 如何提高BP神经网络算法的R2值
如何提高BP神经网络算法的R2值
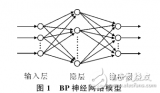
BP神经网络(Backpropagation Neural Network)是一种广泛应用于模式识别、分类、预测等领域的前馈神经网络。R2(R-squared)是衡量模型拟合优度的一个重要指标,其值越接近1,表示模型的预测效果越好。当BP神经网络算法的R2值较小时,说明模型的预测效果不理想,需要进行相应的优化和调整。
- 数据预处理
数据预处理是提高BP神经网络算法R2值的关键步骤之一。以下是一些常见的数据预处理方法:
1.1 数据清洗:去除数据集中的噪声、异常值和缺失值,以提高数据质量。
1.2 数据标准化:将数据缩放到相同的范围,如[0,1]或[-1,1],以消除不同特征之间的量纲差异。
1.3 特征选择:选择与目标变量相关性较高的特征,去除冗余特征,以提高模型的泛化能力。
1.4 数据增强:通过数据变换、插值等方法增加数据量,以提高模型的泛化能力。
- 网络结构设计
合理的网络结构设计对于提高BP神经网络算法的R2值至关重要。以下是一些建议:
2.1 隐藏层数量:根据问题的复杂程度选择合适的隐藏层数量。一般来说,问题越复杂,需要的隐藏层数量越多。
2.2 隐藏层神经元数量:根据问题的规模和复杂程度选择合适的神经元数量。过多的神经元可能导致过拟合,过少的神经元可能导致欠拟合。
2.3 激活函数:选择合适的激活函数,如Sigmoid、Tanh、ReLU等。不同的激活函数对模型的收敛速度和预测效果有不同的影响。
2.4 权重初始化:合适的权重初始化方法可以加速模型的收敛速度。常见的权重初始化方法有随机初始化、Xavier初始化和He初始化等。
- 学习率调整
学习率是BP神经网络算法中的一个重要参数,对模型的收敛速度和预测效果有显著影响。以下是一些建议:
3.1 选择合适的初始学习率:初始学习率过高可能导致模型无法收敛,过低则可能导致收敛速度过慢。
3.2 学习率衰减:随着训练的进行,逐渐减小学习率,以避免模型在训练后期出现震荡。
3.3 自适应学习率:使用自适应学习率算法,如Adam、RMSprop等,根据模型的损失情况自动调整学习率。
- 正则化方法
正则化是防止BP神经网络过拟合的一种有效方法。以下是一些常见的正则化方法:
4.1 L1正则化:通过在损失函数中添加权重的绝对值之和,使模型的权重稀疏,从而提高模型的泛化能力。
4.2 L2正则化:通过在损失函数中添加权重的平方和,使模型的权重较小,从而降低模型的复杂度。
4.3 Dropout:在训练过程中随机丢弃一部分神经元,以防止模型对训练数据过度拟合。
4.4 Early Stopping:在训练过程中,当验证集上的损失不再下降时停止训练,以防止模型过拟合。
- 超参数优化
超参数优化是提高BP神经网络算法R2值的重要手段。以下是一些建议:
5.1 网格搜索:通过遍历不同的超参数组合,找到最佳的超参数组合。
5.2 随机搜索:通过随机选择超参数组合,找到最佳的超参数组合。
5.3 贝叶斯优化:使用贝叶斯方法估计超参数的最优分布,从而找到最佳的超参数组合。
5.4 遗传算法:使用遗传算法对超参数进行优化,通过迭代搜索找到最佳的超参数组合。
- 模型融合
模型融合是提高BP神经网络算法R2值的有效方法。以下是一些常见的模型融合方法:
6.1 Bagging:通过训练多个独立的BP神经网络模型,然后对它们的预测结果进行平均或投票,以提高模型的稳定性和泛化能力。
6.2 Boosting:通过逐步训练多个BP神经网络模型,每个模型都关注前一个模型的预测误差,以提高模型的预测精度。
6.3 Stacking:通过训练多个BP神经网络模型,然后将它们的预测结果作为输入,训练一个新的BP神经网络模型,以提高模型的预测效果。
- 模型评估与诊断
模型评估与诊断是提高BP神经网络算法R2值的重要环节。以下是一些建议:
7.1 交叉验证:使用交叉验证方法评估模型的泛化能力,避免过拟合。
7.2 误差分析:分析模型预测误差的原因,找出模型的不足之处,并进行相应的优化。
-
参数
+关注
关注
11文章
1854浏览量
32354 -
BP神经网络
+关注
关注
2文章
115浏览量
30581 -
神经元
+关注
关注
1文章
363浏览量
18486 -
网络算法
+关注
关注
0文章
2浏览量
5858
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论