 卷积神经网络的基本结构和训练过程
卷积神经网络的基本结构和训练过程

卷积神经网络(Convolutional Neural Networks,CNN)是一种在图像识别、视频处理、自然语言处理等多个领域广泛应用的深度学习算法。其独特的网络结构和算法设计,使得CNN在处理具有空间层次结构的数据时表现出色。本文将从卷积神经网络的历史背景、基本原理、网络结构、训练过程以及应用领域等方面进行详细阐述,以期全面解析这一重要算法。
一、卷积神经网络的历史背景
卷积神经网络的发展可以追溯到1962年,Hubel和Wiesel通过对猫视觉皮层细胞的研究,提出了感受野(receptive field)的概念。这一概念为后来卷积神经网络的发展奠定了理论基础。1984年,日本学者Fukushima基于感受野概念提出了神经认知机(neocognitron),这可以看作是卷积神经网络的第一个实现网络。然而,真正使卷积神经网络声名大噪的是1998年Yann LeCun提出的LeNet-5,该网络将BP算法应用到神经网络结构的训练上,形成了当代卷积神经网络的雏形。
二、卷积神经网络的基本原理
卷积神经网络的核心操作是卷积(convolution),这是一种信号处理中的数学运算,将两个函数进行叠加并积分,得到一个新的函数。在CNN中,卷积的输入通常是一个二维矩阵(如图像)和一个卷积核(也称为滤波器)。卷积核是一个小的二维矩阵,其内部的数值需要通过训练学习得到。卷积操作通过滑动窗口的方式在输入矩阵上进行,对应位置的元素相乘并相加,得到输出矩阵。此外,卷积神经网络还常常使用填充(padding)和步长(stride)来控制输出矩阵的大小。
三、卷积神经网络的网络结构
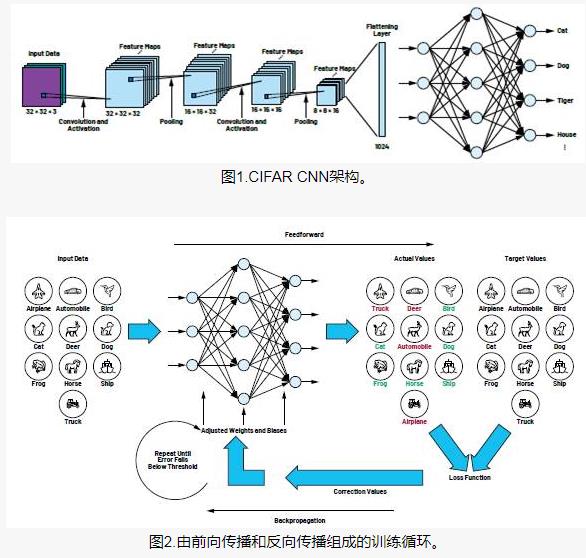
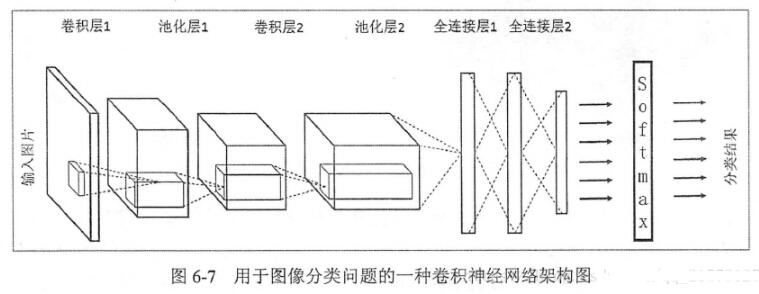
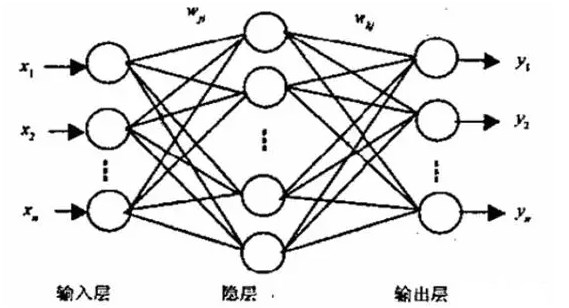
卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。典型的卷积神经网络结构包括卷积层(Convolutional Layer)、激活层(Activation Layer)、池化层(Pooling Layer)和全连接层(Fully Connected Layer)。
- 卷积层 :卷积层是CNN的核心,主要负责提取输入数据的特征。每个卷积层包含多个卷积核,每个卷积核与输入数据进行卷积运算,生成对应的特征图(Feature Map)。卷积核的大小和数量决定了特征图的维度和数量。
- 激活层 :激活层通常紧随卷积层之后,用于增加网络的非线性能力。常用的激活函数包括ReLU(Rectified Linear Unit)、Sigmoid和Tanh等。ReLU函数因其简单、有效而广受欢迎。
- 池化层 :池化层主要用于降低特征图的维度,减少计算量和参数数量。常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling)。池化层通过选取特征图每个小区域的最大值或平均值来降低特征图的分辨率。
- 全连接层 :全连接层位于CNN的末端,负责将学到的特征表示映射到样本的标记空间。全连接层的每个神经元都与前一层的所有神经元相连,用于计算最终分类结果。
四、卷积神经网络的训练过程
卷积神经网络的训练过程通常采用反向传播算法(Backpropagation)进行梯度下降优化。反向传播算法通过计算目标函数的梯度,将其反向传递回网络中的每个神经元,从而更新网络参数,使模型能够更好地拟合训练数据。
- 前向传播 :在前向传播过程中,输入数据通过卷积层、激活层、池化层等逐层传递,最终得到输出结果。
- 计算损失 :根据输出结果和真实标签计算损失函数值,评估模型的性能。
- 反向传播 :根据损失函数的梯度,利用链式法则逐层计算每个神经元的梯度,并使用梯度下降算法更新网络参数。
- 迭代优化 :重复前向传播、计算损失和反向传播的过程,直到满足停止条件(如达到最大迭代次数、损失函数值小于阈值等)。
五、卷积神经网络的应用领域
- 图像识别 :卷积神经网络最早应用于图像识别领域,通过多层滤波器提取图像特征,实现对图像的分类识别。在MNIST、CIFAR-10、ImageNet等图像数据集上取得了非常优秀的结果。
- 目标检测 :目标检测任务的目标是从图像中找到特定对象的位置,并将其框选出来。卷积神经网络已成为目标检测领域的主流方法,如R-CNN、Fast R-CNN、Faster R-CNN等算法均基于卷积神经网络。
- 图像分割 :图像分割是将图像分为若干个区域,每个区域内具有相似的特征。卷积神经网络通过训练学习一组卷积核,自动查找图像中的特征,并对每个像素进行分类,实现图像分割。
- 视频分析 :视频分析包括视频分类、动作识别、事件检测等多个方面。卷积神经网络因其对图像特征的有效提取能力,也被广泛应用于视频分析领域。以下是对视频分析应用的一些具体扩展:
视频分析中的卷积神经网络应用
- 视频分类 :
视频分类是指将视频按照其内容或主题进行分类的任务。卷积神经网络可以通过提取视频帧中的图像特征,并结合时间维度的信息(如光流法、时间金字塔等)来增强对视频内容的理解。一些模型如3D卷积神经网络(3D CNN)、C3D(Convolutional 3D)、I3D(Inflated 3D ConvNet)等,能够直接在时空维度上进行特征提取,有效提高了视频分类的准确率。 - 动作识别 :
动作识别是指从视频中识别出人类或物体的动作序列。卷积神经网络结合循环神经网络(RNN)或长短期记忆网络(LSTM)等时序模型,可以捕捉视频帧之间的时间依赖关系,从而识别出复杂的动作模式。此外,还有双流网络(Two-Stream Network)等架构,分别处理视频帧的光流信息和RGB信息,进一步提高动作识别的准确性。 - 事件检测 :
事件检测是指从视频流中自动检测并识别出特定事件的发生。这通常需要模型能够理解视频中的上下文信息、人物关系以及场景变化等。卷积神经网络结合注意力机制、图神经网络(GNN)等先进技术,可以在更复杂的视频分析任务中表现出色。例如,在交通监控系统中检测交通事故、在安防领域检测异常行为等。
卷积神经网络的优化与挑战
尽管卷积神经网络在多个领域取得了显著成果,但其在实际应用中仍面临一些挑战和优化问题:
- 计算复杂度 :随着网络层数的增加和参数量的增大,卷积神经网络的计算复杂度和内存消耗也随之增加。这限制了其在资源受限设备上的应用。因此,研究轻量级卷积神经网络、模型剪枝、量化等方法以降低计算复杂度和提高运行效率具有重要意义。
- 过拟合问题 :当训练数据有限时,卷积神经网络容易出现过拟合现象,即模型在训练集上表现良好,但在测试集上性能下降。解决过拟合问题的方法包括增加数据量、使用正则化技术(如L1/L2正则化、Dropout等)、早停法等。
- 可解释性 :卷积神经网络虽然性能强大,但其决策过程往往难以解释。这限制了其在一些需要高可解释性领域的应用(如医疗诊断、法律判决等)。因此,研究卷积神经网络的可解释性方法(如特征可视化、注意力机制等)对于提高其应用范围和可信度具有重要意义。
结论
卷积神经网络作为深度学习领域的重要算法之一,在图像识别、视频分析等多个领域展现了巨大的潜力和价值。通过不断优化网络结构和训练方法,卷积神经网络在处理复杂数据、提高模型性能等方面取得了显著进展。然而,随着应用场景的不断扩展和深化,卷积神经网络仍面临着计算复杂度、过拟合问题以及可解释性等挑战。未来研究将继续探索更加高效、鲁棒和可解释的卷积神经网络模型,以推动深度学习技术的进一步发展和应用。
-
深度学习
+关注
关注
73文章
5613浏览量
124728 -
cnn
+关注
关注
3文章
356浏览量
23581 -
卷积神经网络
+关注
关注
4文章
375浏览量
12962
发布评论请先 登录
卷积神经网络(CNN)的工作原理 神经网络的训练过程
在Ubuntu20.04系统中训练神经网络模型的一些经验
【PYNQ-Z2申请】基于PYNQ的卷积神经网络加速
卷积神经网络模型发展及应用
卷积神经网络简介:什么是机器学习?
卷积神经网络结构_卷积神经网络训练过程
卷积神经网络模型训练步骤
卷积神经网络如何识别图像
BP神经网络的基本结构和训练过程



评论