 基于AI深度学习的缺陷检测系统
基于AI深度学习的缺陷检测系统
在工业生产中,缺陷检测是确保产品质量的关键环节。传统的人工检测方法不仅效率低下,且易受人为因素影响,导致误检和漏检问题频发。随着人工智能技术的飞速发展,特别是深度学习技术的崛起,基于AI深度学习的缺陷检测系统逐渐成为工业界关注的焦点。本文将深入探讨这一系统的构建、应用及优势,并附上相关代码示例。
一、基于AI深度学习的缺陷检测系统概述
1. 系统背景与需求
在工业生产中,由于生产和运输环境的复杂性,产品表面往往会出现划痕、压伤、擦挂等微小缺陷。这些缺陷不仅影响产品的美观度,还可能对产品的性能和使用寿命造成严重影响。因此,开发一种高效、准确的缺陷检测系统对于提高产品质量、降低不良品率具有重要意义。
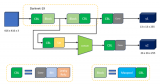
2. 系统架构
基于AI深度学习的缺陷检测系统通常由数据采集、图像预处理、模型训练、缺陷检测与结果输出等模块组成。其中,数据采集模块负责通过相机或传感器等设备获取待检测产品的图像信息;图像预处理模块对原始图像进行去噪、增强对比度等操作,以提高后续检测的准确性;模型训练模块利用深度学习算法对标注好的缺陷样本进行训练,构建出能够识别缺陷的模型;缺陷检测模块则利用训练好的模型对新的图像进行缺陷检测,并输出检测结果。
二、深度学习在缺陷检测中的应用
1. 数据准备
数据是深度学习模型训练的基础。在缺陷检测系统中,需要收集大量的正常样本和缺陷样本,并进行标注。标注工作通常由专业人员完成,他们需要根据产品的特性和缺陷类型,对图像中的缺陷进行精确的定位和分类。数据准备过程包括数据的读取、预处理和划分训练集与测试集等步骤。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
# 读取数据
data = pd.read_csv('data.csv')
# 预处理数据(示例,具体步骤根据实际需求调整)
def preprocess(data):
# 假设data中包含'image_path'和'label'两列
# 这里只是示例,实际中需要加载图像并进行处理
# ...
# 返回预处理后的数据
return data
preprocessed_data = preprocess(data)
# 划分训练集和测试集
train_data, test_data = train_test_split(preprocessed_data, test_size=0.2)
2. 模型构建
模型构建是深度学习缺陷检测的核心步骤。常用的模型包括卷积神经网络(CNN)和循环神经网络(RNN)等。在构建模型时,需要定义网络结构、选择合适的激活函数和损失函数,并进行参数初始化。
import tensorflow as tf
from tensorflow.keras import layers
# 定义模型结构
model = tf.keras.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid')) # 假设是二分类问题
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
3. 模型训练
在模型构建完成后,需要使用训练数据对模型进行训练。训练过程中,需要定义训练的批次大小、迭代次数等超参数,并监控模型的性能。
# 假设train_data和train_labels分别是训练数据和标签
# 设置训练参数
batch_size = 32
epochs = 10
# 训练模型
model.fit(train_data, train_labels, batch_size=batch_size, epochs=epochs, validation_data=(test_data, test_labels))
4. 模型评估与测试
模型训练完成后,需要对模型进行评估和测试。评估过程中,可以计算模型在测试集上的准确率、精确率、召回率等指标,并绘制混淆矩阵来分析模型的性能。
# 评估模型
test_loss, test_acc = model.evaluate(test_data, test_labels, verbose=2)
print('Test accuracy:', test_acc)
5. 缺陷检测
使用训练好的模型对新的图像进行缺陷检测是系统的最终目的。在实际应用中,可以将待检测的图像输入到模型中,模型会输出该图像是否存在缺陷的预测结果,并可能给出缺陷的具体位置和类型。
缺陷检测模块是系统的核心功能之一。它利用训练好的深度学习模型对输入图像进行快速、准确的缺陷识别。为了提高检测效率,可以采用批处理或流式处理的方式对图像进行处理。
# 假设有一个新的待检测图像
from PIL import Image
import numpy as np
# 加载图像
image_path = 'new_image.jpg'
img = Image.open(image_path)
img = img.resize((64, 64)) # 调整为模型输入所需的尺寸
img_array = np.array(img) / 255.0 # 归一化处理
img_array = np.expand_dims(img_array, axis=0) # 增加批次维度
# 使用模型进行预测
prediction = model.predict(img_array)
# 预测结果处理
# 假设prediction是一个概率值,可以通过阈值判断是否存在缺陷
defect_threshold = 0.5
if prediction[0] > defect_threshold:
print("检测到缺陷!")
else:
print("未检测到缺陷。")
# 如果需要更详细的缺陷信息(如位置、类型),则模型可能需要设计为多输出或多任务学习
# 这通常涉及更复杂的网络结构和后处理步骤
6. 结果输出与反馈
检测结果通常以可视化的形式(如标记缺陷位置的图像)或数值报告的形式输出给用户。同时,系统还可以根据检测结果生成反馈信号,如触发警报、停止生产线等,以便及时采取措施处理缺陷产品。
7. 系统优化与迭代
在实际应用中,基于AI深度学习的缺陷检测系统需要不断优化和迭代。这包括收集更多的训练数据以提高模型的泛化能力、调整模型结构和参数以优化性能、引入新的算法和技术以应对更复杂的缺陷类型等。此外,系统的稳定性和实时性也是优化过程中需要考虑的重要因素。
三、系统优势与挑战
优势 :
- 高效性 :深度学习模型能够快速处理大量图像数据,显著提高缺陷检测的效率。
- 准确性 :通过训练大量标注数据,深度学习模型能够学习到复杂的特征表示,从而提高检测的准确性。
- 灵活性 :深度学习模型具有较强的泛化能力,能够适应不同产品和缺陷类型的检测需求。
挑战 :
- 数据标注成本高 :高质量的标注数据是深度学习模型训练的基础,但数据标注过程耗时且成本高。
- 模型可解释性差 :深度学习模型通常具有复杂的结构和参数,难以解释其做出决策的具体原因。
- 计算资源要求高 :深度学习模型的训练和推理过程需要大量的计算资源支持,包括高性能的GPU和大规模的数据存储设备等。
四、结论
基于AI深度学习的缺陷检测系统是工业4.0时代的重要技术之一。它利用深度学习算法的强大能力,实现了对生产线上产品的高效、准确检测,为提高产品质量、降低不良品率提供了有力支持。然而,在实际应用中仍面临数据标注成本高、模型可解释性差等挑战。未来随着技术的不断发展和完善,相信基于AI深度学习的缺陷检测系统将在更多领域发挥重要作用。
-
AI
+关注
关注
87文章
31493浏览量
270156 -
缺陷检测
+关注
关注
2文章
144浏览量
12278 -
深度学习
+关注
关注
73文章
5512浏览量
121475
发布评论请先 登录
相关推荐
全网唯一一套labview深度学习教程:tensorflow+目标检测:龙哥教你学视觉—LabVIEW深度学习教程
labview缺陷检测算法写不出来?你OUT了!直接上深度学习吧!
labview深度学习应用于缺陷检测
【HarmonyOS HiSpark AI Camera】基于深度学习的目标检测系统设计
labview深度学习检测药品两类缺陷
射频系统的深度学习【回映分享】
AI视觉检测在工业领域的应用
基于深度学习的小样本墙壁缺陷目标检测及分类
基于深度学习的工业缺陷检测方法
基于深度学习的焊接焊点缺陷检测
一文梳理缺陷检测的深度学习和传统方法
深度学习在工业缺陷检测中的应用

基于深度学习的缺陷检测方案





 工商网监
工商网监
评论