 在NVIDIA Holoscan SDK中使用OpenCV构建零拷贝AI传感器处理管线
在NVIDIA Holoscan SDK中使用OpenCV构建零拷贝AI传感器处理管线
NVIDIA Holoscan 是 NVIDIA 的跨领域多模态实时 AI 传感器处理平台,为开发者构建端到端传感器处理管线奠定了基础。NVIDIA Holoscan SDK 的功能包括:
具有低延迟传感器和网络连接的组合硬件系统
专为数据处理和 AI 优化的库
灵活部署:边缘或云端
Holoscan SDK 可用于为一系列行业和用例构建流式 AI 管线,包括医疗设备、边缘高性能计算和工业检测等。欲了解更多信息,请参阅利用 NVIDIA Holoscan 1.0 开发生产就绪型 AI 传感器处理应用。
Holoscan SDK 利用软硬件加速流式 AI 应用。它可以与 RDMA 技术配合使用,通过 GPU 加速功能进一步提高端到端管线性能。端到端传感器处理管线通常包括:
传感器数据输入
加速计算和 AI 推理
实时可视化、执行和数据流出口
该管线中的所有数据均存储在 GPU 内存中,Holoscan 原生运算符无需进行主机-设备内存传输,就可以直接访问这些数据。

图 1. 超声波分割应用的典型管线
本文将介绍如何通过集成 Holoscan SDK 和开源库 OpenCV,实现无需额外内存传输的端到端 GPU 加速工作流。
什么是 OpenCV?
OpenCV(开源计算机视觉库)是一个综合全面的开源计算机视觉库。它包含 2500 多种算法,例如图像和视频处理、物体和人脸检测,以及 OpenCV 深度学习模块等。
OpenCV 支持 GPU 加速功能,包含一个 CUDA 模块。该模块提供了一组利用 CUDA 计算能力的类和函数,它通过 NVIDIA CUDA 运行时 API 实现,能够提供各种实用功能、底层视觉原语和高级算法。
借助 OpenCV 提供的综合全面的 GPU 加速算法和运算符,开发者可以基于 Holoscan SDK 实现更加复杂的管线(图 2)。
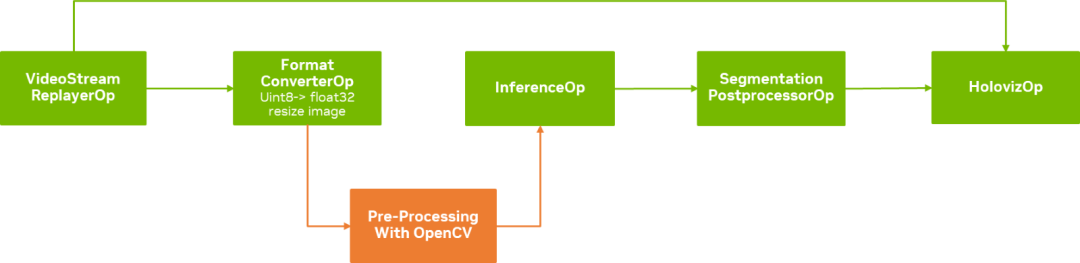
图 2. 基于 OpenCV 和 Holoscan SDK
的增强型超声波分割管线
在 Holoscan SDK 管线中
集成 OpenCV 运算符
如要开始在 Holoscan SDK 管线中集成 OpenCV 运算符,您需要满足以下条件:
OpenCV >= 4.8.0
Holoscan SDK >= v0.6
如要安装带有 CUDA 模块的 OpenCV,请遵循 opencv/opencv_contrib 提供的指南。如要使用 Holoscan SDK 和 OpenCV CUDA 构建镜像,请参阅 nvidia-holoscan/holohub Dockerfile:
https://github.com/nvidia-holoscan/holohub/blob/main/applications/endoscopy_depth_estimation/Dockerfile
张量是 Holoscan SDK 中的数据类型,它被定义为单一数据类型的多维元素数组。张量类是 DLManagedTensorCtx 结构的包装器,DLManagedTensorCtx 结构持有 DLManagedTensor 对象。张量类支持 DLPack 和 NumPy 数组接口(__array_interface__ 和 __cuda_array_interface__),因此可以与其他 Python 库(如 CuPy、PyTorch、JAX、TensorFlow 和 Numba)一起使用。
但 OpenCV 的数据类型是 GpuMat,它既没有实现 __cuda_array_interface_,也没有实现标准 DLPack。如要实现端到端 GPU 加速管线或应用,需要实现两个函数来将 GpuMat 转换为 CuPy 数组,后者可以直接使用 Holoscan Tensor 访问,反之亦然。
从 GpuMat 到 CuPy
数组的无缝零拷贝
OpenCV Python 绑定的 GpuMat 对象提供了一个 cudaPtr 方法,该方法可用于访问 GpuMat 对象的 GPU 内存地址。该内存指针可用于直接初始化 CuPy 数组,从而避免主机和设备之间发生不必要的数据传输,实现高效率的数据处理。
下面的函数用于从 GpuMat 创建 CuPy 数组。HoloHub 内窥镜深度估计应用提供了源代码。
importcv2
import cupy as cp
def gpumat_to_cupy(gpu_mat: cv2.cuda.GpuMat) -> cp.ndarray:
w, h = gpu_mat.size()
size_in_bytes = gpu_mat.step * w
shapes = (h, w, gpu_mat.channels())
assert gpu_mat.channels() <=3, "Unsupported GpuMat channels"
dtype = None
if gpu_mat.type() in [cv2.CV_8U,cv2.CV_8UC1,cv2.CV_8UC2,cv2.CV_8UC3]:
dtype = cp.uint8
elif gpu_mat.type() == cv2.CV_8S:
dtype = cp.int8
elif gpu_mat.type() == cv2.CV_16U:
dtype = cp.uint16
elif gpu_mat.type() == cv2.CV_16S:
dtype = cp.int16
elif gpu_mat.type() == cv2.CV_32S:
dtype = cp.int32
elif gpu_mat.type() == cv2.CV_32F:
dtype = cp.float32
elif gpu_mat.type() == cv2.CV_64F:
dtype = cp.float64
assert dtype is not None, "Unsupported GpuMat type"
mem = cp.cuda.UnownedMemory(gpu_mat.cudaPtr(), size_in_bytes, owner=gpu_mat)
memptr = cp.cuda.MemoryPointer(mem, offset=0)
cp_out = cp.ndarray(
shapes,
dtype=dtype,
memptr=memptr,
strides=(gpu_mat.step, gpu_mat.elemSize(), gpu_mat.elemSize1()),
)
return cp_out
请注意,我们在此函数中使用了非自有内存 API 创建 CuPy 数组。在某些情况下,OpenCV 运算符会创建一个需要由 CuPy 处理的新设备内存,其生命周期不限于一个运算符,而是整个管线。在这种情况下,从 GpuMat 启动的 CuPy 数组会知道所有者并保留对对象的引用。更多详情,请参阅 CuPy 互操作性文档:
https://docs.cupy.dev/en/stable/user_guide/interoperability.html#device-memory-pointers
从 Holoscan Tensor 到
GpuMat 的无缝零拷贝
随着 OpenCV 4.8 的发布,OpenCV 的 Python 绑定现在支持直接从 GPU 内存指针初始化 GpuMat 对象。这一功能通过与 GPU 驻留数据直接交互,来提高数据整合和处理效率,避免了主机和设备内存之间的数据传输。
在基于 Holoscan SDK 的管线应用中,可以通过 CuPy 数组提供的 __cuda_array_interface__ 获取 GPU 内存指针。请参考下面概述的函数,了解如何利用 CuPy 数组创建 GpuMat 对象。有关实现详情,请参见HoloHub 内窥镜深度估计应用中提供的源代码:
https://github.com/nvidia-holoscan/holohub/blob/main/applications/endoscopy_depth_estimation/endoscopy_depth_estimation.py#L28
import cv2
import cupy as cp
def gpumat_from_cp_array(arr: cp.ndarray) -> cv2.cuda.GpuMat:
assert len(arr.shape) in (2, 3), "CuPy array must have 2 or 3 dimensions to be a valid GpuMat"
type_map = {
cp.dtype('uint8'): cv2.CV_8U,
cp.dtype('int8'): cv2.CV_8S,
cp.dtype('uint16'): cv2.CV_16U,
cp.dtype('int16'): cv2.CV_16S,
cp.dtype('int32'): cv2.CV_32S,
cp.dtype('float32'): cv2.CV_32F,
cp.dtype('float64'): cv2.CV_64F
}
depth = type_map.get(arr.dtype)
assert depth is not None, "Unsupported CuPy array dtype"
channels = 1 if len(arr.shape) == 2 else arr.shape[2]
mat_type = depth + ((channels - 1) << 3)
mat = cv2.cuda.createGpuMatFromCudaMemory(
arr.__cuda_array_interface__['shape'][1::-1],
mat_type,
arr.__cuda_array_interface__['data'][0]
)
return mat
整合 OpenCV 运算符
有了上述两个函数,您就可以在基于 Holoscan SDK 的管线中进行任何 OpenCV-CUDA 操作,而无需进行内存传输。实现步骤如下:
在调用 OpenCV 运算符的位置创建自定义运算符。详情参见 Holoscan SDK 示例文档:
https://docs.nvidia.com/holoscan/sdk-user-guide/holoscan_create_operator.html#creating-a-custom-operator-python
在运算符的计算函数中:
a.接收前一个运算符的信息,并从HoloscanTensor创建一个CuPy 数组
b.调用gpumat_from_cp_array以创建GpuMat
c.使用自定义OpenCV运算符进行处理
d.调用gpumat_to_cupy,从GpuMat创建CuPy数组
请看下面的演示代码。完整的源代码请参见 HoloHub 内窥镜深度估计应用:
https://github.com/nvidia-holoscan/holohub/blob/main/applications/endoscopy_depth_estimation/endoscopy_depth_estimation.py#L161
defcompute(self,op_input,op_output,context):
stream = cv2.cuda_Stream()
message = op_input.receive("in")
cp_frame = cp.asarray(message.get("")) # CuPy array
cv_frame = gpumat_from_cp_array(cp_frame) # GPU OpenCV mat
## Call OpenCV Operator
cv_frame = cv2.cuda.XXX(hsv_merge, cv2.COLOR_HSV2RGB)
cp_frame = gpumat_to_cupy(cv_frame)
cp_frame = cp.ascontiguousarray(cp_frame)
out_message = Entity(context)
out_message.add(hs.as_tensor(cp_frame), "")
op_output.emit(out_message,"out")
总结
要将 OpenCV CUDA 运算符集成到基于 Holoscan SDK 构建的应用中,只需要实现两个函数即可促成 OpenCV GpuMat 和 CuPy 数组间的转换。借助这两个函数,您可以在自定义运算符中直接访问 Holoscan Tensors。通过调用这些函数,您可以无缝创建端到端 GPU 加速应用,而不再需要通过内存传输来提高性能。
-
传感器
+关注
关注
2557文章
51975浏览量
760373 -
NVIDIA
+关注
关注
14文章
5168浏览量
105180 -
OpenCV
+关注
关注
31文章
638浏览量
42091
原文标题:在 NVIDIA Holoscan SDK 中使用 OpenCV 构建零拷贝 AI 传感器处理管线
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何使用SDK在独立模式下的OpenCV应用程序
NVIDIA Jetson的相关资料分享
NVIDIA DRIVE OS 5.2.6 Linux SDK发布 为加速计算和AI而设计
NVIDIA 发布适用于医疗设备和计算传感系统的 AI 计算平台

NVIDIA发布Clara Holoscan MGX医疗级平台
使用Clara Holoscan SDK增强AI医疗设备流式处理工作流
使用 NVIDIA DeepStream SDK 6.2 顺利开发视觉 AI 应用
使用NVIDIA Holoscan for Media构建下一代直播媒体应用
利用NVIDIA Holoscan 1.0开发生产就绪型AI传感器处理应用
NVIDIA发布DeepStream 7.0,助力下一代视觉AI开发
NVIDIA 通过 Holoscan 为 NVIDIA IGX 提供企业软件支持,实现边缘实时医疗、工业和科学 AI 应用






 工商网监
工商网监
评论