 神经网络反向传播算法的原理、数学推导及实现步骤
神经网络反向传播算法的原理、数学推导及实现步骤
神经网络反向传播算法(Backpropagation Algorithm)是一种用于训练多层神经网络的算法,其基本原理是通过梯度下降法来最小化损失函数,从而找到网络的最优权重和偏置。本文将介绍反向传播算法的原理、数学推导、实现步骤以及在深度学习中的应用。
- 神经网络概述
神经网络是一种受人脑启发的计算模型,由大量的神经元(或称为节点)组成,每个神经元与其他神经元通过权重连接。神经网络可以分为输入层、隐藏层和输出层。输入层接收外部输入数据,隐藏层对输入数据进行非线性变换,输出层生成最终的预测结果。
- 损失函数
损失函数(Loss Function)是衡量神经网络预测结果与真实值之间差异的函数,常见的损失函数有均方误差(Mean Squared Error, MSE)、交叉熵(Cross-Entropy)等。损失函数的选择取决于具体问题的性质和需求。
- 梯度下降法
梯度下降法是一种优化算法,用于最小化损失函数。其基本思想是沿着损失函数梯度的方向更新网络参数(权重和偏置),使得损失函数的值逐渐减小,直至达到最小值。
- 反向传播算法原理
反向传播算法是一种利用梯度下降法训练多层神经网络的算法。其核心思想是将损失函数关于网络参数的梯度从输出层反向传播到输入层,从而计算出每个参数的梯度值。具体步骤如下:
4.1 前向传播
首先,将输入数据通过网络的前向传播,计算出每个神经元的激活值。激活值的计算公式为:
a = f(z)
z = w * x + b
其中,a 表示激活值,f 表示激活函数(如 Sigmoid、ReLU 等),z 表示输入加权和,w 表示权重,x 表示输入值,b 表示偏置。
4.2 计算损失函数
根据网络的输出值和真实值,计算损失函数的值。损失函数的选择取决于具体问题的性质和需求。
4.3 反向传播
从输出层开始,沿着网络的连接反向传播,计算每个参数的梯度值。具体步骤如下:
4.3.1 计算输出层的梯度
对于输出层的每个神经元,计算损失函数关于该神经元激活值的梯度。以均方误差损失函数为例,梯度的计算公式为:
dL/da = (a - y) * f'(z)
其中,dL/da 表示损失函数关于激活值的梯度,a 表示激活值,y 表示真实值,f'(z) 表示激活函数的导数。
4.3.2 计算隐藏层的梯度
对于隐藏层的每个神经元,计算损失函数关于该神经元激活值的梯度。梯度的计算公式为:
dL/da = (w^T * dL/dz) * f'(z)
其中,dL/dz 表示损失函数关于输入加权和的梯度,w^T 表示权重矩阵的转置。
4.3.3 更新网络参数
根据计算出的梯度值,使用梯度下降法更新网络的权重和偏置。更新公式为:
w_new = w_old - learning_rate * dL/dw
b_new = b_old - learning_rate * dL/db
其中,w_new 和 b_new 分别表示更新后的权重和偏置,w_old 和 b_old 分别表示更新前的权重和偏置,learning_rate 表示学习率,dL/dw 和 dL/db 分别表示损失函数关于权重和偏置的梯度。
- 反向传播算法的数学推导
5.1 链式法则
反向传播算法的数学基础是链式法则(Chain Rule),它允许我们计算复合函数的导数。对于一个复合函数 L = L(a, z),其关于权重 w 的导数可以表示为:
dL/dw = (dL/da) * (da/dz) * (dz/dw)
5.2 激活函数的导数
常见的激活函数及其导数如下:
- Sigmoid 函数:
f(z) = 1 / (1 + exp(-z)),导数为f'(z) = f(z) * (1 - f(z))。 - ReLU 函数:`f(z) = max(0, z)
-
神经网络
+关注
关注
42文章
4772浏览量
100793 -
神经元
+关注
关注
1文章
363浏览量
18454 -
计算模型
+关注
关注
0文章
29浏览量
9850 -
数学推导
+关注
关注
0文章
2浏览量
5669
发布评论请先 登录
相关推荐
浅析深度神经网络(DNN)反向传播算法(BP)
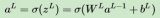
BP(BackPropagation)反向传播神经网络介绍及公式推导






 工商网监
工商网监
评论