 芯片、模型生态分散,无问芯穹、沐曦、壁仞谈国产算力瓶颈破局之道
芯片、模型生态分散,无问芯穹、沐曦、壁仞谈国产算力瓶颈破局之道
电子发烧友网报道(文/李弯弯)近日,2024世界人工智能大会正在举行,无问芯穹联合创始人兼CEO夏立雪在大会论坛上谈到一个现象,从GPT-3到GPT-4,无论是算力还是大模型能力都遵循指数级增长,而GPT-4之后的一段时间里,无论是OpenAI发布的新模型,还是其他大模型,整体算法能力进入了放缓甚至是停滞的阶段。
夏立雪认为,这其中,表面上看是大模型的发展放缓或者停止了,其实背后的逻辑却是支撑算法的算力遇到了瓶颈。在他看来,算力是AI发展的前哨和基石,支撑模型能力迈向下一代的算力系统,还需要去研发和构建。
国内模型层和芯片层生态相对分散
为了应对大模型对算力的需求,国内外巨头都在加大对算力资源的投入,如国外的微软、谷歌、Meta、OpenAI,以及国内的大厂百度,移动、联通、电信三大运营商等都在构建万卡集群,万卡集群俨然成为了大模型性能提升的兵家必争之地。
然而相比之下,国外模型层与芯片层生态相对集中,算法厂商不超过10家,芯片厂商差不多是两家,英伟达和AMD。国内生态则是一个非常分散的状态,大家都知道,中国百模大战,包括非常多通用的基座大模型,还有很多行业大模型。芯片层面,除了英伟达和AMD之外,国内还有非常多算力芯片厂商去争相扩展市场。
这些分散的生态,就会面临很多生态打通的关键问题。因此,在国内,虽然大家知道构建万卡集群非常重要。而且据统计,现在国内已经有一百多个建设方宣布正在建设或者已经建设了千卡集群,这里面大部分采用的是异构算力,原因之一是国内的生态非常分散,另外是在供应方面,需要非常多不同的卡来满足集群性能需求。
夏立雪谈到,这些异构的芯片之间,存在一种“生态竖井”,即硬件生态系统封闭且互不兼容。用了A卡的开发者,无法轻易迁移至B卡上展开工作,也难以同时使用A卡和B卡完成大模型训练或推理。
这导致,如果一个算力集群中存在两种或以上的芯片,算力使用方会面临一系列技术挑战,比如不同硬件平台适配不同的软件栈和工具链,而某些任务更容易在特定类型的芯片上运行,开发者若要在异构芯片上从事生产,就需要为每种芯片定制和优化代码,这大大增加了开发和维护的复杂性。这也使得多种算力芯片被投入各地集群从事AI生产,而“生态竖井”的存在,让“多芯片”并不等于“大算力”。
无问芯穹提出了异构千卡混训解决方案。异构芯片间的混训主要面临两大挑战,一是异构卡通信库差异,导致异构卡之间通信难;二是异构卡之间性能差异,导致模型分布式训练低效。
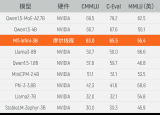
为此,无问芯穹建立了一个通用集合通信库,实现不同芯片的高效通信;然后提出了一种基于流水线并行的非均匀拆分方案,以解决不同种芯片负载均衡的问题;最后提出了一个自研的混训性能预测工具,用于判断最优的非均匀拆分策略,指导千卡异构集群训练。从实际千卡混合训练效果可见,无问芯穹千卡异构混合训练集群算力利用率最高达到了97.6%。
沐曦、壁仞谈“算力瓶颈破局之术”
在某个论坛“算力瓶颈破局之术”的圆桌讨论环节,沐曦联合创始人兼软件CTO杨建分别从算法层面和芯片层面谈到解决之道。首先是算法层面,硅基的算力三年只能提升三倍,而大模型对算力的需求则要求吞吐量三年提升750倍。在杨建看来,这用硬件的方法无论如何也达不到,单从芯片层面无法解决这个问题。
他认为,今天大家追捧的Transfomer算法可能是错的,即使大家也在Transfomer软件上进行一些创新,其实作用并不大。我们还是需要从基本的算法层面出发,思考怎么从算法上进行改变,才能让算法在三年内推理效率提高750倍。大模型已经进入一个新的时代,Transfomer的时代已经结束了,大家需要思考的是怎么突破Transfomer的限制。
接着看从芯片层面的破局,杨建认为,这很难。他认为,我们与美国算力差距会在2029年达到最大。首先,我们与英伟达存在工艺上的差距。其次,我们无法进口最先进的芯片,在2029年的时候,中国芯片仍然还是会落后英伟达。据他推算,到2029年,中国的算力综合,可能不到美国的四分之一。
其实,在2022年之前,我们与美国的算力基本上是一比一,2023年开始急剧下降,可以看到,美国很多企业部署集群都是一万张卡以上,国内到五千张卡已经非常了不起了。因此,我们与美国算力的差距,从2023年开始逐步扩大,到2029年会到达一个高峰值,原因是,美国对算力需求的总量到那时候再往上添加意义不大了。
但国内单芯片的算力到那时候还是没有办法去赶上美国,因此在杨建看来,当没有办法从这个层面去破局的时候,我们需要跳出原来的圈子。
怎么做呢?他谈到,英伟达B200其实给出了一个很好的例子,一直以来AMD在chiplet上都非常领先,它无论是CPU还是GPU都要做chiplet。然而英伟达在B200上又做了一个新的chiplet,它把中间的传输性一下子提升到了10TB per second,这是一个全新的架构,AMD完全没有往这个方向走。
中国在chiplet方向其实已经走得很远,不仅有chiplet封装,还有Die to Die封装,还有wafer to wafer的封装,中国的芯片公司如果想要在硬件上提升,其实可以利用先进封装这个优势,去思考如何提高提高单芯片的性能。
此外,除了提升单芯片性能之外,还可以去思考怎么从系统级做优化,以前基本上是一个CPU带8张卡,现在可以思考是不是能够一个CPU带16张卡、32张卡。单芯片算力不够,是不是能通过系统级互联结构,在互联上进行一些加速,从而达到更好的性能。数据传输在算力上是一个非常重要的方面,可以探索好的压缩算法技术,通过压缩数据本身,而不改变推理和训练的精度,来提升效率。
壁仞科技副总裁兼AI软件首席架构师丁云帆从三个维度谈到算力瓶颈的破局之法。大模型的训练是一个系统工程,它需要软件和硬件结合起来,同时也需要算法和工程协同,在这样一个复杂的系统里,它面临非常多的挑战。
丁云帆提到三个点,一是硬件算力,二是软硬结合之后的有效算力,三是异构混训的聚合算力。硬件算力,即单卡的算力乘以卡的个数,单卡的算力可能因为制程等原因,它能做到的上限有限,不过单卡本身微架构层面仍谈有创新的空间。比如,壁仞在第一代产品里用了chiplet架构,这就是用chiplet的当时提升从单卡层面提升算力。
单卡之外,还有单机,传统基本上是单机8卡,现在可以通过一些方式做到单机16卡,把单机性能提升上去。单机之外,现在还可以看到有很多千卡集群、万卡集群,通过更大规模的集群去提升算力,这个时候网络对基础设施的要求会非常高。
有了超大集群之后,最终软件是不是能够把集群的算力发挥出来,这就谈到了软硬件结合的有效算力,丁云帆将这个效率总结了三个点:首先是,集群的调度效率怎么样,比如说,有一万张卡,调度效率不好,相当于可能在用的只有九千张;其次是能不能够用好它,也就能不能够通过算法功能的协同,训练把算法的性能优化上去,尤其是大规模参数的大模型,在超大集群里,如何去做模型拆分、做各种并行策略,真正把集群的算力发挥出来;
其三大规模集群还有一个稳定问题,无论是采用英伟达还是国产的算力芯片,都会存在这个问题,大规模集群的故障率非常高,可能分配有10个小时,却只能用到8个小时。这需要对故障的检测能够自动定位出来,出了故障之后,能够更快速的恢复它。
聚合算力,现在可以看到建了很多千卡集群、万卡集群,可能有些集群用的同一种英伟达的卡,它也可能是很多小的池子,现在随着更多国产GPU的落地,这又会出现新的池子。对于用户来说,这么多小池子,是不是能够聚合起来去训一个大的模型。那么这个在互联互通层面,首先要通,其次通行的效率怎么样,肯定会有通行快慢的问题,这种异构的并行的拆分策略就非常关键。
总结来说,就是硬件算力、软硬件结合的有效算力、聚合算力,我们从这三个维度都把相关的工作做好,即使是国产单个芯片看上去不够强,我们通过这样的方式也能够把国产算力提升到满足大模型训练的需求。
写在最后
随着大模型的发展,其性能提升放缓甚至停滞,而这背后则是支撑算法的算力遇到瓶颈。国内外都在加大千卡、万卡集群的建设来提升算力,然而这其中仍然存在问题,在国内芯片生态分散,集群使用多种芯片,异构芯片之间的混训存在挑战。同时相对于国外,国产单芯片存在落差,如何通过本身优势,如chiplet,来提升单机、集群的算力,如何通过软硬件结合提升算法训练效率等,都是可以思考突破算力瓶颈的方向。
-
AI
+关注
关注
87文章
30072浏览量
268331 -
算力芯片
+关注
关注
0文章
44浏览量
4502 -
AI算力
+关注
关注
0文章
72浏览量
8551 -
壁仞科技
+关注
关注
1文章
53浏览量
2704 -
沐曦
+关注
关注
0文章
26浏览量
1141
发布评论请先 登录
相关推荐
性能提升近一倍!壁仞科技携手无问芯穹,在千卡训练集群等领域取得技术新突破

无问芯穹获完成5亿元A轮融资
上海无问芯穹获多家投资方投资
壁仞科技参与中国移动呼和浩特智算中心,共筑AI算力新基石
无问芯穹发布千卡规模异构芯片混训平台
壁仞科技为中国移动呼和浩特智算中心提供强大算力
壁仞科技亮相数字中国建设峰会

摩尔线程与无问芯穹宣布完成基于GPU千卡集群的3B规模大模型实训
壁仞科技加入中国移动“融创未来”算力网络创新联合体







 工商网监
工商网监
评论