 迁移学习的基本概念和实现方法
迁移学习的基本概念和实现方法
迁移学习(Transfer Learning)是机器学习领域中的一个重要概念,其核心思想是利用在一个任务或领域中学到的知识来加速或改进另一个相关任务或领域的学习过程。这种方法在数据稀缺或领域迁移的情况下尤为有效,因为它能够显著减少对大量标记数据的需求,提高模型的学习效率和泛化能力。
迁移学习的基本概念
迁移学习允许我们将源任务(Source Task)上训练得到的模型或知识迁移到目标任务(Target Task)上。这里的“知识”可以是模型的参数、特征表示或数据间的关系等。迁移学习旨在通过复用已有的学习成果,来加速对新任务的学习过程,同时提高新任务的性能。
迁移学习的实现方法
迁移学习有多种实现方法,主要包括以下几种:
- 样本迁移(Instance-based Transfer Learning)
样本迁移主要关注如何在源领域和目标领域之间有效地选择和加权样本。它通常涉及在源领域中找到与目标领域相似的数据,并给这些相似数据较高的权重,以便在训练过程中更多地利用这些数据。然而,由于实际操作中很难准确衡量样本间的相似性,这种方法的应用相对有限。 - 特征迁移(Feature-based Transfer Learning)
特征迁移是最常用的迁移学习方法之一。它通过观察和利用源领域和目标领域数据之间的共同特征,将源领域中的特征表示迁移到目标领域中。这通常需要将两个领域的特征投影到同一个特征空间,然后在该空间中进行特征迁移。特征迁移的一个典型应用是在深度学习中,通过迁移预训练模型的卷积层或全连接层权重来加速新任务的训练。 - 模型迁移(Model-based Transfer Learning)
模型迁移是将整个预训练模型(或模型的一部分)直接应用于目标任务。这通常涉及到对预训练模型的微调(Fine-tuning),即保持大部分模型参数不变,只调整与目标任务相关的部分参数。模型迁移的好处是可以直接利用预训练模型强大的特征提取能力,同时快速适应新任务的需求。 - 关系迁移(Relational Transfer Learning)
关系迁移主要关注源领域和目标领域之间数据关系的迁移。它试图在源领域中学习到的数据关系(如社会网络中的关系、图像中的空间关系等)应用到目标领域中。关系迁移在处理具有复杂关系结构的数据时非常有用,但目前这种方法的研究和应用相对较少。
迁移学习的代码示例
这里仅提供一个基于Keras的模型迁移的简单代码示例,用于说明如何在图像分类任务中应用迁移学习。
import tensorflow as tf
from tensorflow.keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 加载预训练的VGG16模型
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# 冻结预训练模型的权重
base_model.trainable = False
# 在预训练模型的基础上添加自定义层
x = Flatten()(base_model.output)
x = Dense(256, activation='relu')(x)
predictions = Dense(10, activation='softmax')(x) # 假设有10个类别
# 创建新模型
model = Model(inputs=base_model.input, outputs=predictions)
# 编译模型
model.compile(optimizer=Adam(lr=0.0001), loss='categorical_crossentropy', metrics=['accuracy'])
# 数据增强
train_datagen = ImageDataGenerator(preprocessing_function=preprocess_input,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# 假设已有训练集和验证集的路径
train_generator = train_datagen.flow_from_directory(
'path_to_train',
target_size=(224, 224),
batch_size=32,
class_mode='categorical')
validation_generator = train_datagen.flow_from_directory(
'path_to_validation',
target_size=(224, 224),
batch_size=32,
class_
mode='categorical')
# 训练模型
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // train_generator.batch_size,
epochs=10, # 根据实际情况调整epoch数
validation_data=validation_generator,
validation_steps=validation_generator.samples // validation_generator.batch_size
)
# 评估模型
# 注意:这里假设你有一个测试集,并且你希望用整个测试集来评估模型
test_datagen = ImageDataGenerator(preprocessing_function=preprocess_input)
test_generator = test_datagen.flow_from_directory(
'path_to_test',
target_size=(224, 224),
batch_size=32,
class_mode='categorical',
shuffle=False) # 测试时不需要打乱数据
test_loss, test_acc = model.evaluate(test_generator, steps=test_generator.samples // test_generator.batch_size)
print(f'Test accuracy: {test_acc:.4f}')
迁移学习的深入讨论
1. 迁移学习的优势
- 数据效率 :迁移学习可以显著减少对目标领域标记数据的需求,尤其是在数据稀缺的情况下。
- 学习速度 :通过复用预训练模型的知识,迁移学习可以加速新任务的训练过程。
- 性能提升 :由于预训练模型通常具有较高的特征提取能力,迁移学习往往能够提升目标任务的性能。
2. 迁移学习的挑战
- 负迁移 :如果源领域和目标领域之间的差异过大,迁移学习可能会导致性能下降,即负迁移现象。
- 领域适应性 :如何有效地将源领域的知识迁移到目标领域,同时保持模型的泛化能力,是一个具有挑战性的问题。
- 计算资源 :预训练模型通常规模较大,需要较高的计算资源来训练和部署。
3. 迁移学习的应用场景
- 图像识别 :在医学影像分析、卫星图像解析等领域,迁移学习可以显著提高识别精度和效率。
- 自然语言处理 :在情感分析、文本分类等任务中,迁移学习可以利用大规模语料库预训练的模型来提升性能。
- 推荐系统 :在冷启动问题中,迁移学习可以利用用户在其他领域的行为数据来推荐新的内容。
4. 迁移学习的未来展望
随着深度学习技术的不断发展,迁移学习将在更多领域发挥重要作用。未来,我们可以期待以下几个方面的发展:
- 更高效的迁移策略 :研究如何更准确地评估源领域和目标领域之间的相似性,从而制定更有效的迁移策略。
- 无监督迁移学习 :探索如何在没有标签数据的情况下进行迁移学习,以进一步提高数据利用效率。
- 终身学习 :将迁移学习与终身学习相结合,使模型能够持续从多个任务中学习和积累知识。
总之,迁移学习作为一种强大的机器学习技术,已经在多个领域取得了显著成果。随着研究的深入和技术的进步,我们有理由相信迁移学习将在未来发挥更加重要的作用。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
代码
+关注
关注
30文章
4779浏览量
68521 -
机器学习
+关注
关注
66文章
8406浏览量
132562 -
迁移学习
+关注
关注
0文章
74浏览量
5559
发布评论请先 登录
相关推荐
关于数字电路的基本概念和学习内容
,以便使用最少集成电路实现功能。以上是关于硬件电子电路设计技术数字电路部分的基本概念和学习内容,如果想从事电子行业的朋友们,建议深入学习,不仅会电子电路设计,建议还需要懂PCB画板和单
发表于 07-22 16:46
智能天线的基本概念
1智能天线的基本概念 智能天线综合了自适应天线和阵列天线的优点,以自适应信号处理算法为基础,并引入了人工智能的处理方法。智能天线不再是一个简单的单元,它已成为一个具有智能的系统。其具体定义为:智能
发表于 08-05 08:30
人工智能基本概念机器学习算法
目录人工智能基本概念机器学习算法1. 决策树2. KNN3. KMEANS4. SVM5. 线性回归深度学习算法1. BP2. GANs3. CNN4. LSTM应用人工智能基本概念数
发表于 09-06 08:21
USB基本概念及从机编程方法介绍
慕课苏州大学.嵌入式开发及应用.第四章.较复杂通信模块.USB基本概念及从机编程方法0 目录4 较复杂通信模块4.4 USB基本概念及从机编程方法4.4.1 课堂重点4.4.2 测试与
发表于 11-08 09:14

电路的基本概念定律和分析方法的学习课件免费下载
本文档的主要内容详细介绍的是电路的基本概念定律和分析方法的学习课件免费下载包括了:1 支路电流法,2 节点电位法,3 电源模型的等效互换,4 迭加定理,5 等效电源定理(1)戴维南定理(2)诺顿定理
发表于 12-22 08:00
•3次下载
FPGA学习教程之硬件设计基本概念
关于FPGA架构和基本组成《FPGA学习–架构和基本组成单元(一)》 ,下面参考Xilinx Vivado官方文档学习硬件设计的基本概念。
发表于 12-25 17:34
•22次下载
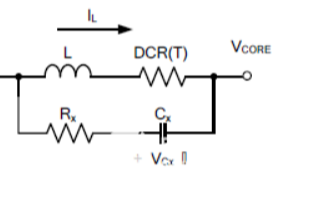
DCR温度补偿的基本概念和实现方法
的电流信号。为了消除温度效应,通常在电流检测环路中添加一个 DCR 温度网络。本应用笔记将介绍 DCR 温度补偿的基本概念和实现方法。
Linux内核实现内存管理的基本概念
本文概述Linux内核实现内存管理的基本概念,在了解基本概念后,逐步展开介绍实现内存管理的相关技术,后面会分多篇进行介绍。
发表于 06-23 11:56
•831次阅读
深度学习基本概念
深度学习基本概念 深度学习是人工智能(AI)领域的一个重要分支,它模仿人类神经系统的工作方式,使用大量数据训练神经网络,从而实现自动化的模式识别和决策。在科技发展的今天,深度
组合逻辑控制器的基本概念、实现原理及设计方法
广泛应用于计算机、通信、控制等领域。 本文将详细介绍组合逻辑控制器的基本概念、实现原理、设计方法、应用场景等方面的内容,以帮助读者全面了解组合逻辑控制器。 基本概念 1.1 组合逻辑





 工商网监
工商网监
评论