精度训练的支持。
5.6 分布式训练的高级技巧
除了基本的数据并行之外,PyTorch还支持更复杂的分布式训练策略,如模型并行和流水线并行。这些策略可以在多个GPU或多个节点之间更细粒度地划分模型和计算任务,以进一步提高训练速度和扩展性。
5.7 使用PyTorch进行强化学习
虽然PyTorch主要是一个深度学习库,但它也可以与强化学习框架(如PyTorch Lightning、Ray RLlib等)结合使用来构建和训练强化学习模型。强化学习是一种通过与环境交互来学习最优行为策略的机器学习方法,它在游戏、机器人和自动驾驶等领域有广泛应用。
六、PyTorch生态系统
PyTorch生态系统包含了许多围绕PyTorch构建的库和工具,这些库和工具提供了额外的功能和便利性,以帮助用户更高效地开发深度学习应用。以下是一些重要的PyTorch生态系统组件:
- PyTorch Lightning :一个高级框架,旨在简化PyTorch代码并加速研究。它提供了训练循环的抽象、模型保存和加载、日志记录等功能。
- TorchServe :一个用于部署PyTorch模型的灵活、可扩展的服务器。它支持多种部署场景,包括实时推理和批量处理。
- TorchVision :一个包含常用数据集、模型架构和图像转换的库。它简化了图像和视频数据的加载和预处理过程。
- TorchAudio :一个用于音频和音乐应用的库,提供了音频数据的加载、预处理和增强等功能。
- TorchText :一个用于自然语言处理的库,提供了文本数据的加载、预处理和词嵌入等功能。
通过利用这些库和工具,你可以更轻松地构建、训练和部署深度学习模型,而无需从头开始编写所有代码。
希望这些额外的内容能够帮助你更深入地了解PyTorch及其生态系统。随着你不断学习和实践,你将能够掌握更多高级特性和技巧,并更高效地利用PyTorch来构建深度学习应用。
七、结论
PyTorch是一个功能强大且灵活的深度学习框架,它以其简洁的API和动态计算图特性在学术界和工业界得到了广泛应用。在本文中,我们深入探讨了使用PyTorch构建神经网络的过程,包括基础概念、数据加载与预处理、模型定义与训练、评估以及进阶特性等方面。希望这些内容能够帮助读者更好地理解PyTorch,并在实际项目中灵活应用。
-
神经网络
+关注
关注
42文章
4785浏览量
101290 -
机器学习
+关注
关注
66文章
8455浏览量
133186 -
pytorch
+关注
关注
2文章
808浏览量
13404
发布评论请先 登录
相关推荐

如何构建神经网络?
基于PyTorch的深度学习入门教程之使用PyTorch构建一个神经网络
PyTorch教程8.1之深度卷积神经网络(AlexNet)






 工商网监
工商网监
评论