 循环神经网络在端到端语音识别中的应用
循环神经网络在端到端语音识别中的应用
语音识别技术作为人工智能领域的关键应用之一,已经深刻地改变了人们的日常生活和工作方式。从智能手机中的语音助手到智能家居系统的语音控制,语音识别技术无处不在。随着深度学习技术的飞速发展,循环神经网络(Recurrent Neural Networks, RNN)在语音识别领域的应用日益广泛,特别是在端到端语音识别系统中,RNN及其变体如长短期记忆网络(Long Short-Term Memory, LSTM)和门控循环单元(Gated Recurrent Unit, GRU)等,展现了强大的性能。本文将深入探讨循环神经网络在端到端语音识别中的应用,包括其背景、核心算法原理、具体操作步骤、数学模型公式以及未来发展趋势。
一、背景介绍
语音识别技术是将人类语音信号转换为文本信息的过程。传统的语音识别系统通常包括前端信号处理、特征提取、模型训练和解码等多个模块。随着大数据和深度学习技术的普及,端到端的语音识别系统逐渐成为主流。这种系统直接从原始语音信号输入,通过深度学习模型直接输出文本,简化了系统结构,提高了识别精度和效率。
循环神经网络因其能够处理序列数据并捕捉长距离依赖关系的特性,在语音识别任务中表现出色。特别是在处理语音这种具有时间顺序特性的数据时,RNN能够充分利用历史信息,提高识别准确率。
二、核心算法原理
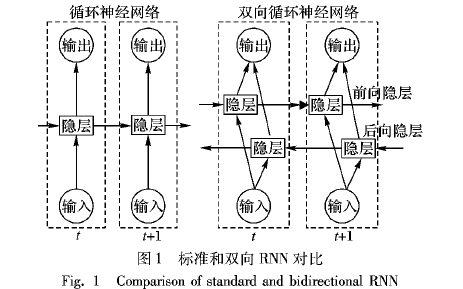
1. 循环神经网络(RNN)
RNN是一种具有反馈连接的神经网络,其基本结构包括输入层、隐藏层和输出层。与传统的前馈神经网络不同,RNN的隐藏层不仅接收当前时间步的输入,还接收上一时间步的隐藏状态,这使得RNN能够处理时间序列数据。
RNN的数学模型可以表示为:
[ h_t = f(W_{hh}h_{t-1} + W_{xh}x_t + b_h) ]
[ y_t = W_{hy}h_t + b_y ]
其中,ht是隐藏层在时间步t的状态,yt是输出层在时间步t的预测结果,xt是时间步t的输入,Whh、Wxh、Why是权重矩阵,bh、by是偏置向量,f是激活函数(如sigmoid或tanh)。
2. 长短期记忆网络(LSTM)
LSTM是RNN的一种变体,通过引入门机制(输入门、遗忘门、输出门)来解决RNN在训练过程中容易出现的梯度消失和梯度爆炸问题。LSTM能够更有效地捕捉序列中的长距离依赖关系。
LSTM的数学模型可以表示为:
[ i_t = sigma(W_{ii}x_t + W_{hi}h_{t-1} + b_i) ]
[ f_t = sigma(W_{if}x_t + W_{hf}h_{t-1} + b_f) ]
[ o_t = sigma(W_{io}x_t + W_{ho}h_{t-1} + b_o) ]
[ g_t = tanh(W_{ig}x_t + W_{hg}h_{t-1} + b_g) ]
[ c_t = f_t odot c_{t-1} + i_t odot g_t ]
[ h_t = o_t odot tanh(c_t) ]
其中,it 、ft 、ot分别为输入门、遗忘门和输出门的状态,gt是候选门状态,ct是单元状态,**⊙**表示逐元素乘法,σ是sigmoid函数。
3. 门控循环单元(GRU)
GRU是LSTM的一种简化版本,它将输入门和遗忘门合并为更新门,同时简化了门控机制。GRU在保持LSTM大部分优点的同时,减少了计算量和模型复杂度。
GRU的数学模型可以表示为:
[ z_t = sigma(W_{zz}x_t + W_{hz}h_{t-1} + b_z) ]
[ r_t = sigma(W_{rr}x_t + W_{hr}h_{t-1} + b_r) ]
[ tilde{h} t = tanh(W {xz}x_t + W_{hz}(r_t odot h_{t-1}) + b_h) ]
[ h_t = (1 - z_t) odot h_{t-1} + z_t odot tilde{h}_t ]
三、端到端语音识别系统设计与实现
1. 系统架构
端到端语音识别系统通常包含以下几个关键组件:特征提取层、编码层、解码层以及后处理模块。尽管在深度学习中,特征提取往往被嵌入到模型中自动完成,但在实际部署时,可能仍需对原始语音信号进行预处理,如分帧、加窗、预加重等,以提取适合模型处理的特征。
- 特征提取层 :虽然在现代端到端系统中,如使用WaveNet或Conv-RNN等架构,可以直接从原始波形中学习特征,但在一些系统中,仍可能采用MFCC(Mel频率倒谱系数)等传统特征作为输入。
- 编码层 :这一层主要负责将特征序列编码为高级抽象表示,通常使用RNN、LSTM、GRU或其变体来实现。这些模型能够捕捉语音中的时序依赖性和上下文信息。
- 解码层 :解码层将编码后的高级表示转换为文本序列。在CTC(Connectionist Temporal Classification)框架下,解码层可以直接输出字符序列的概率分布,并通过贪心搜索或束搜索等方法找到最可能的文本。在注意力机制(Attention Mechanism)的模型中,解码器(如LSTM或GRU)与编码器通过注意力权重相连接,实现动态的对齐和解码。
- 后处理模块 :后处理模块用于优化解码结果,包括语言模型(Language Model, LM)重打分、拼写校正等。语言模型能够利用语言学的先验知识,提高识别结果的流畅性和准确性。
2. 训练与优化
- 损失函数 :在训练过程中,常用的损失函数包括CTC损失和交叉熵损失。CTC损失特别适用于序列到序列的映射问题,它允许模型在输出序列与标签序列之间存在一定的“错位”。
- 优化算法 :通常采用梯度下降算法或其变体(如Adam、RMSprop)来优化模型参数。由于RNN及其变体容易遭遇梯度消失或梯度爆炸问题,因此在训练时可能需要采用梯度裁剪、学习率衰减等策略。
- 正则化与过拟合 :为了防止过拟合,可以在模型中引入正则化项(如L1/L2正则化)、使用dropout等技术。此外,还可以采用早停(early stopping)策略,在验证集性能开始下降时停止训练。
3. 实际应用与挑战
- 实时性 :在实时语音识别系统中,模型的推理速度至关重要。因此,需要优化模型结构、减少参数数量或使用更快的硬件加速技术。
- 噪声与口音 :噪声和口音是语音识别中常见的挑战。为了提高系统的鲁棒性,可以在训练数据中加入各种噪声和口音样本,或使用数据增强技术。
- 隐私与安全 :随着语音识别技术的普及,用户隐私和数据安全成为重要议题。需要采取加密技术、差分隐私等措施来保护用户数据。
4. 未来发展趋势
- 多模态融合 :结合语音、文本、图像等多种模态的信息,可以进一步提高语音识别系统的准确性和鲁棒性。
- 自监督学习 :利用大规模未标注数据进行自监督学习,可以预训练出具有强大表征能力的模型,再通过少量标注数据进行微调。
- 轻量化与边缘计算 :为了满足移动设备和物联网场景的需求,需要开发轻量化的语音识别模型,并结合边缘计算技术实现低延迟、高隐私保护的语音识别服务。
综上所述,循环神经网络及其变体在端到端语音识别系统中发挥着关键作用。随着技术的不断进步和应用的不断扩展,我们有理由相信未来的语音识别系统将更加智能、高效和可靠。
-
语音识别
+关注
关注
38文章
1739浏览量
112638 -
人工智能
+关注
关注
1791文章
47208浏览量
238291 -
循环神经网络
+关注
关注
0文章
38浏览量
2967
发布评论请先 登录
相关推荐







 工商网监
工商网监
评论