 神经网络预测模型的构建方法
神经网络预测模型的构建方法
神经网络模型作为一种强大的预测工具,广泛应用于各种领域,如金融、医疗、交通等。本文将详细介绍神经网络预测模型的构建方法,包括模型设计、数据集准备、模型训练、验证与评估等步骤,并附以代码示例。
一、引言
神经网络模型通过模拟人脑神经元之间的连接方式,实现对输入数据的处理、分类、预测等功能。在构建神经网络预测模型时,我们首先需要明确预测目标、选择适当的网络结构、准备数据集,并通过训练与验证不断优化模型性能。
二、模型设计
1. 确定模型结构
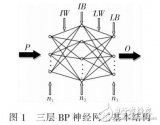
神经网络模型的结构设计是构建过程中的首要任务。一个典型的神经网络模型包括输入层、若干隐藏层和输出层。在设计模型时,需要确定以下几个关键参数:
- 层数 :决定模型的深度,过浅的模型可能无法捕捉到数据的复杂特征,而过深的模型则可能导致过拟合。
- 神经元数量 :每层神经元的数量会影响模型的复杂度和学习能力。
- 激活函数 :用于引入非线性因素,常见的激活函数包括Sigmoid、ReLU、Tanh等。
- 优化算法 :用于在训练过程中更新网络权重,常见的优化算法有梯度下降(GD)、动量(Momentum)、Adam等。
2. 选择合适的网络类型
根据预测任务的特点,选择合适的网络类型也至关重要。常见的网络类型包括:
- 多层感知机(MLP) :适用于分类、回归等任务。
- 卷积神经网络(CNN) :专门用于处理图像和视频数据。
- 递归神经网络(RNN) :适用于处理序列数据,如时间序列分析、自然语言处理等。
- 长短期记忆网络(LSTM) :RNN的变种,能够处理长期依赖关系。
三、数据集准备
1. 数据收集
根据预测目标,收集相关的数据集。数据集应包含足够的样本以支持模型的训练与验证。
2. 数据预处理
数据预处理是构建预测模型的重要步骤,包括数据清洗、特征选择、特征缩放等。
- 数据清洗 :去除重复数据、处理缺失值、异常值等。
- 特征选择 :选择与预测目标相关的特征,去除不相关或冗余的特征。
- 特征缩放 :将数据特征缩放到同一尺度,常用的方法包括归一化和标准化。
3. 数据划分
将数据集划分为训练集、验证集和测试集。训练集用于模型训练,验证集用于调整模型参数,测试集用于评估模型性能。
四、模型训练
1. 初始化参数
在训练之前,需要初始化网络的权重和偏置。初始化的方法会影响模型的训练效率和最终性能。
2. 前向传播
将输入数据通过神经网络进行前向传播,计算每一层的输出值,直到得到最终的预测结果。
3. 损失计算
根据预测结果与实际结果之间的差异,计算损失值。常用的损失函数包括均方误差(MSE)、交叉熵损失等。
4. 反向传播
根据损失值,通过反向传播算法更新网络权重和偏置。反向传播算法通过计算损失函数关于网络参数的梯度,并沿梯度方向更新参数。
5. 迭代训练
重复进行前向传播、损失计算和反向传播,直到达到预设的训练次数或损失值满足要求。
五、模型验证与评估
1. 验证模型
使用验证集对模型进行验证,调整模型参数和结构,以获得更好的性能。
2. 评估模型
使用测试集对模型进行评估,计算模型的准确率、召回率、精确率、F1分数等指标,以全面评估模型的性能。
六、代码示例
以下是一个使用MATLAB进行BP神经网络预测模型构建的简单示例:
% 假设inputn为输入数据,outputn为输出数据
% 确定网络结构,例如输入层10个神经元,隐藏层20个神经元,输出层1个神经元
net = newff(inputn, outputn, [20 1], {'tansig', 'purelin'}, 'trainlm');
% 设置训练参数
net.trainParam.epochs = 1000; % 训练次数
net.trainParam.lr = 0.01; % 学习率
net.trainParam.goal = 0.00001; % 训练目标最小误差
% 训练模型
net = train(net, inputn, outputn);
% 预测
inputn_test = [测试数据]; % 测试数据需要预处理
an = sim(net,inputn_test); % 使用训练好的网络进行预测
% 评估模型
% 假设outputn_test是测试集的真实输出
performance = perform(net, outputn_test, an); % 计算性能指标,如MSE
fprintf('模型的均方误差(MSE)为: %.4fn', performance);
% 可视化预测结果(可选)
figure;
plot(outputn_test, 'b-o', 'DisplayName', '真实值');
hold on;
plot(an, 'r-*', 'DisplayName', '预测值');
legend show;
xlabel('样本');
ylabel('输出值');
title('真实值与预测值对比');
grid on;
% 注意:上述代码仅为示例,实际应用中需要根据具体数据和任务需求进行调整。
七、优化与调参
在模型构建和训练过程中,经常需要对模型进行优化和调参以获得更好的性能。以下是一些常用的优化和调参策略:
1. 批量大小(Batch Size)
选择合适的批量大小可以影响模型的训练速度和泛化能力。较小的批量大小可能导致训练过程更加稳定,但训练时间更长;较大的批量大小则可能加速训练,但可能增加过拟合的风险。
2. 学习率(Learning Rate)
学习率决定了参数更新的步长。过大的学习率可能导致训练过程不稳定,甚至无法收敛;而过小的学习率则可能导致训练过程过于缓慢。
3. 正则化(Regularization)
正则化是一种减少过拟合的技术,通过在损失函数中添加正则化项来约束模型的复杂度。常见的正则化方法包括L1正则化、L2正则化(也称为权重衰减)和Dropout。
4. 提前停止(Early Stopping)
提前停止是一种在验证集性能开始下降时停止训练的策略,以防止过拟合。通过监控验证集上的损失或性能指标,可以在达到最佳性能时停止训练。
5. 模型集成(Model Ensemble)
模型集成通过结合多个模型的预测结果来提高整体性能。常见的集成方法包括Bagging、Boosting和Stacking。
八、结论
神经网络预测模型的构建是一个复杂而系统的过程,涉及模型设计、数据集准备、模型训练、验证与评估等多个环节。通过合理选择网络结构、优化训练参数、采用有效的优化和调参策略,可以构建出性能优异的预测模型。然而,需要注意的是,模型构建过程中应充分考虑数据的特性和预测任务的需求,避免盲目追求复杂的模型和过高的性能指标。
最后,随着深度学习技术的不断发展,新的网络结构和优化算法不断涌现,为神经网络预测模型的构建提供了更多的选择和可能性。因此,持续关注和学习最新的研究成果和技术进展,对于提高模型构建和应用的水平具有重要意义。
-
神经网络
+关注
关注
42文章
4772浏览量
100852 -
模型
+关注
关注
1文章
3254浏览量
48893 -
预测模型
+关注
关注
0文章
26浏览量
8701
发布评论请先 登录
相关推荐
用matlab编程进行BP神经网络预测时如何确定最合适的,BP模型
Keras之ML~P:基于Keras中建立的回归预测的神经网络模型
卷积神经网络模型发展及应用
BP神经网络风速预测方法
基于RBF神经网络的通信用户规模预测模型
气象因素的神经网络预测方法






 工商网监
工商网监
评论