 K8S学习教程三:在PetaExpress KubeSphere 容器部署 Wiki 系统 wiki.js 并启用中文全文检索
K8S学习教程三:在PetaExpress KubeSphere 容器部署 Wiki 系统 wiki.js 并启用中文全文检索
背景
wiki.js 是非常优秀的开源 Wiki 系统,尽管在与 xwiki 功能相比 ,还不算完善,但也在不断进步。 常用的功能还是比较实用的,如:Wiki 写 作、分享、权限管理功能还是非常实用的,UI 设计非常的漂亮,精美的界面和直观的操作体验,能够满足小团队的基本知识管理需求。
认真阅读全文,教你怎么领取礼品
我们需要在 PetaExpress KubeSphere 容器平台中部署 Kubernetes集群
在 Peta Express 中部署 Kubernetes 非常的简单方便,直接使用 PetaExpress 中内置的 QKE 就可以了,首先我们需要登录到 PetaExpress 控制台(登录地址:https://cn.petaexpress.com ),在产品与服务中找到 AppCenter 控制台 → 应用中心。
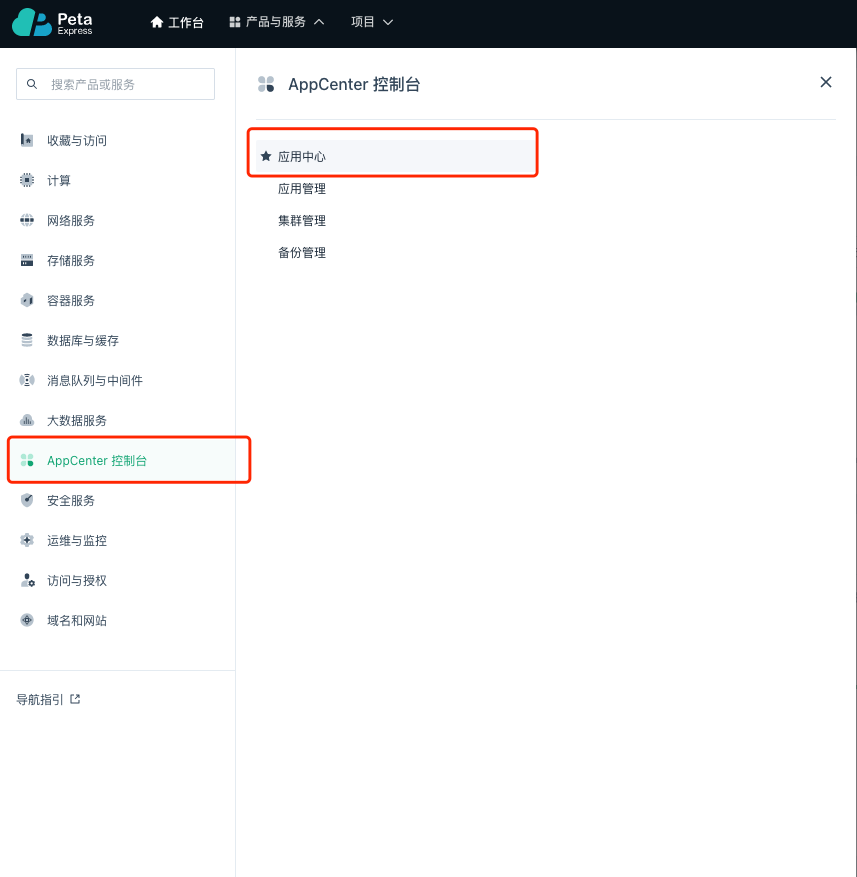
找到 QKE 立即部署即可。
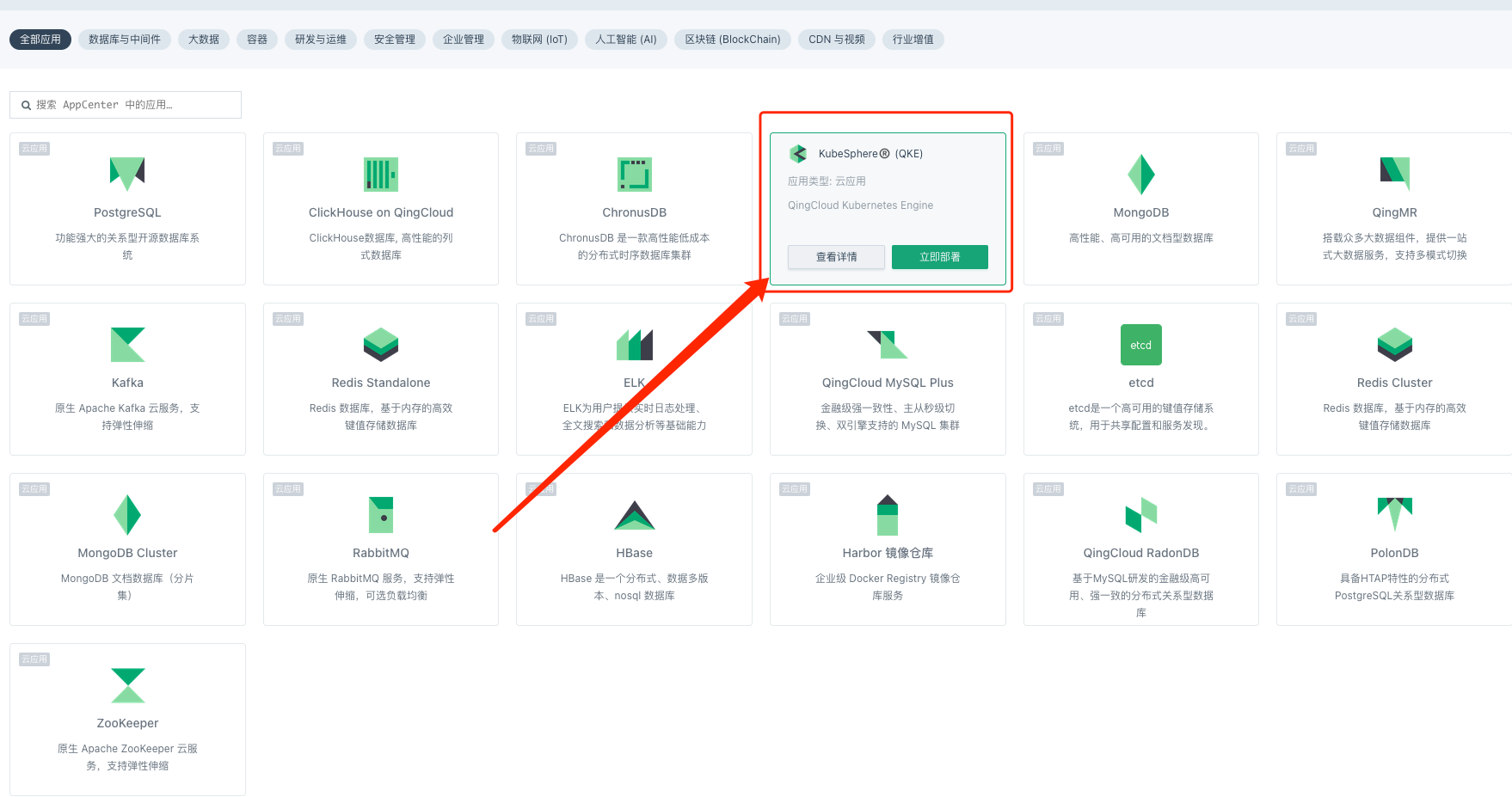
按照提示输入名称,选择集群规模等关键信息,然后提交就可以了。但需要注意集群的配置,如果是开发测试可以选择 “基础型开发环境” 或 “企业型测试环境”,如果是生产的话则可以选择 “基础型生产环境” 或 “企业型生产环境”,也可以自定义集群规模和HA。
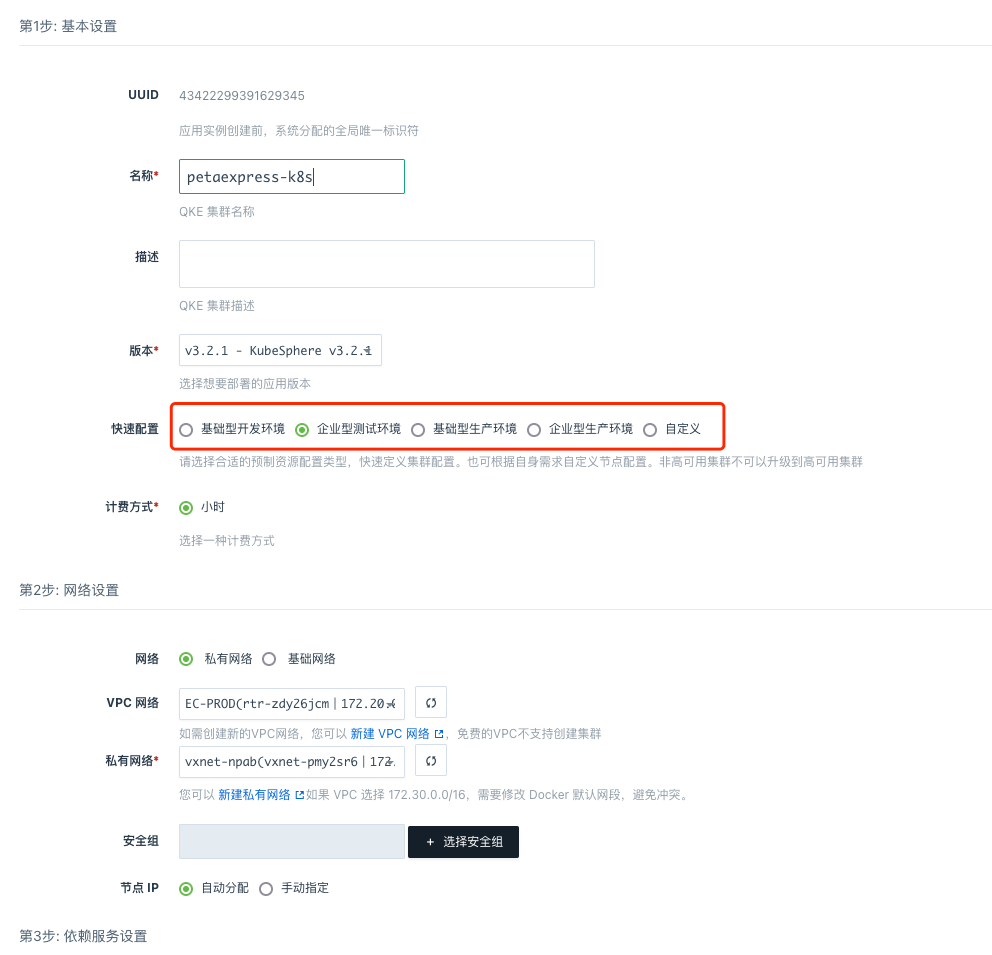
根据集群的规模,部署时间大致2分钟到10分钟不等,速度还是非常的快的,能在极短的时间内完成。部署完 Kubernetes(K8S),需要安装 OpenEBS,完成这一环节后就可以安装 Redis 了。
准备 storageclass
我们使用 OpenEBS 作为存储,OpenEBS 默认安装的 Local StorageClass 在 Pod 销毁后自动删除,不适合用于我的数据存储,我们在
Local StorageClass 基础上稍作修改,创建新的 StorageClass,允许 Pod 销毁后,PV 内容继续保留,手动决定怎么处理。
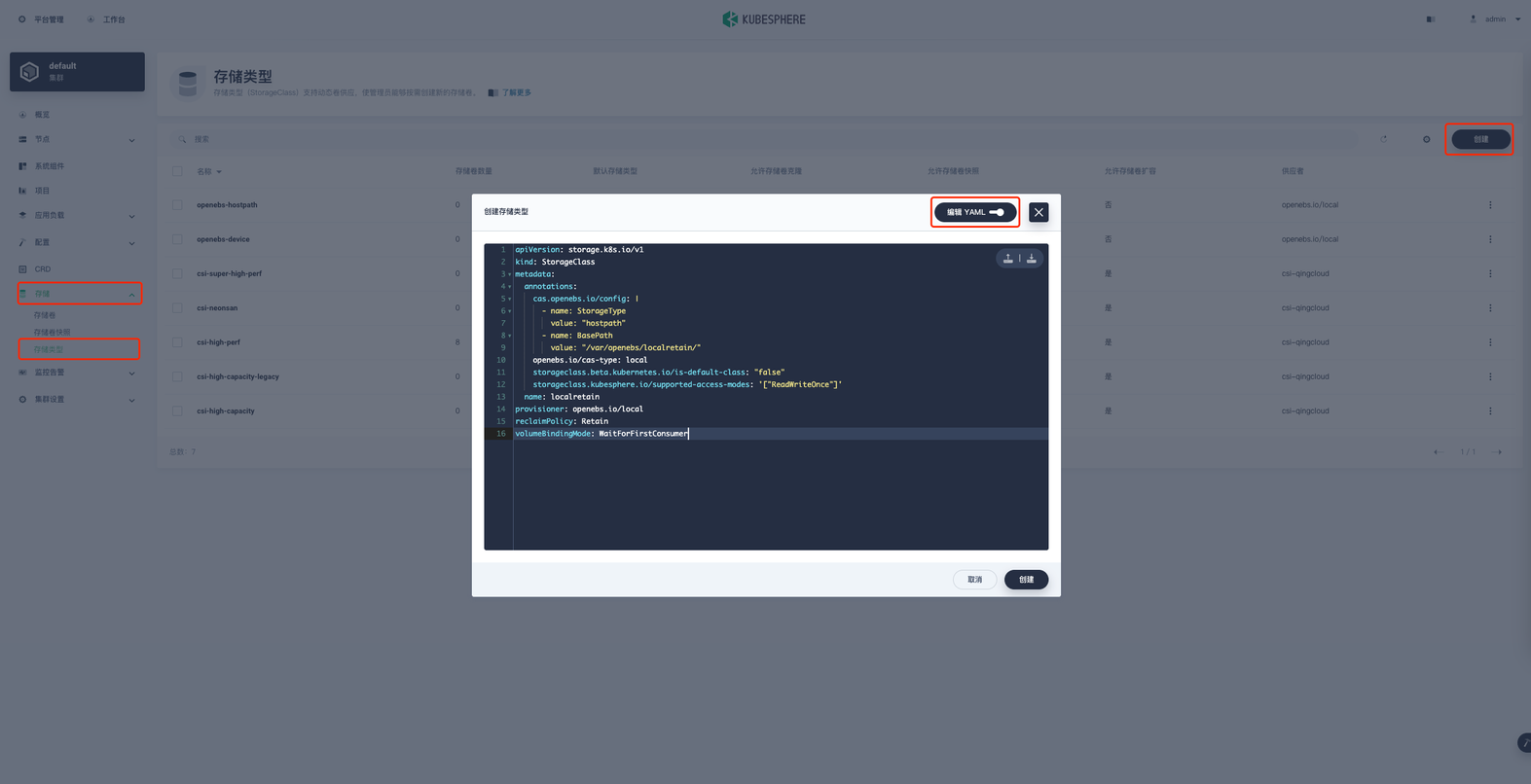
在项目空间的 存储 → 存储类型 → 创建 进行storageClass的创建
名称:localretain
存储系统:自定义
存储卷扩容:否
回收机制:Retain
访问模式:ReadWriteOnce
存储系统:openebs.io/local
存储卷延迟绑定:延迟绑定编辑完成后点击创建,或直接点击 编辑YAML ,将以下yaml内容粘贴后点击创建
部署 PostgreSQL 数据库
鉴于我们团队在多个项目中也需要使用 PostgreSQL, 为了提高 PostgreSQL 数据库的利用率和统一管理,我们独立部署 PostgreSQL,并在
安装 wiki.js 时,配置为使用外部数据库。
准备用户名密码配置
我们使用 Secret 保存 PostgreSQL 用户密码等敏感信息。
在项目空间的 配置 → 保密字典 → 创建 进行保密字典的创建。
1 apiVersion: storage.k8s.io/v1
2 kind: StorageClass
3 metadata:
4annotations:
5cas.openebs.io/config: |
6- name: StorageType
7value: "hostpath"
8- name: BasePath
9value: "/var/openebs/localretain/"
10openebs.io/cas-type: local
11storageclass.beta.kubernetes.io/is-default-class: "false"
12storageclass.kubesphere.io/supported-access-modes: '["ReadWriteOnce"]'
13name: localretain
14 provisioner: openebs.io/local
15 reclaimPolicy: Retain
16 volumeBindingMode: WaitForFirstConsumer
部署 PostgreSQL 数据库
鉴于我们团队在多个项目中也需要使用 PostgreSQL, 为了提高 PostgreSQL 数据库的利用率和统一管理,我们独立部署 PostgreSQL,并在
安装 wiki.js 时,配置为使用外部数据库。
准备用户名密码配置
我们使用 Secret 保存 PostgreSQL 用户密码等敏感信息。
在项目空间的 配置 → 保密字典 → 创建 进行保密字典的创建。
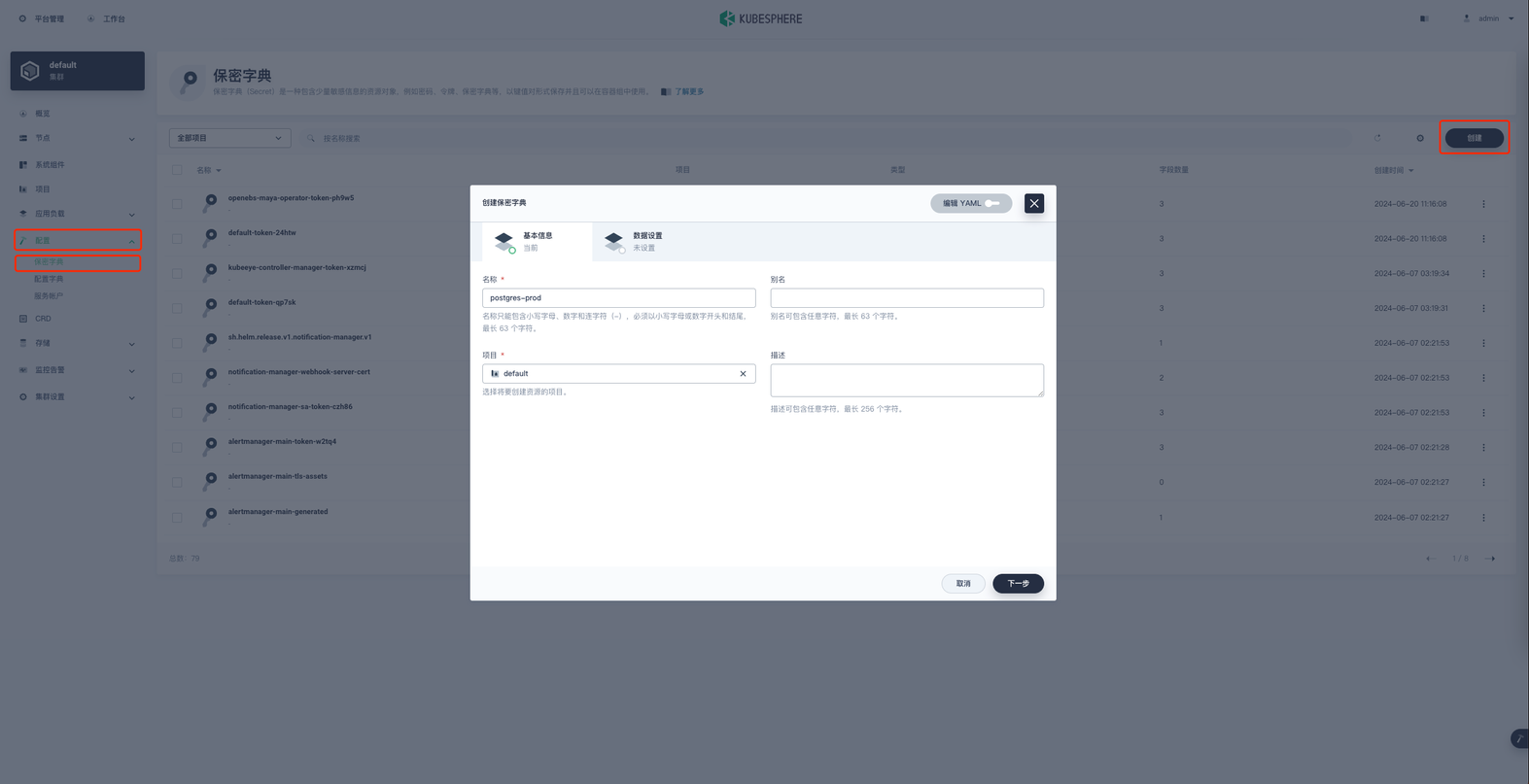
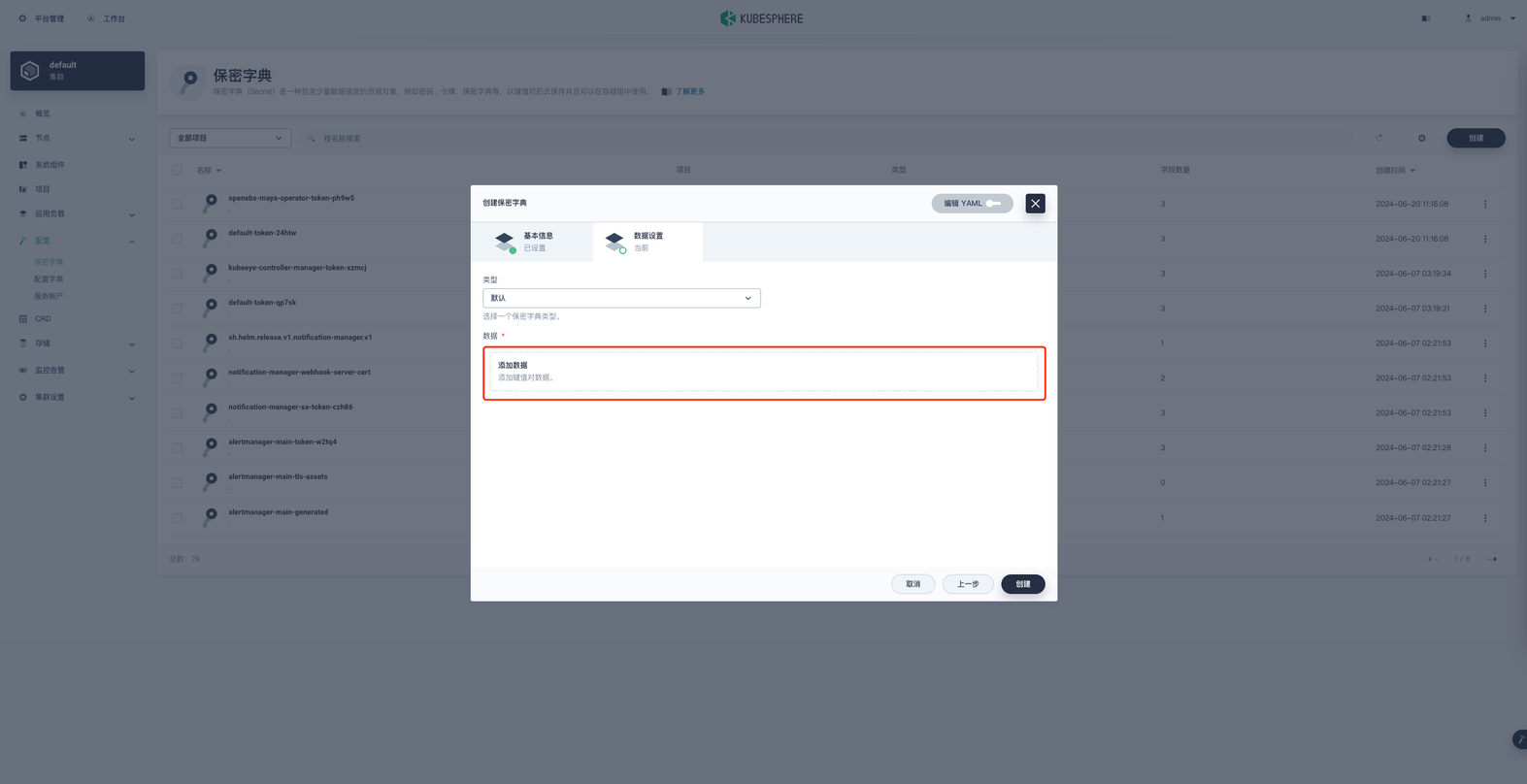
首先我们定义一个名称就叫 postgres-prod 点击下一步,类型保持默认设置即可, 添加键值对数据。
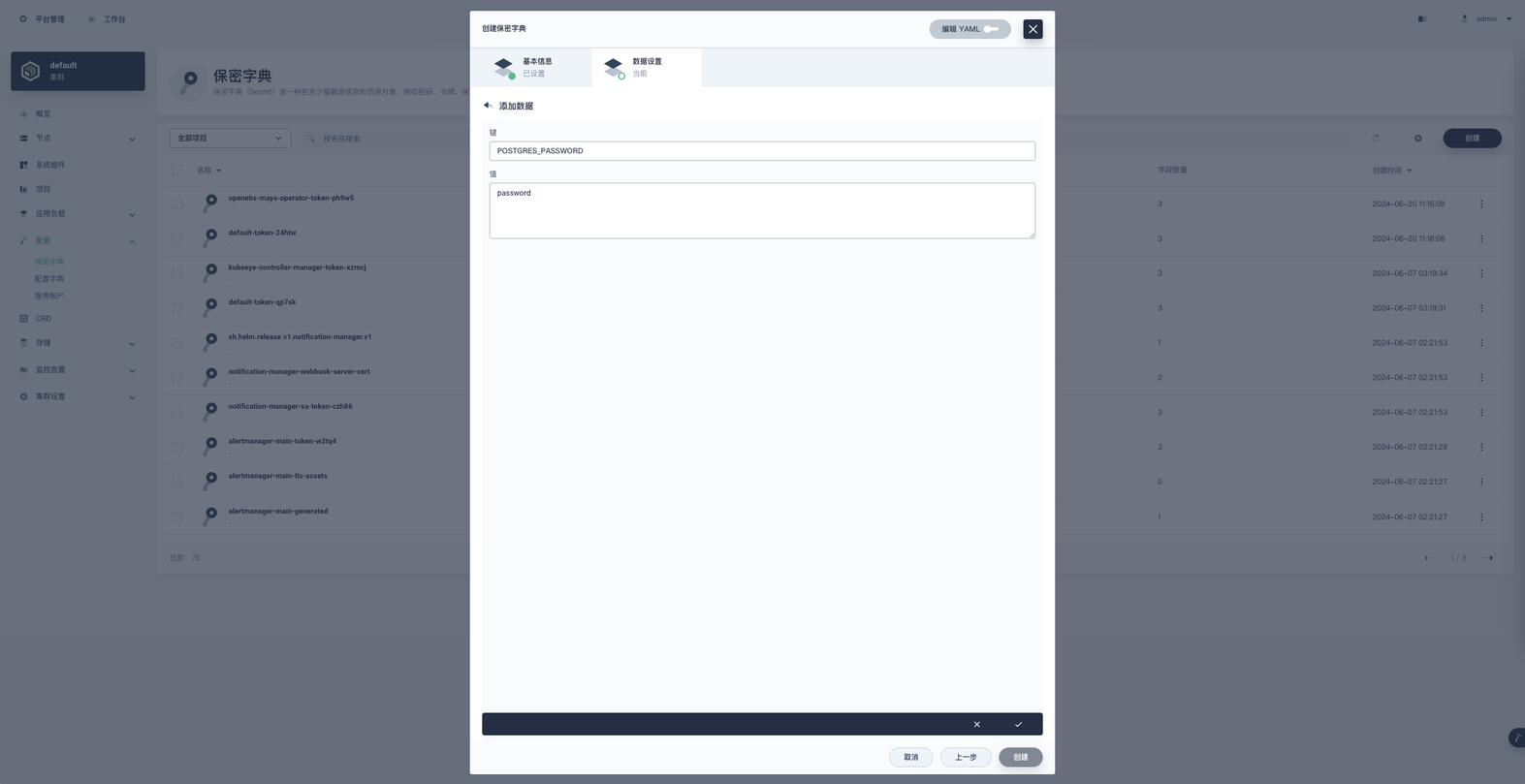
键为 POSTGRES_PASSWORD ,值为 password ( 密码自行准备修改 )
准备数据库初始化脚本
使用 ConfigMap 保存数据库初始化脚本,在 数据库创建时,将 ConfigMap 中的数据库初始化脚本挂载到 /docker-entrypoint-initdb.d, 容器初 始化时会自动执行该脚本。
在项目空间的 配置 → 配置字典 → 创建 进行配置字典的创建。
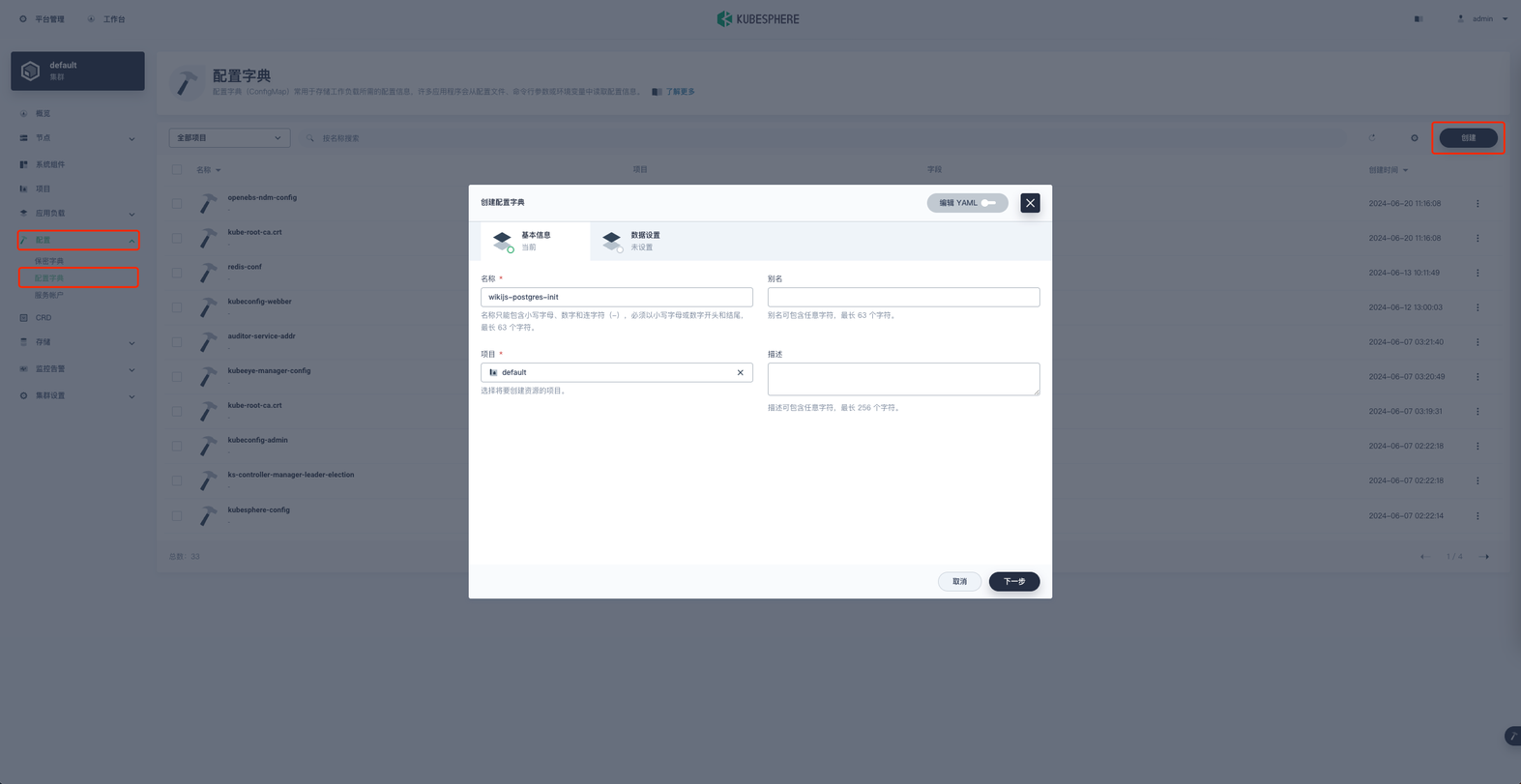
名称就叫 wikijs-postgres-init 然后下一步,添加键值对数据。
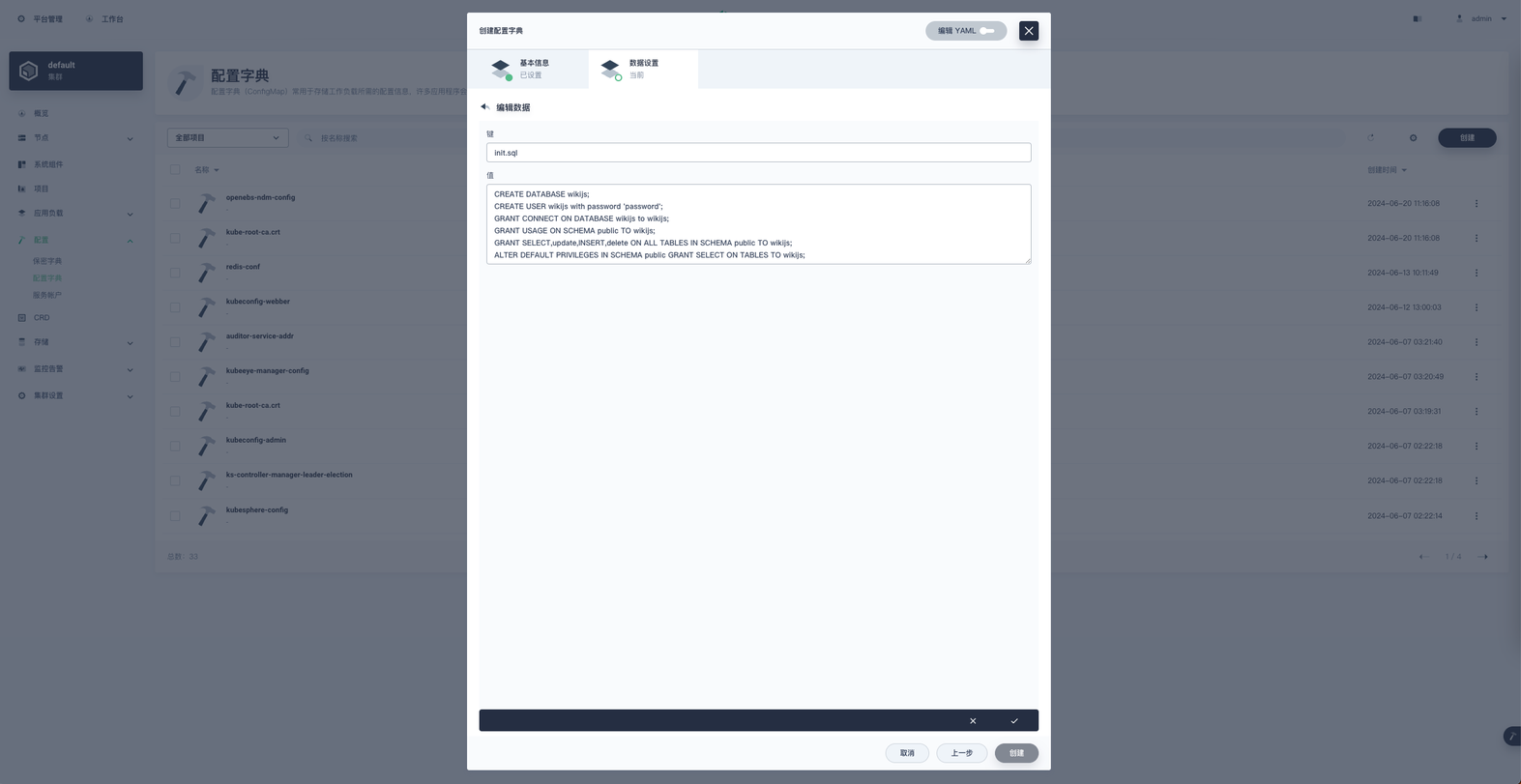
键为 init.sql ,值为
1CREATE DATABASE wikijs;
2CREATE USER wikijs with password 'password';
3GRANT CONNECT ON DATABASE wikijs to wikijs;
4GRANT USAGE ON SCHEMA public TO wikijs;
5GRANT SELECT,update,INSERT,delete ON ALL TABLES IN SCHEMA public TO wikijs;
6ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO wikijs;
以上 wikijs 用户的密码自行准备,明文保存。
准备存储
我们使用 OpenEBS 来提供存储服务。可以通过创建 PVC 来提供持久化存储。
这里声明一个 10G 的 PVC。
需按照以下步骤操作
在项目空间的 存储 → 存储卷 → 创建 进行PVC的创建。
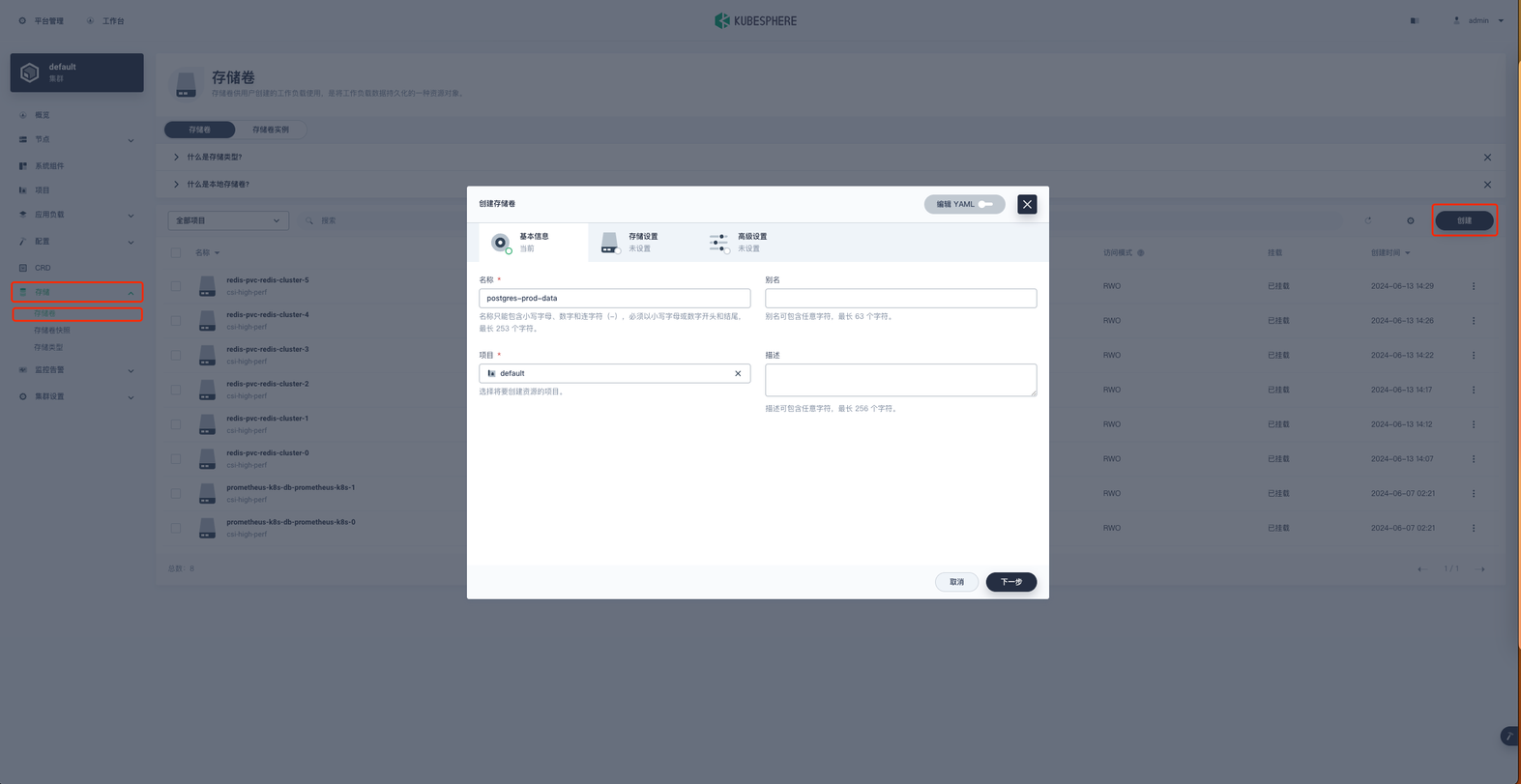
名称就叫 postgres-prod-data ,然后下一步,进行存储设置。
存储类型: localretain
访问模式: ReadWriteOnce
存储卷容量: 10G
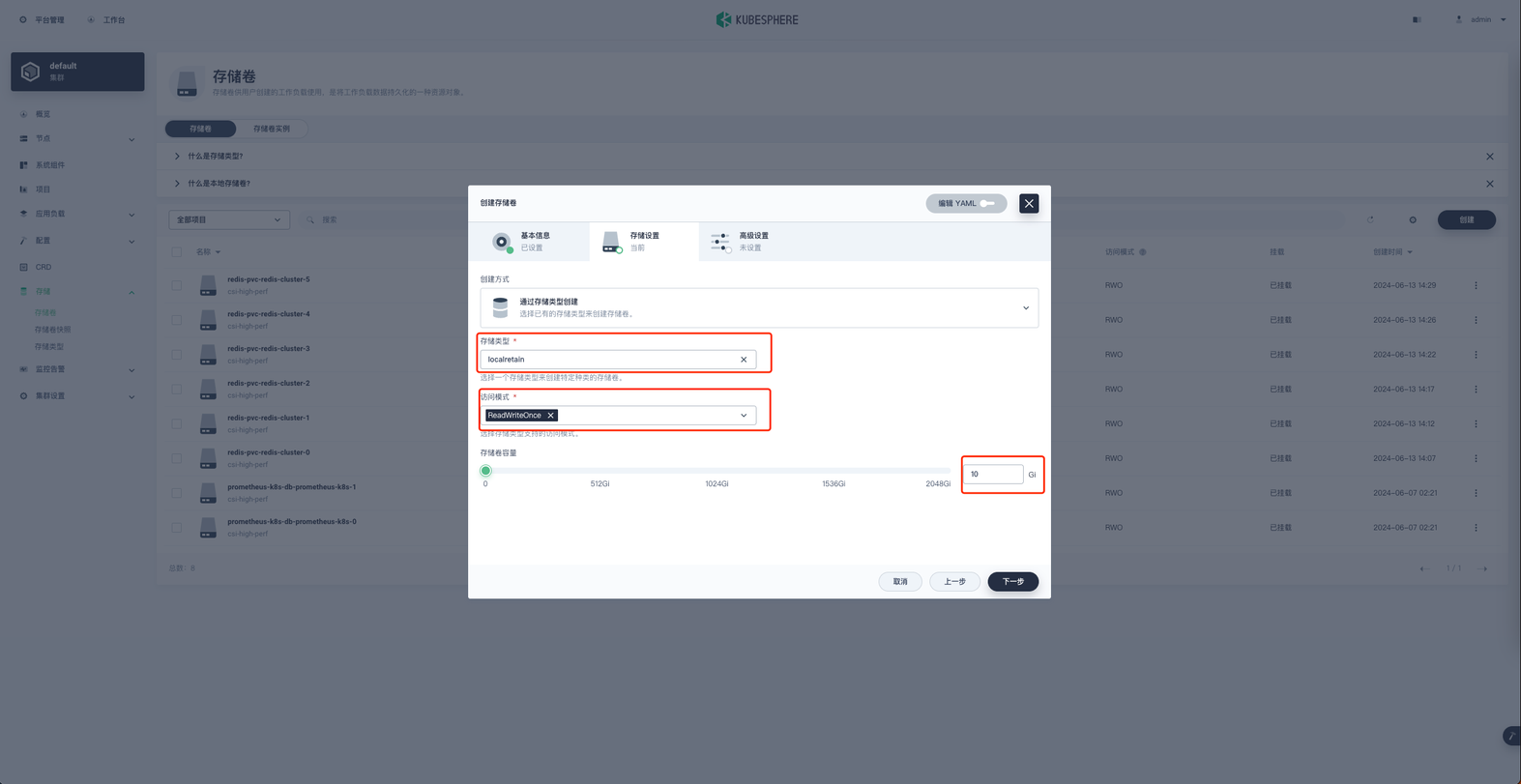
高级设置无需修改,点击创建按钮即可。
部署 PostgreSQL 数据库
在前面的步骤准备好各种配置信息和存储后,就可以开始部署 PostgreSQL 服务了。
我们的 Kubernetes 没有配置存储阵列,使用的是 OpenEBS 作为存储,采用 Deployment 方式部署 PostgreSQL。
需按照以下步骤操作
在项目空间的 应用负载 → 工作负载 → 部署 → 创建 进行 PostgreSQL 服务的创建。
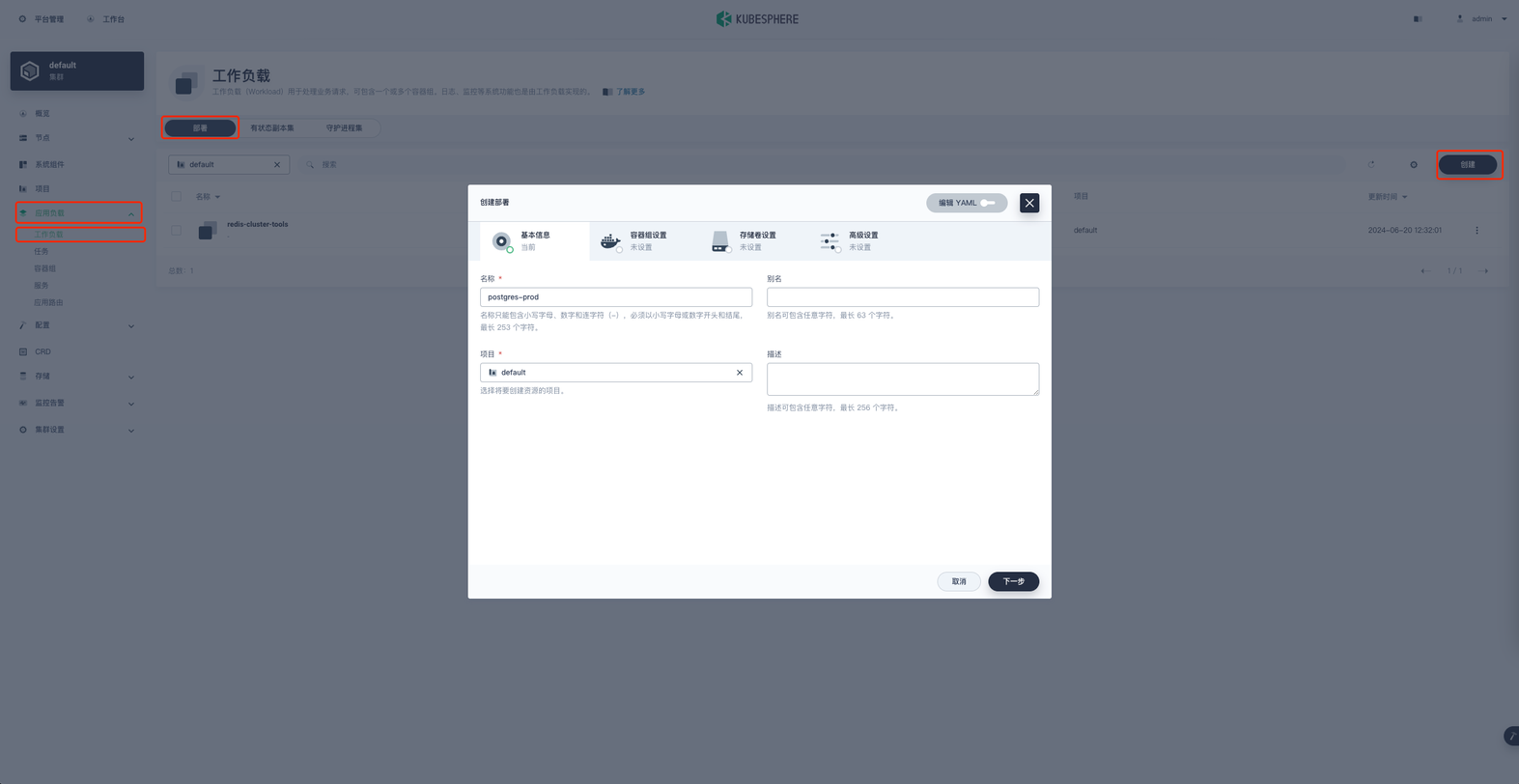
基本信息里名称就叫做 postgres-prod ,然后进行下一步容器组设置
容器组配置
这一步的核心就是配置 postgres 的容器。
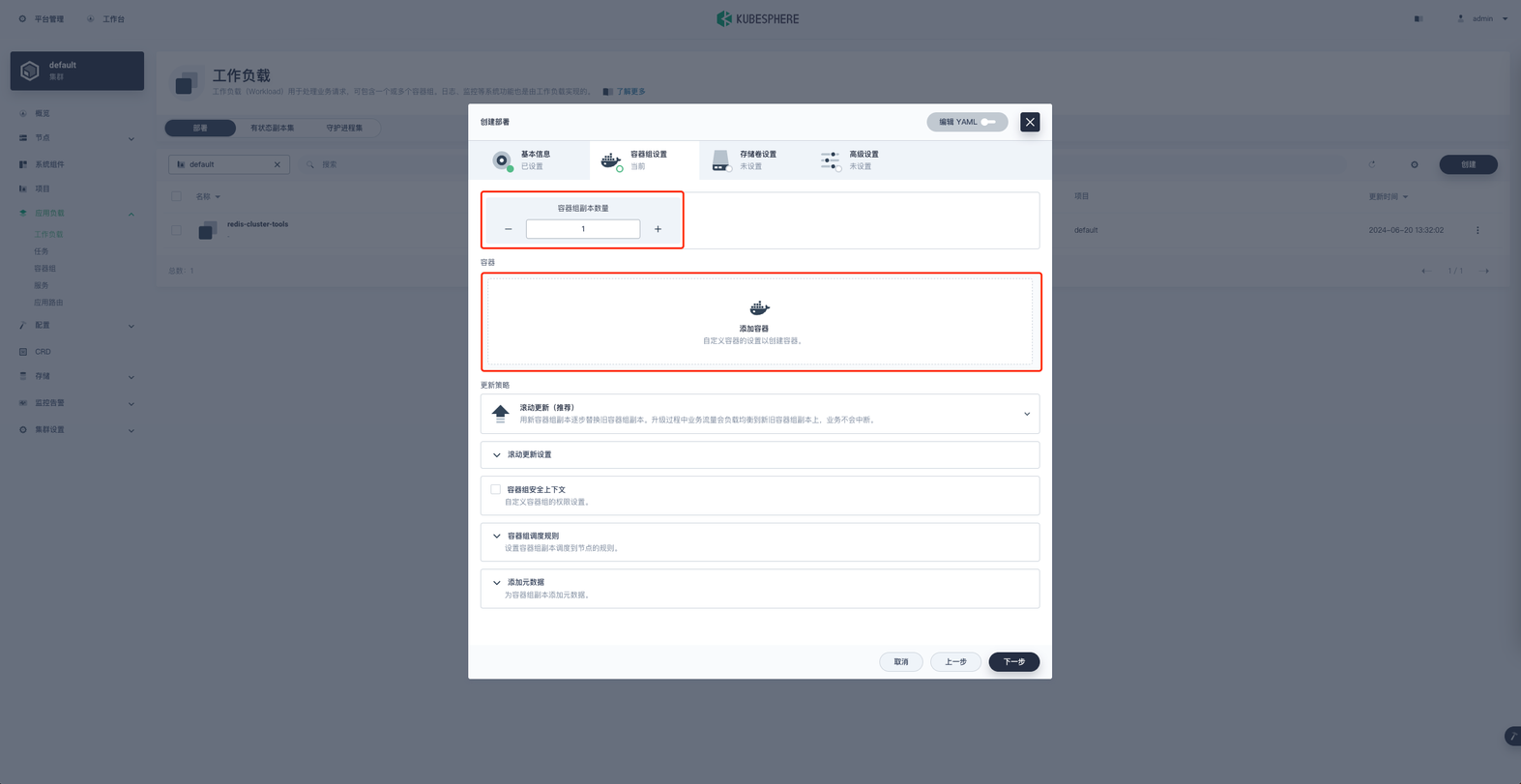
容器组副本数量选择1,点击添加容器镜像选择 dockerhub 中的 abcfy2/zhparser:12-alpine ,并选择使用默认端口,容器名称改为 postgres-prod
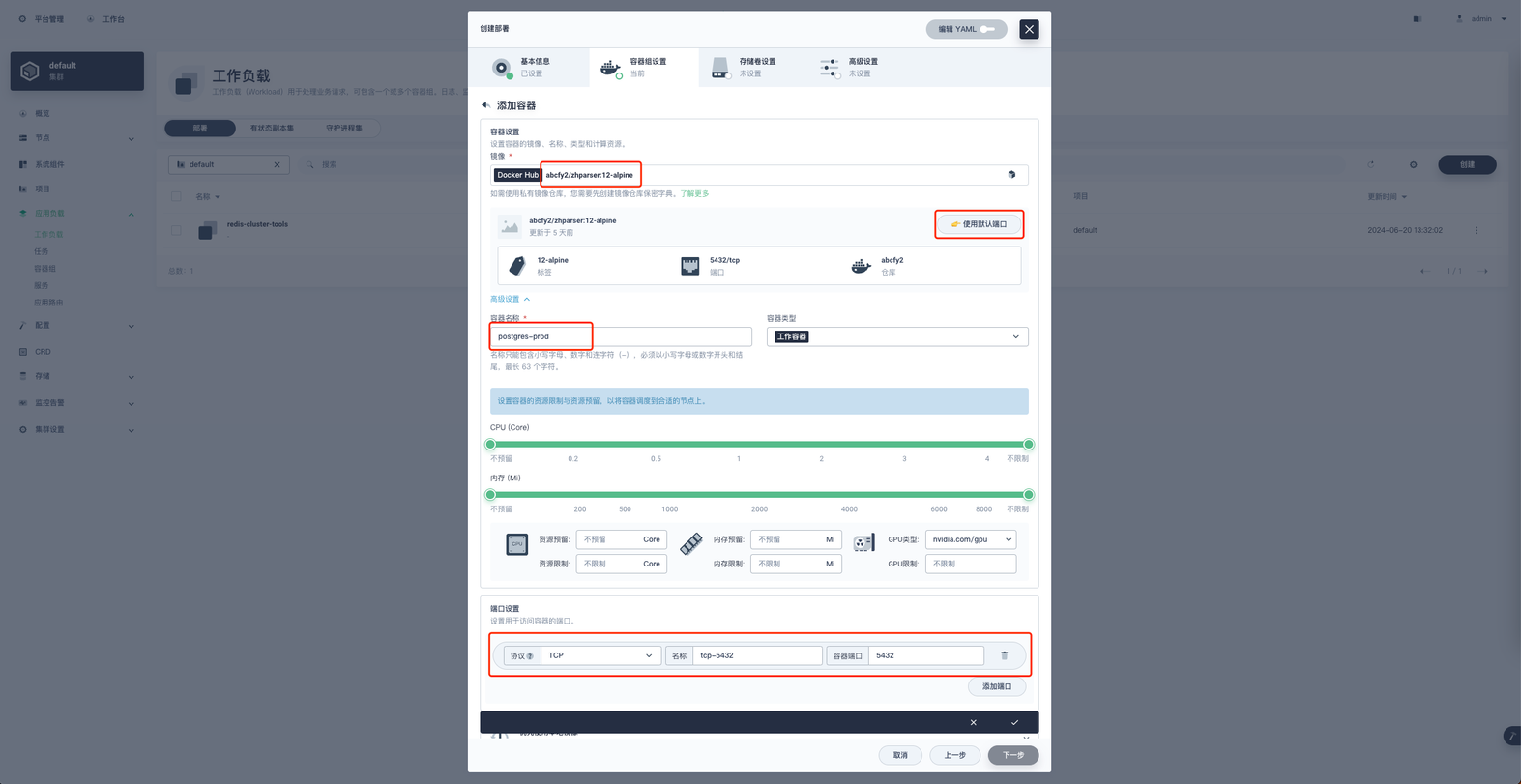
勾选 环境变量 ,点击 引用配置字典或保密字典 ,资源选择 postgres-prod 保密字典,资源中的键选择 POSTGRES_PASSWORD ,之后点击对勾完成容器配置,点击下一步配置 存储卷设置
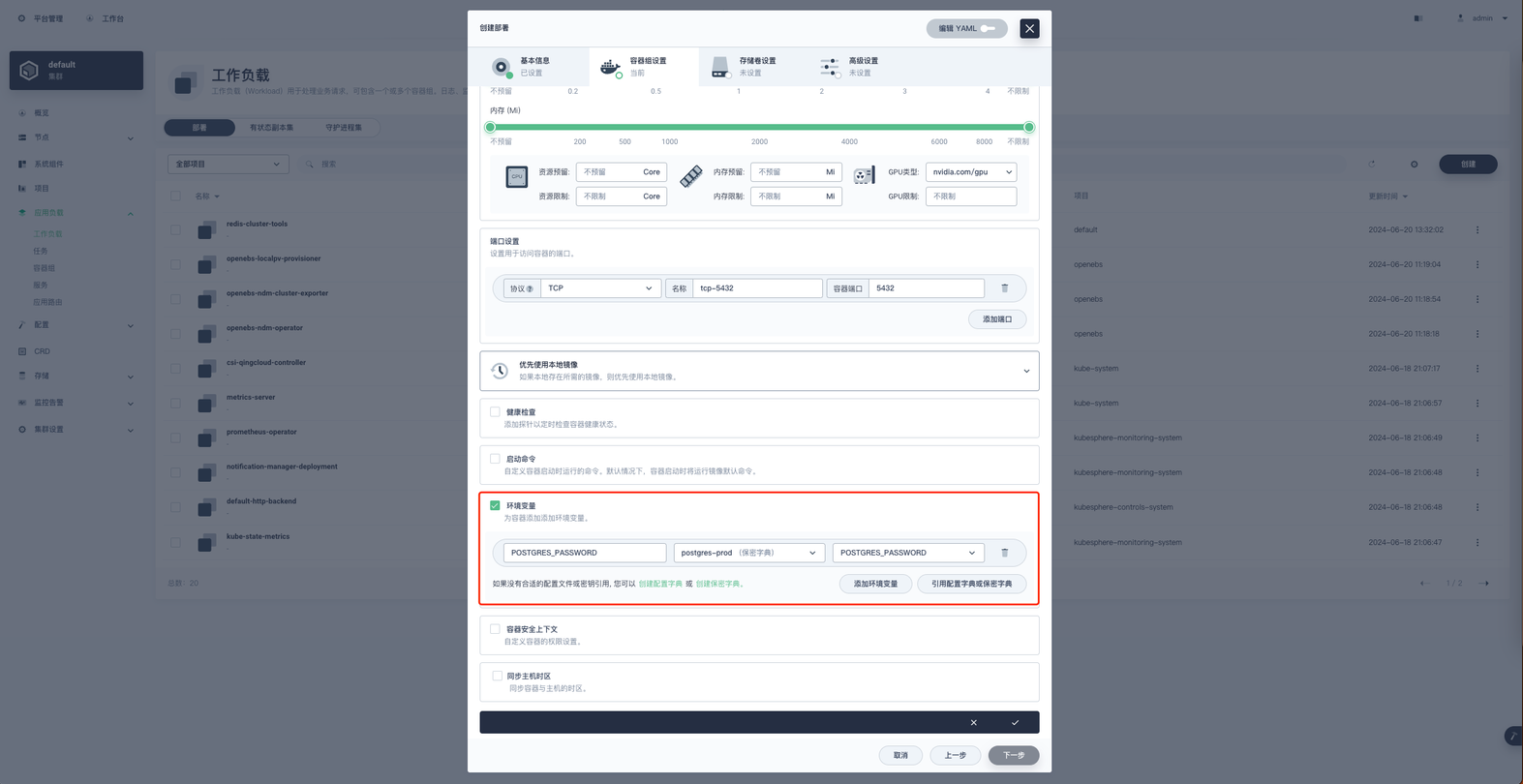
存储设置
在这一步有两个操作
挂载存储卷
挂载配置字典
挂载存储卷
选择现有存储卷 postgres-prod-data ,权限为读写,挂载地址为 /var/lib/postgresql/data ,配置好后点击对勾完成配置
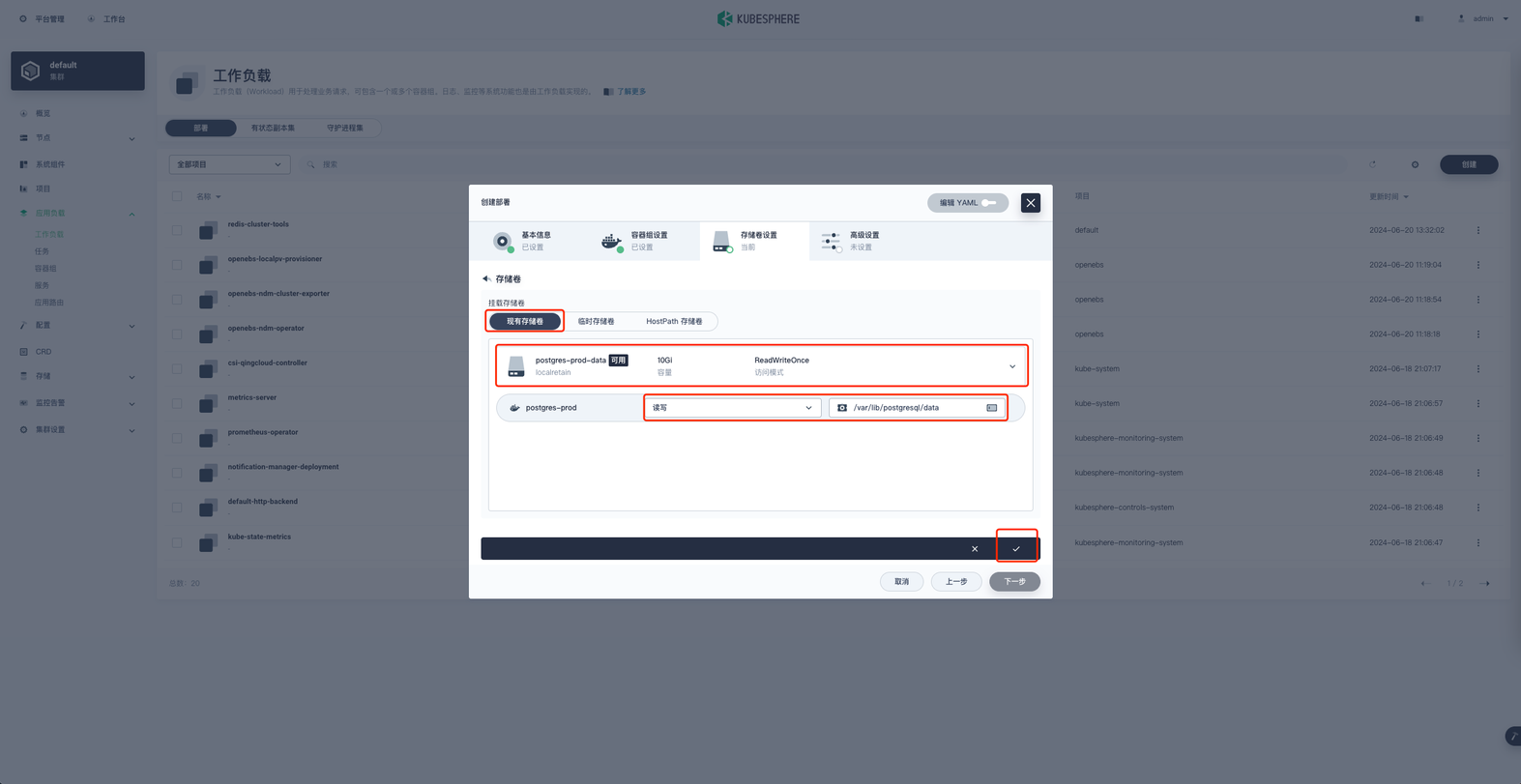
挂载配置字典
选择配置字典 wikijs-postgres-init ,权限为只读,挂载地址为 /docker-entrypoint-initdb.d ,配置好后点击对勾完成配置
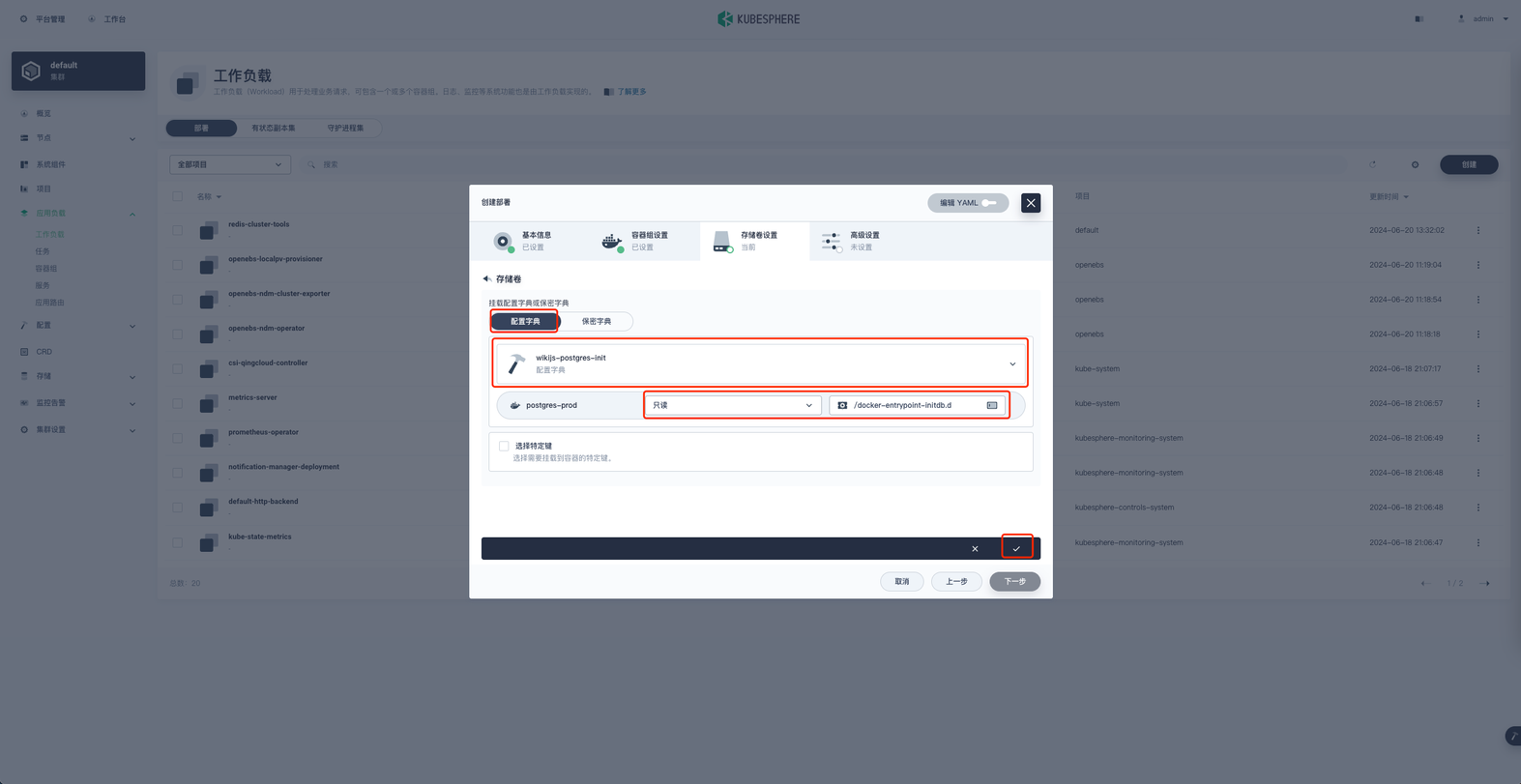
配置好后如下图
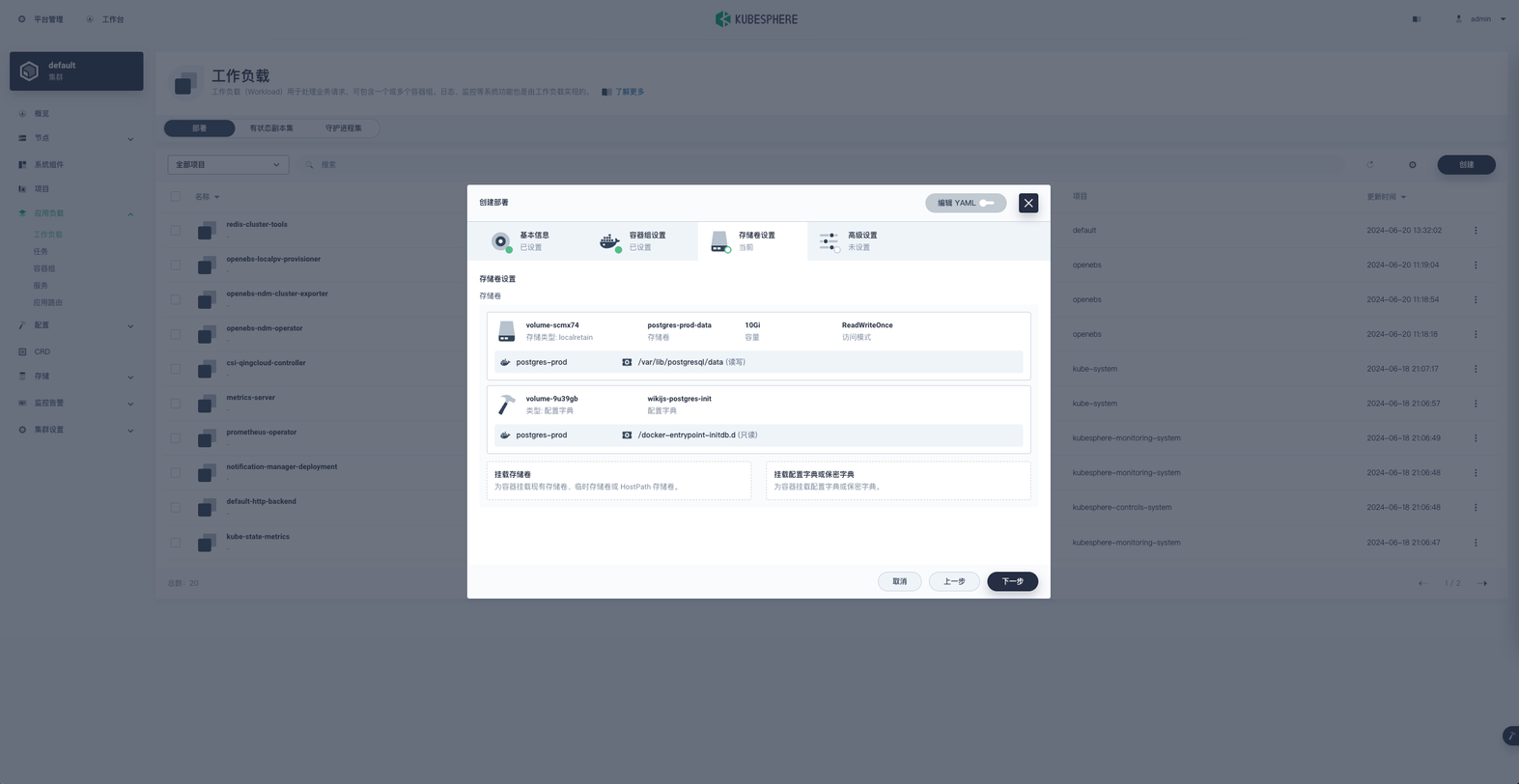
点击下一步进入最后的高级设置
高级设置 里是一些额外配置,可以根据自己场景选择调整配置,调整完成后点击 创建 。创建供其他 Pod 访问的 Service
在项目空间的 应用负载 → 服务 → 创建 进行服务的创建
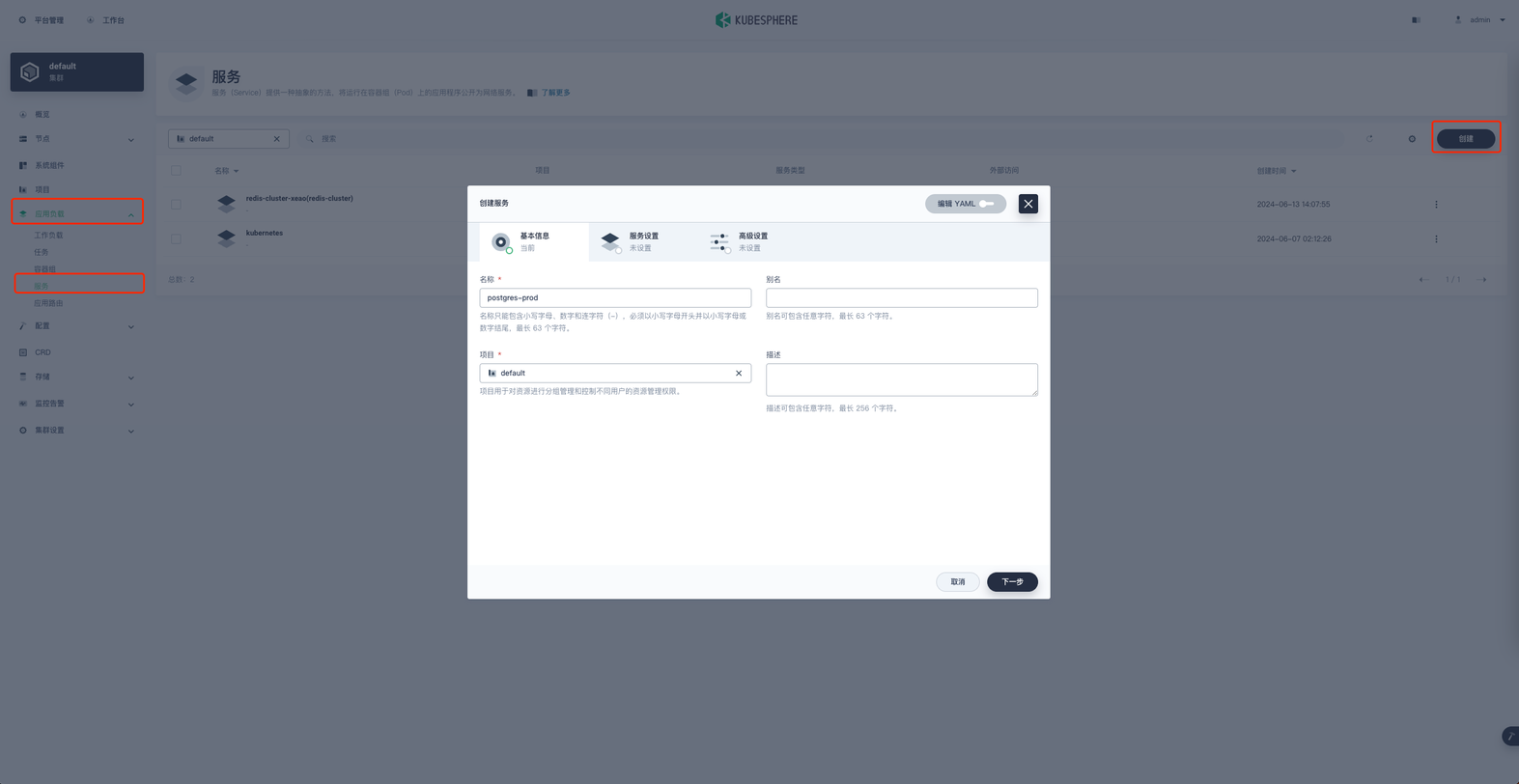
名称就叫 postgres-prod 然后下一步,进入服务设置
内部访问模式选择 虚拟IP地址 ,指定工作负载选择 postgres-prod
端口协议:TCP
端口名称:tcp-5432
容器端口:5432
服务端口:5432
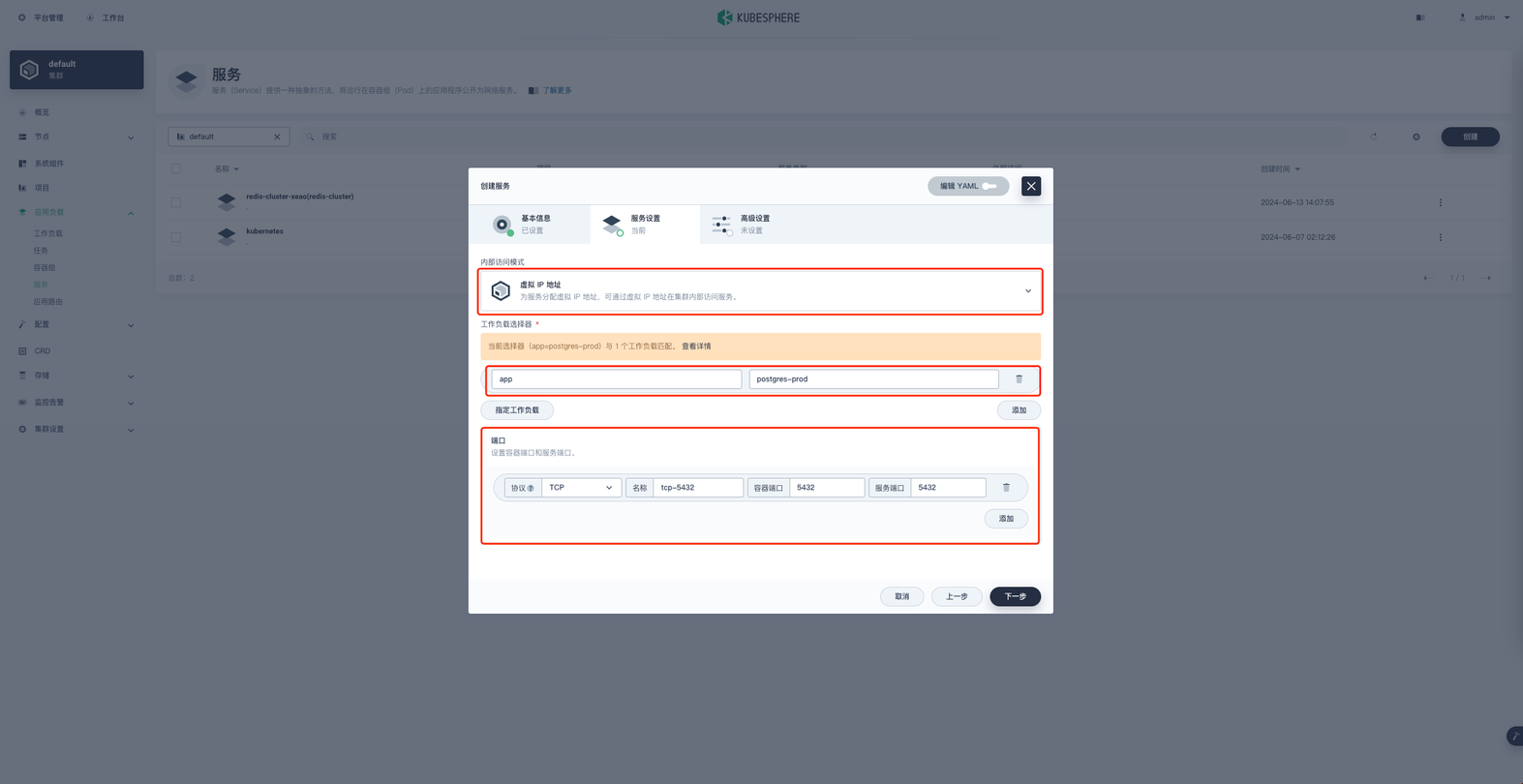
点击下一步进入高级设置
高级设置 里是一些额外配置,可以根据自己场景选择调整配置,调整完成后点击 创建 。
部署 wiki.js
准备用户名密码配置
我们使用 Secret 保存 wiki.js 用于连接数据库的用户名密码等敏感信息。
在项目空间的 配置 → 保密字典 → 创建 进行保密字典的创建。
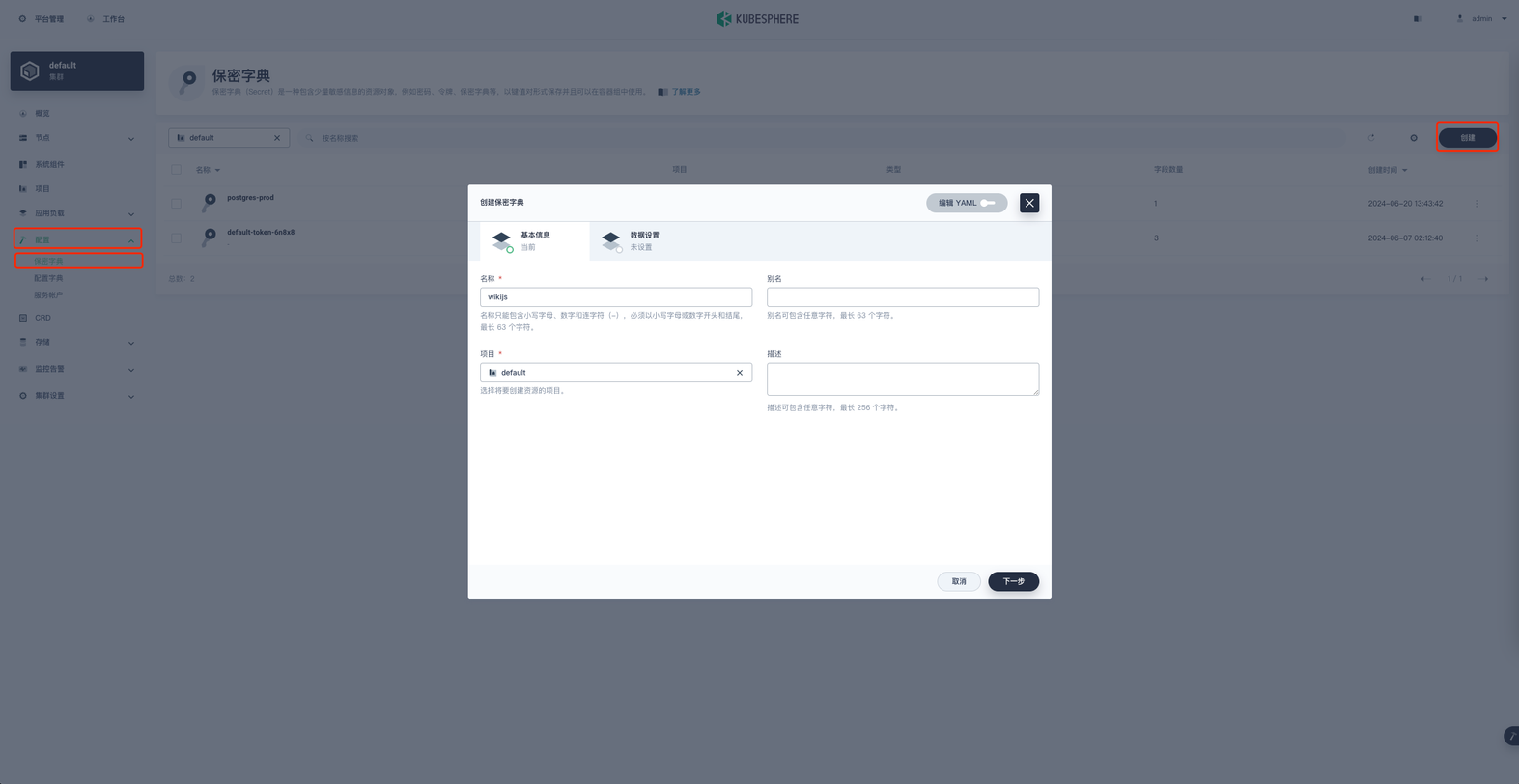
名称就叫 wikijs 然后下一步,类型选择默认, 添加键值对数据。
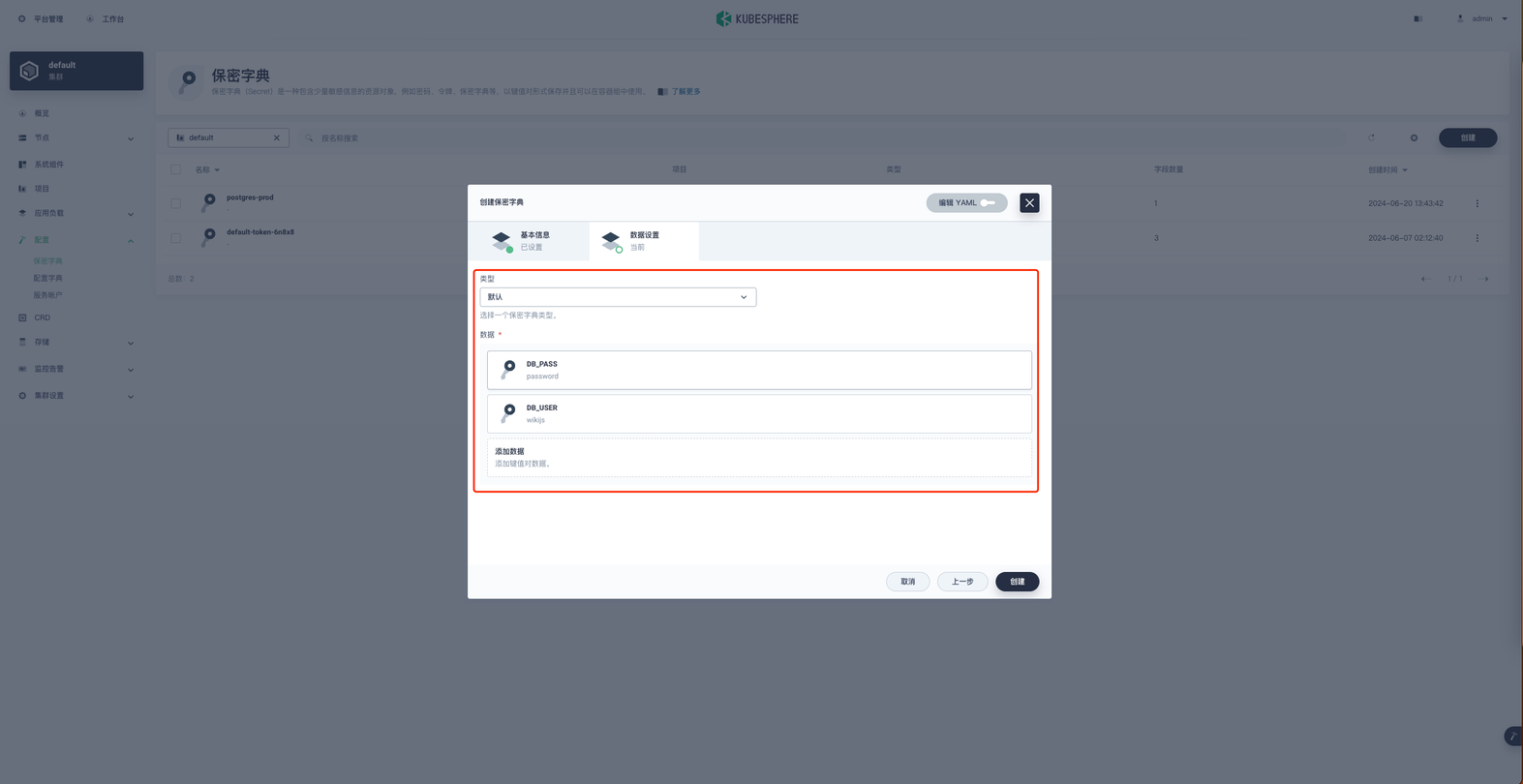
键为 DB_USER ,值为 wikijs ( 和上方初始化脚本中的用户名保持一致 )
键为 DB_PASS ,值为 password ( 和上方初始化脚本中的密码保持一致 )
准备数据库连接配置
我们使用 ConfigMap 保存 wiki.js 的数据库连接信息。
在项目空间的 配置 → 配置字典 → 创建 进行配置字典的创建。
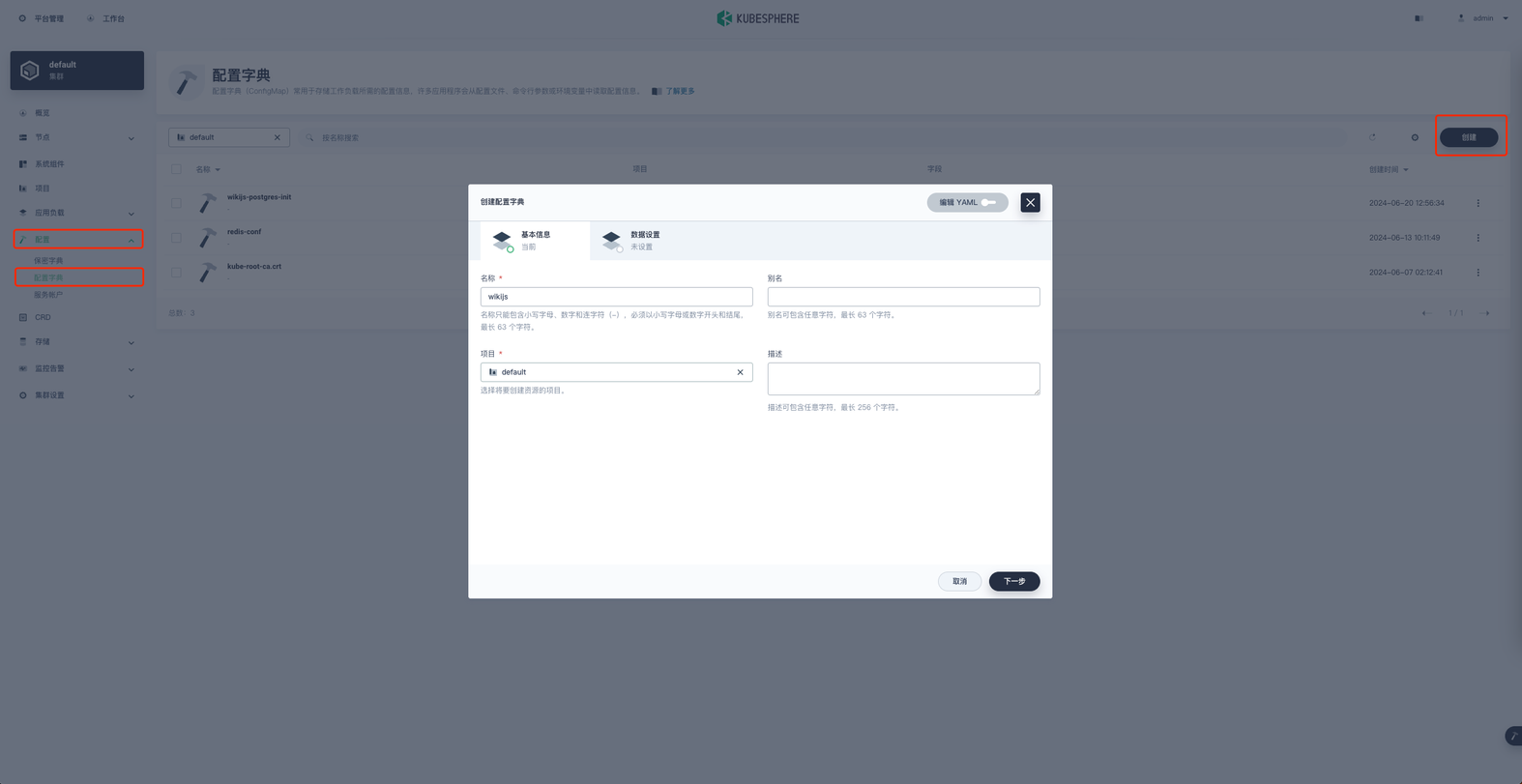
名称就叫 wikijs 然后下一步,添加键值对数据。
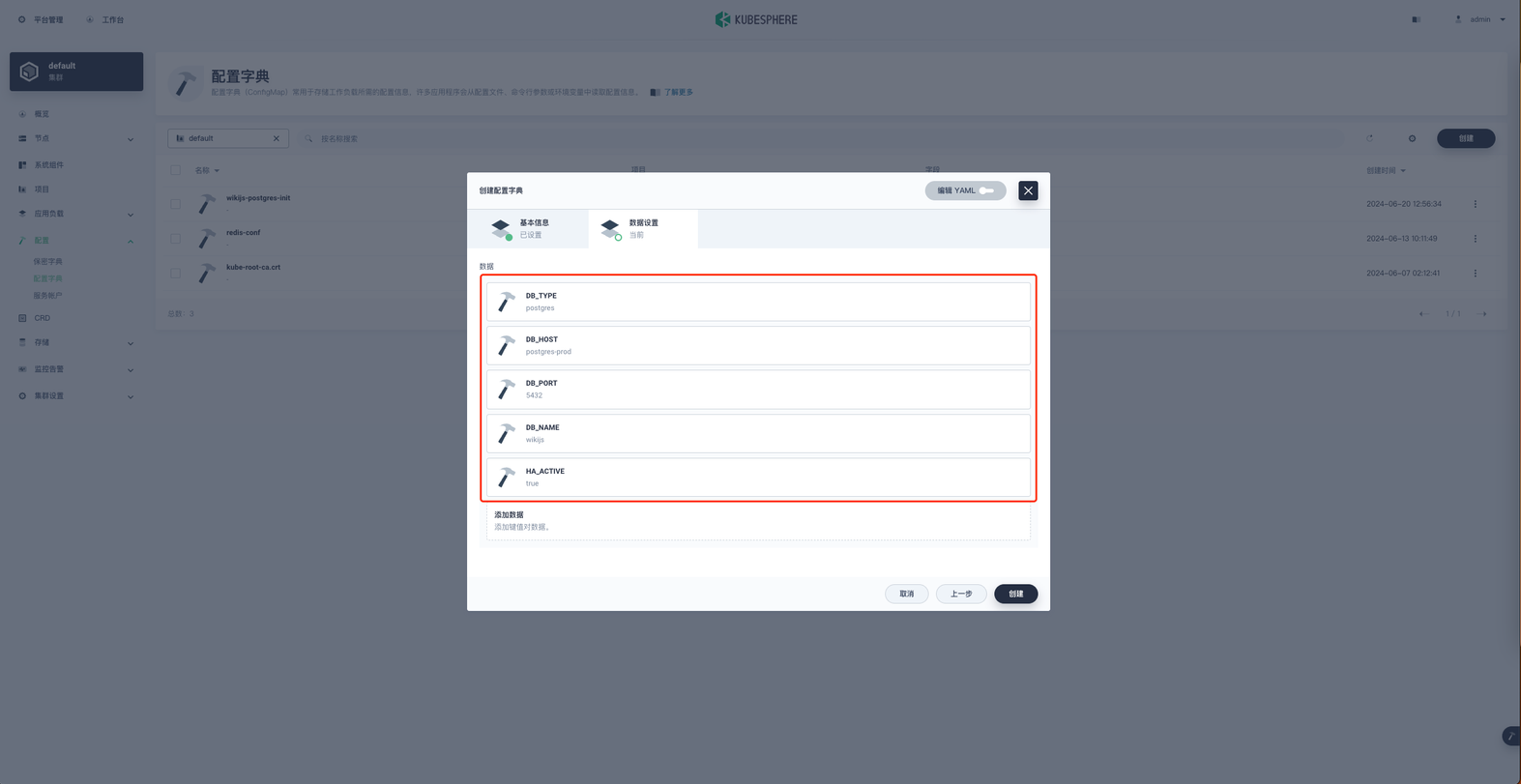
键值对数据如下
1DB_TYPE: postgres
2 DB_HOST: postgres-prod
3DB_PORT: 5432
4 DB_NAME: wikijs创建数据库用户和数据库
如果 PostgreSQL 数据库里没有创建 wikijs 用户和数据 ,需要手工完成一下工作:
通过『数据库工具』连接 PostgreSQL 数据库,执行一下 SQL 语句,完成数据库和用户的创建、授权。
以上 wikijs 的密码自行修改。
部署 wiki.js
这里我们采用 Deployment 方式部署 wiki.js。
在项目空间的 应用负载 → 工作负载 → 部署 → 创建 进行 wiki.js 服务的创建。
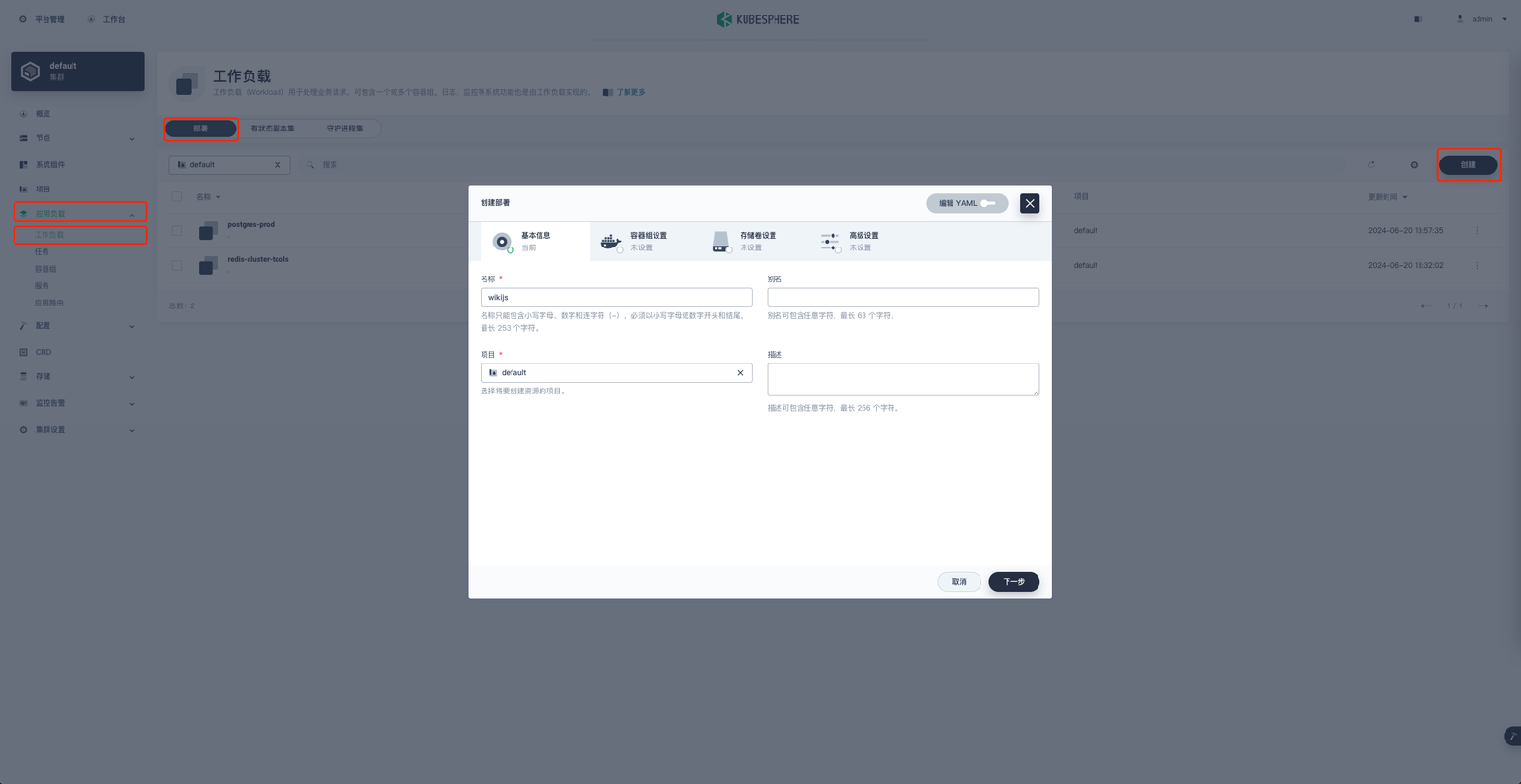
基本信息里名称就叫做 wikijs ,然后进行下一步容器组设置
容器组配置
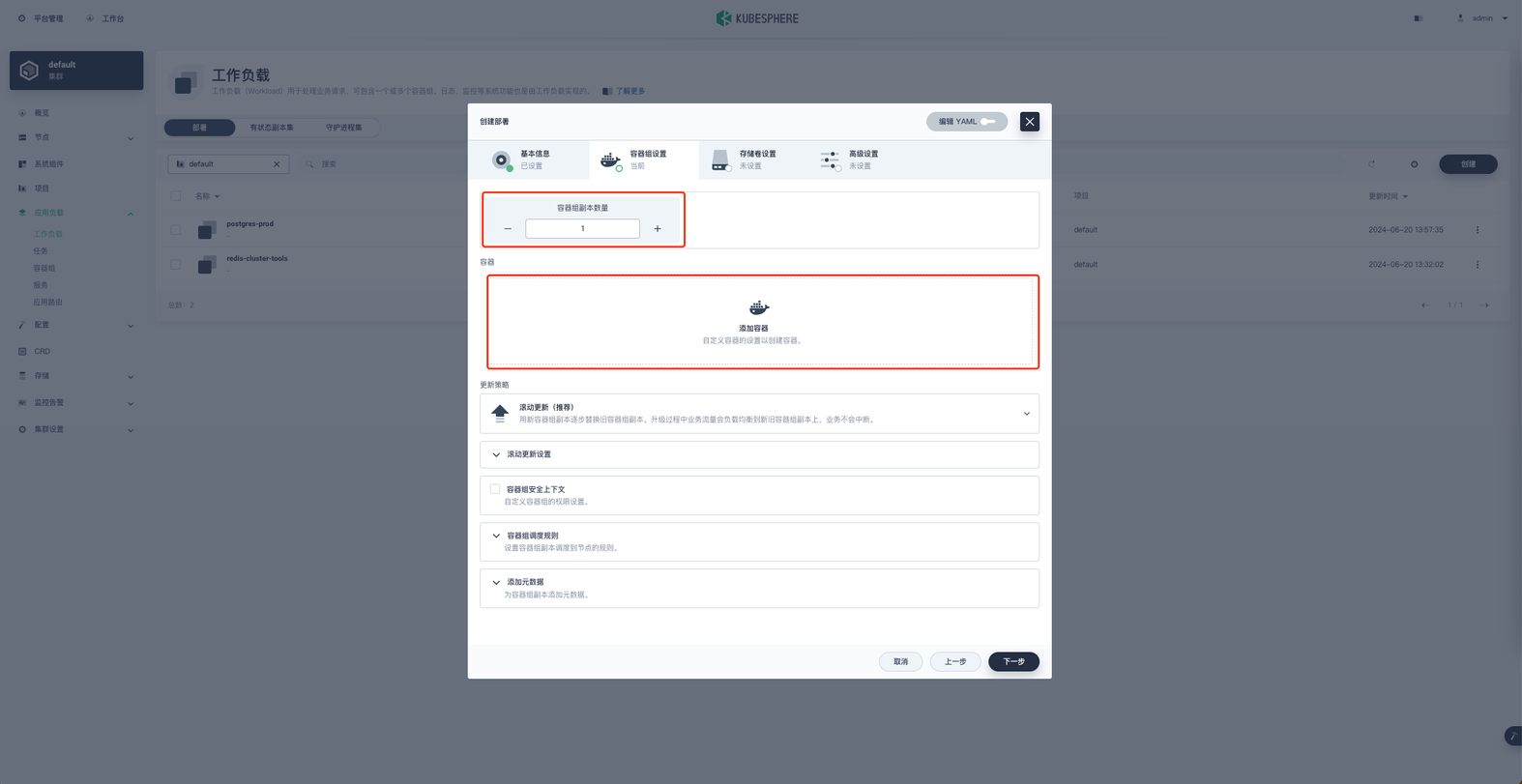
这一步的核心就是配置 wikijs 的容器。
容器组副本数量选择1,点击添加容器
5 HA_ACTIVE: true
1 CREATE DATABASE wikijs;
2 CREATE USER wikijs with password 'password';
3 GRANT CONNECT ON DATABASE wikijs to wikijs;
4 GRANT USAGE ON SCHEMA public TO wikijs;
5 GRANT SELECT,update,INSERT,delete ON ALL TABLES IN SCHEMA public TO wikijs;
6 ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO wikijs;镜像选择 dockerhub 中的 requarks/wiki:2 ,并选择使用默认端口,容器名称改为 wikijs
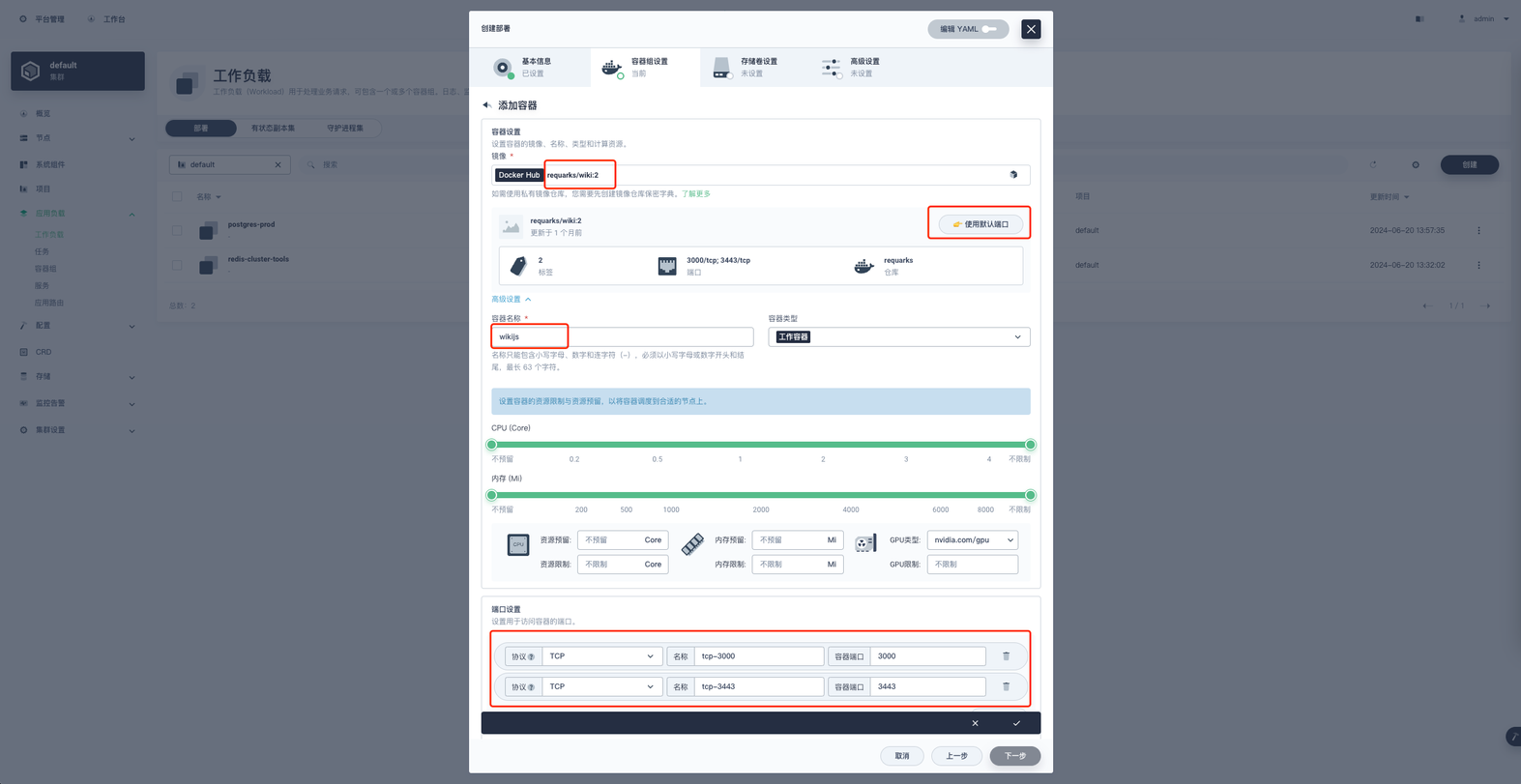
勾选 环境变量 ,点击 引用配置字典或保密字典 ,先添加刚才创建的保密字典 wikijs ,然后添加配置字典 wikijs ,之后点击对勾完成容器配置,点击下一步配置
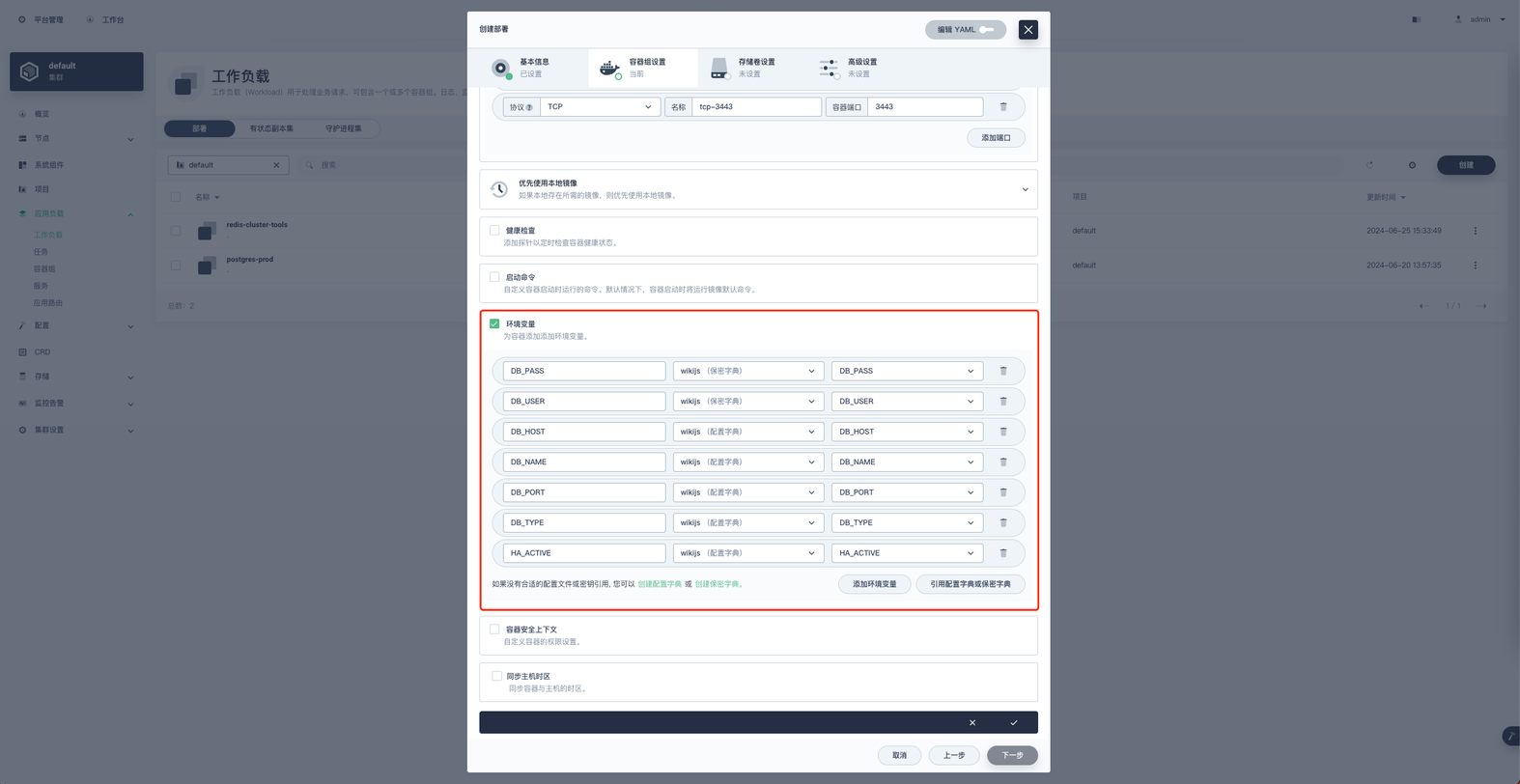
存储卷设置存储卷此处无需设置,点击下一步进入高级配置
高级设置 里是一些额外配置,可以根据自己场景选择调整配置,调整完成后点击 创建 。
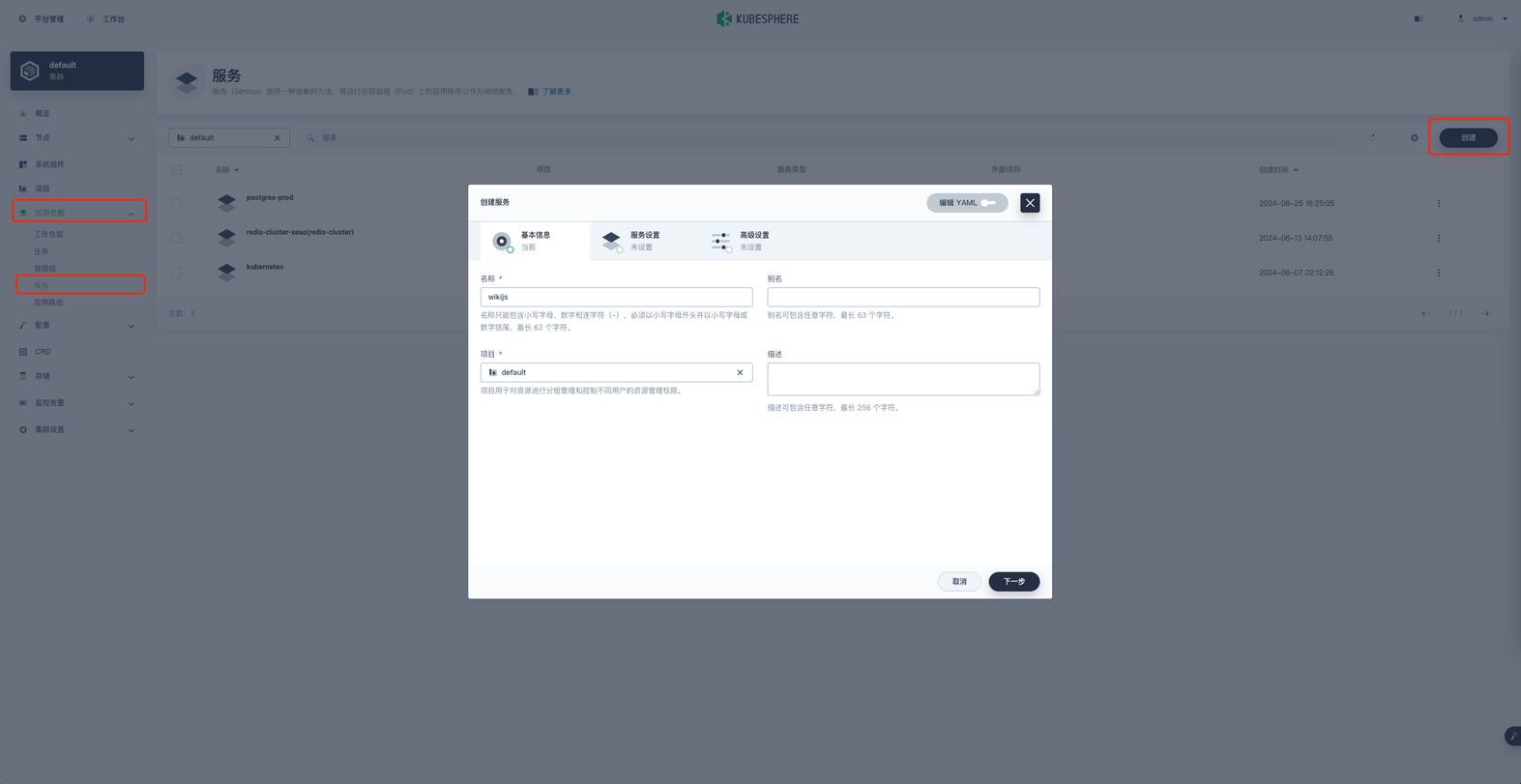
创建访问 wiki.js 的 Service
在项目空间的 应用负载 → 服务 → 创建 进行服务的创建名称就叫 wikijs 然后下一步,进入服务设置
内部访问模式选择 虚拟IP地址 ,指定工作负载选择 wikijs
端口协议:TCP
端口名称:tcp-3000
容器端口:3000
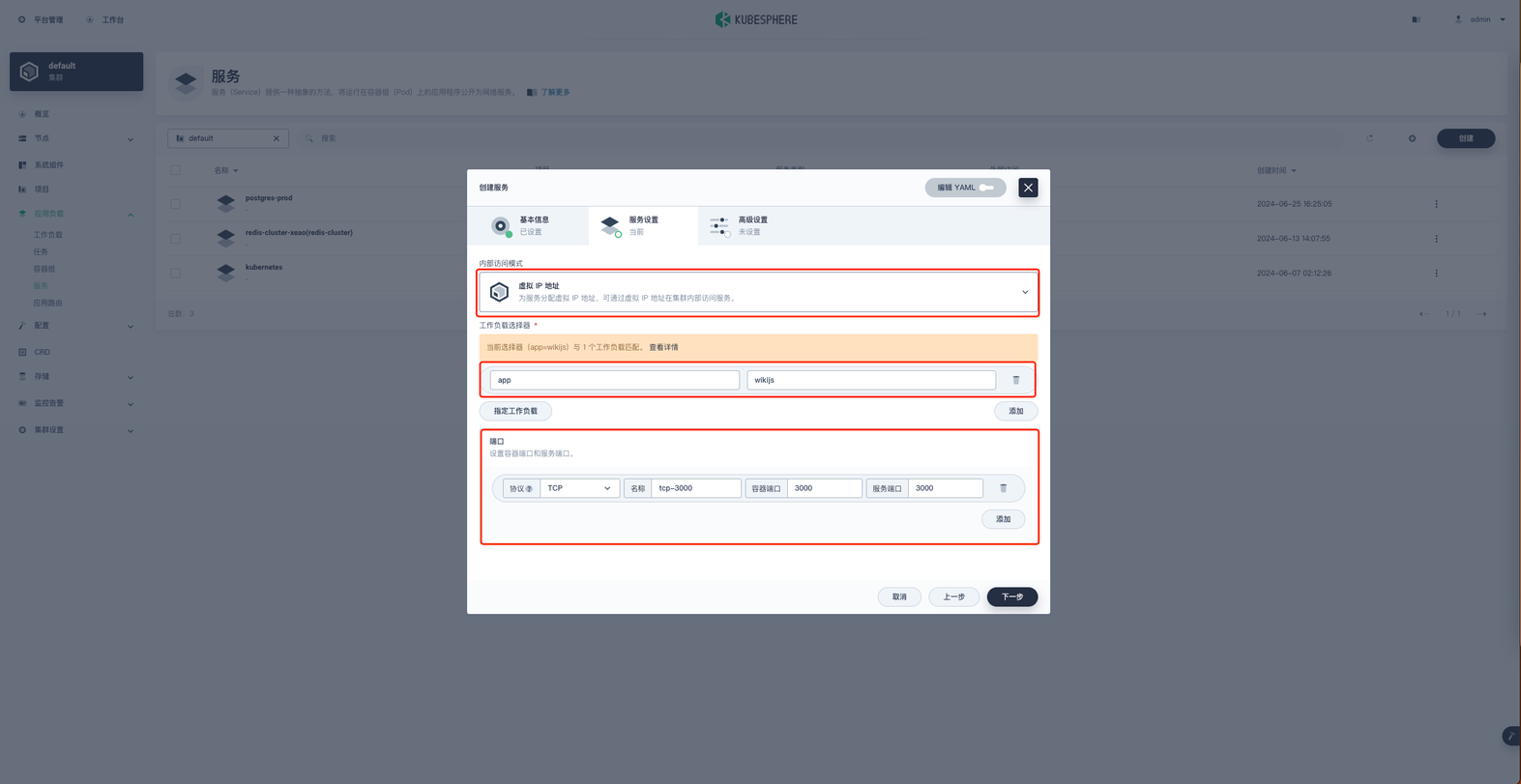
服务端口:3000点击下一步进入高级设置,勾选外部访问,访问模式选择NodePort,完成后点击 创建 。
然后可以使用NodePort的IP + Port进行访问wikijs。
配置 wiki.js 支持中文全文检索
wiki.js 的全文检索支持基于 PostgreSQL 的检索,也支持 Elasticsearch 等,相对来说, PostgreSQL 比较轻量级,本项目中,我们使用
PostgreSQL 的全文检索。
但是,因为 PostgreSQL 不支持中文分词,需要额外安装插件并配置启用中文分词,下面描述了为 wiki.js 启动基于 PostgreSQL 数据库中文
分词的全文检索。
授予 wikijs 用户临时超管权限
通过数据库管理工具登录有超管权限的 PostgreSQL 用户,临时授予 wiki.js 用户临时超管权限,便于启动中文分词功能。
启用数据库的中文分词能力
使用数据库管理工具登录 PostgreSQL 数据库的 wikijs 用户,执行以下命令,启动数据库的中文分词功能。
1 ALTER USER wikijs WITH SUPERUSER;
1 CREATE EXTENSION pg_trgm;
2
3 CREATE EXTENSION zhparser;
4 CREATE TEXT SEARCH CONFIGURATION pg_catalog.chinese_zh (PARSER = zhparser);
5 ALTER TEXT SEARCH CONFIGURATION chinese_zh ADD MAPPING FOR n,v,a,i,e,l WITH simple;
6
7 -- 忽略标点影响
8 ALTER ROLE wikijs SET zhparser.punctuation_ignore = ON;
9
-- 短词复合取消 wikijs 用户的临时超管权限
登录 PostgreSQL 数据库 wikijs 用户,取消 wikijs 用户的超管权限。
创建支持中文分词的配置 ConfigMap
在项目空间的 配置 → 配置字典 → 创建 进行配置字典的创建。
名称就叫 wikijs-zhparser 然后下一步,添加两个键值对数据。
10 ALTER ROLE wikijs SET zhparser.multi_short = ON;
11
12-- 测试一下
13select ts_debug('chinese_zh', '青春是最美好的年岁,青春是最灿烂的日子。每一个人的青春都无比宝贵,宝贵的青春只有与奋斗为伴才最闪光
取消 wikijs 用户的临时超管权限
登录 PostgreSQL 数据库 wikijs 用户,取消 wikijs 用户的超管权限。
1 ALTER USER wikijs WITH NOSUPERUSER;
创建支持中文分词的配置 ConfigMap
在项目空间的 配置 → 配置字典 → 创建 进行配置字典的创建。
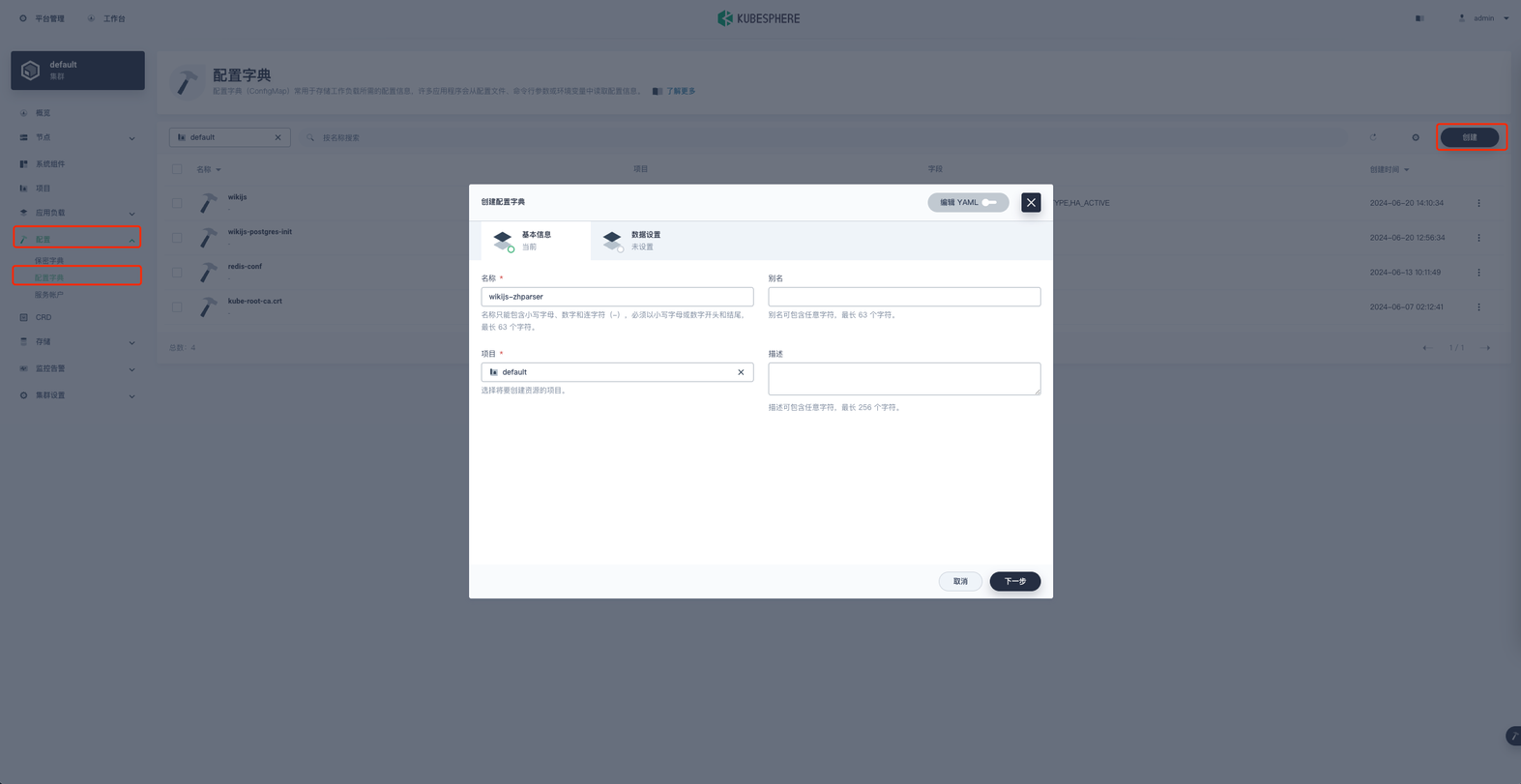
名称就叫 wikijs-zhparser 然后下一步,添加两个键值对数据。
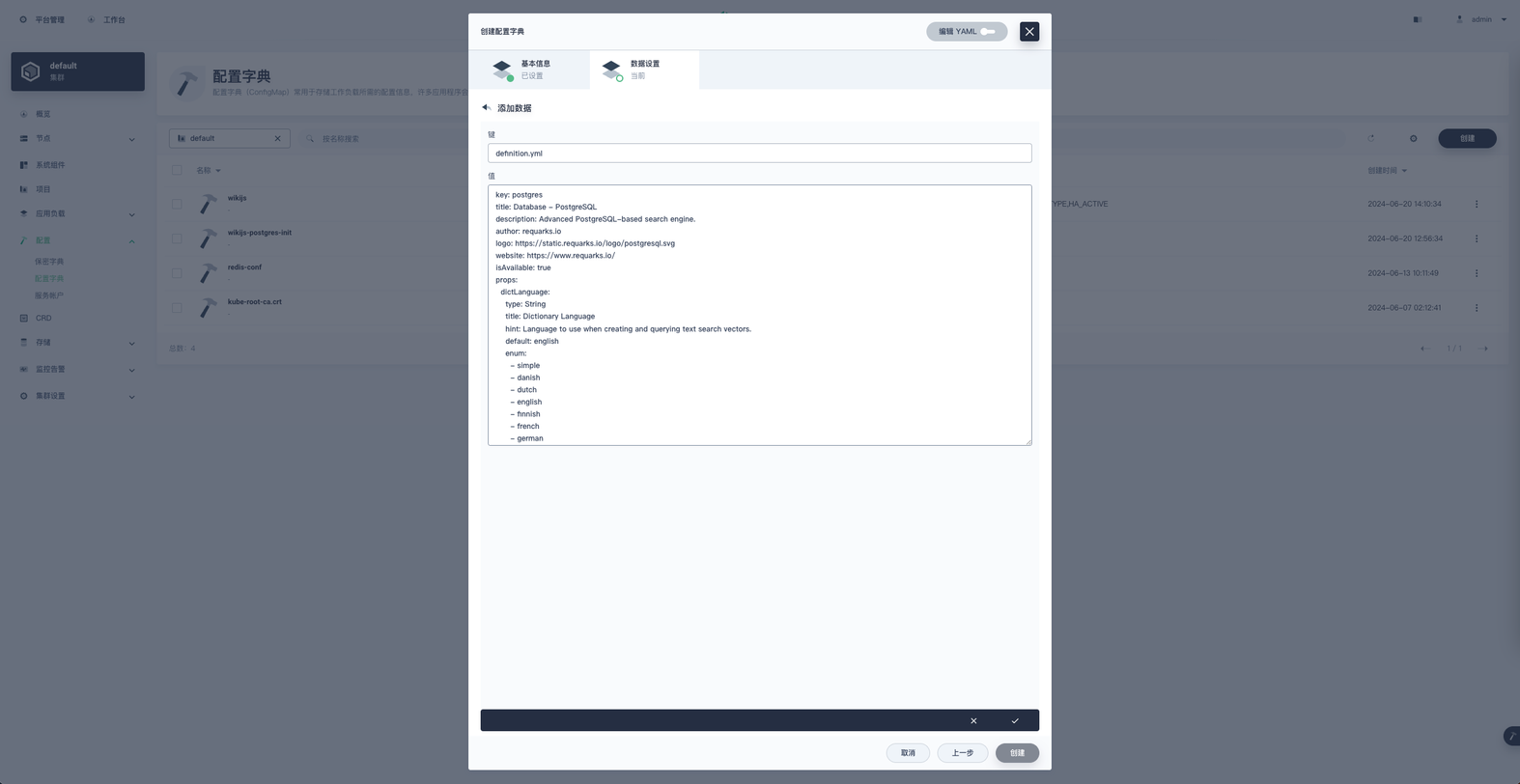
1. 键为 definition.yml ,值为
1 key: postgres
2 title: Database - PostgreSQL
3 description: Advanced PostgreSQL-based search engine.
4 author: requarks.io
5 logo: https://static.requarks.io/logo/postgresql.svg
6 website: https://www.requarks.io/
7 isAvailable: true
8 props:
9dictLanguage:
10type: String
11title: Dictionary Language
12hint: Language to use when creating and querying text search vectors.2. 键为 engine.js ,值为
13default: english
14enum:
15- simple
16- danish
17- dutch
18- english
19- finnish
20- french
21- german
22- hungarian
23- italian
24- norwegian
25- portuguese
26- romanian
27- russian
28- spanish
29- swedish
30- turkish
31- chinese_zh
32order: 1
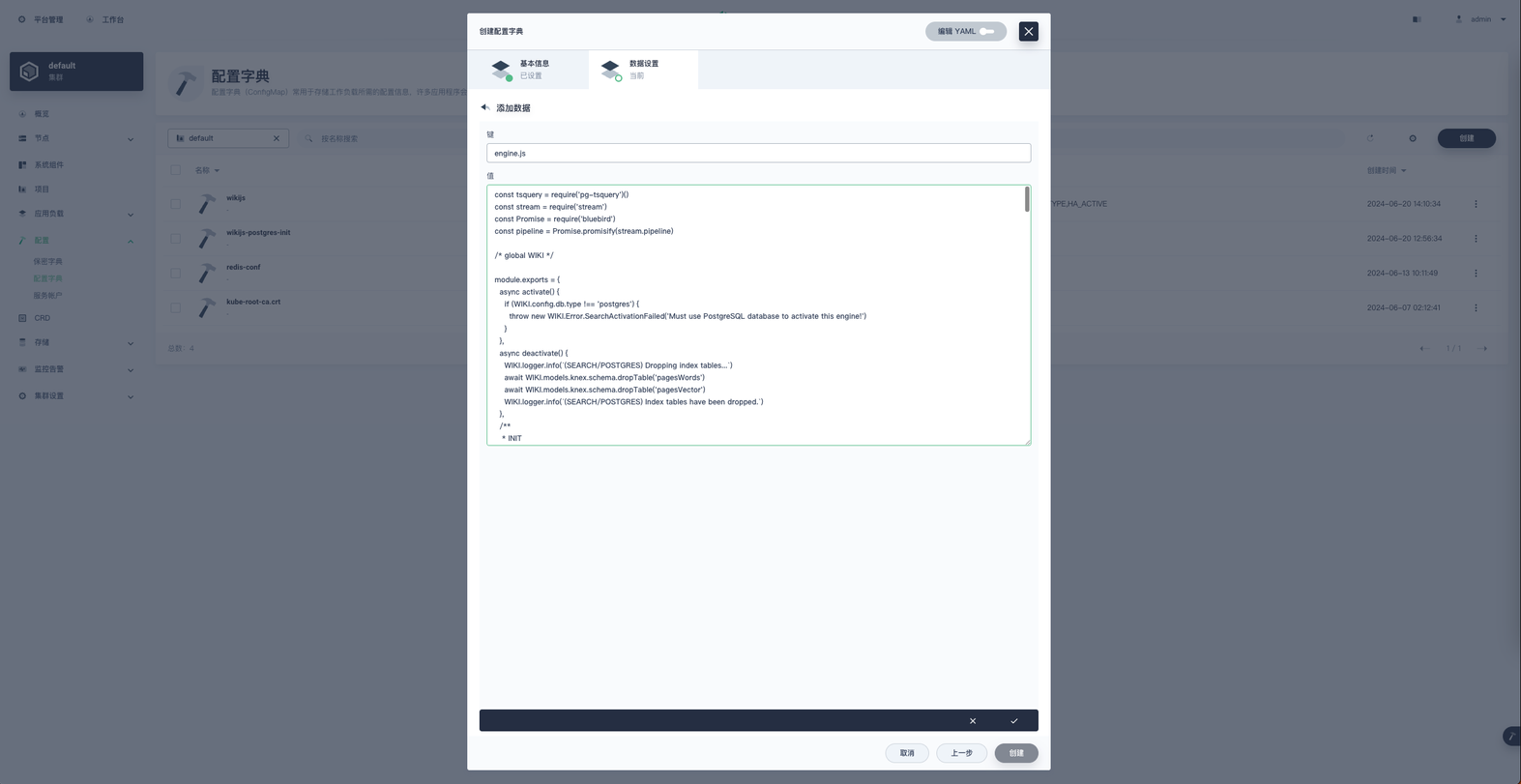
2. 键为 engine.js ,值为
1 const tsquery = require('pg-tsquery')()
2 const stream = require('stream')
3 const Promise = require('bluebird')
4 const pipeline = Promise.promisify(stream.pipeline)
5
6 /* global WIKI */
7
8 module.exports = {
9async activate() {
10if (WIKI.config.db.type !== 'postgres') {
11throw new WIKI.Error.SearchActivationFailed('Must use PostgreSQL database to activate this engine!')
12}
13},
14async deactivate() {
15WIKI.logger.info(`(SEARCH/POSTGRES) Dropping index tables...`)
16await WIKI.models.knex.schema.dropTable('pagesWords')
17await WIKI.models.knex.schema.dropTable('pagesVector')
18WIKI.logger.info(`(SEARCH/POSTGRES) Index tables have been dropped.`)
19},
20/**
21* INIT
22*/
23async init() {
24WIKI.logger.info(`(SEARCH/POSTGRES) Initializing...`)
25
26// -> Create Search Index
27const indexExists = await WIKI.models.knex.schema.hasTable('pagesVector')
28if (!indexExists) {
29WIKI.logger.info(`(SEARCH/POSTGRES) Creating Pages Vector table...`)
30await WIKI.models.knex.schema.createTable('pagesVector', table => {
31table.increments()
32table.string('path')
33table.string('locale')
34table.string('title')
35table.string('description')
36table.specificType('tokens', 'TSVECTOR')
37table.text('content')
38})
39}
40// -> Create Words Index
41const wordsExists = await WIKI.models.knex.schema.hasTable('pagesWords')
42if (!wordsExists) {
43WIKI.logger.info(`(SEARCH/POSTGRES) Creating Words Suggestion Index...`)
44await WIKI.models.knex.raw(`
45CREATE TABLE "pagesWords" AS SELECT word FROM ts_stat(
46'SELECT to_tsvector(''simple'', "title") || to_tsvector(''simple'', "description") || to_tsvector(''s
47)`)
48await WIKI.models.knex.raw('CREATE EXTENSION IF NOT EXISTS pg_trgm')
49await WIKI.models.knex.raw(`CREATE INDEX "pageWords_idx" ON "pagesWords" USING GIN (word gin_trgm_ops)`)
50}
51
52WIKI.logger.info(`(SEARCH/POSTGRES) Initialization completed.`)
53},
54/**
55* QUERY
56*
57* @param {String} q Query
58* @param {Object} opts Additional options
59*/
60async query(q, opts) {
61try {
62let suggestions = []
63let qry = `
64SELECT id, path, locale, title, description
65FROM "pagesVector", to_tsquery(?,?) query
66WHERE (query @@ "tokens" OR path ILIKE ?)
67`
68let qryEnd = `ORDER BY ts_rank(tokens, query) DESC`
69let qryParams = [this.config.dictLanguage, tsquery(q), `%${q.toLowerCase()}%`]
70
71if (opts.locale) {
72qry = `${qry} AND locale = ?`
73qryParams.push(opts.locale)
74}
75if (opts.path) {
76qry = `${qry} AND path ILIKE ?`
77qryParams.push(`%${opts.path}`)
78}
79const results = await WIKI.models.knex.raw(`
80${qry}
81${qryEnd}
82`, qryParams)
83if (results.rows.length < 5) {
84const suggestResults = await WIKI.models.knex.raw(`SELECT word, word <-> ? AS rank FROM "pagesWords" WH
85suggestions = suggestResults.rows.map(r => r.word)
86}
87return {
88results: results.rows,
89suggestions,
90totalHits: results.rows.length
91}
92} catch (err) {
93WIKI.logger.warn('Search Engine Error:')
94WIKI.logger.warn(err)
95}
96},
97/**
98* CREATE
99*
100* @param {Object} page Page to create
101*/
102async created(page) {
103await WIKI.models.knex.raw(`
104INSERT INTO "pagesVector" (path, locale, title, description, "tokens") VALUES (
105?, ?, ?, ?, (setweight(to_tsvector('${this.config.dictLanguage}', ?), 'A') || setweight(to_tsvector('${
106)
107`, [page.path, page.localeCode, page.title, page.description, page.title, page.description, page.safeConten
108},
109/**
110* UPDATE
111*
112* @param {Object} page Page to update
113*/
114async updated(page) {
115await WIKI.models.knex.raw(`
116UPDATE "pagesVector" SET
117title = ?,
118description = ?,
119tokens = (setweight(to_tsvector('${this.config.dictLanguage}', ?), 'A') ||
120setweight(to_tsvector('${this.config.dictLanguage}', ?), 'B') ||
121setweight(to_tsvector('${this.config.dictLanguage}', ?), 'C'))
122WHERE path = ? AND locale = ?
123`, [page.title, page.description, page.title, page.description, page.safeContent, page.path, page.localeCod
124},
125/**
126* DELETE
127*
128* @param {Object} page Page to delete
129*/
130async deleted(page) {
131await WIKI.models.knex('pagesVector').where({
132locale: page.localeCode,
133path: page.path
134}).del().limit(1)
135},
136/**
137* RENAME
138*
139* @param {Object} page Page to rename
140*/
141async renamed(page) {
142await WIKI.models.knex('pagesVector').where({
143locale: page.localeCode,
144path: page.path
145}).update({
146locale: page.destinationLocaleCode,
147path: page.destinationPath
148})
149},
150/**
151* REBUILD INDEX
152
*/更新 wikijs 的 Deployment
wiki.js 的基于 PostgreSQL 的全文检索引擎配置位于 /wiki/server/modules/search/postgres ,我们将前面配置的 ConfigMap 加载到这个目录。
在项目空间的 应用负载 → 工作负载 → wikijs 进入 wikijs 工作负载的详情页
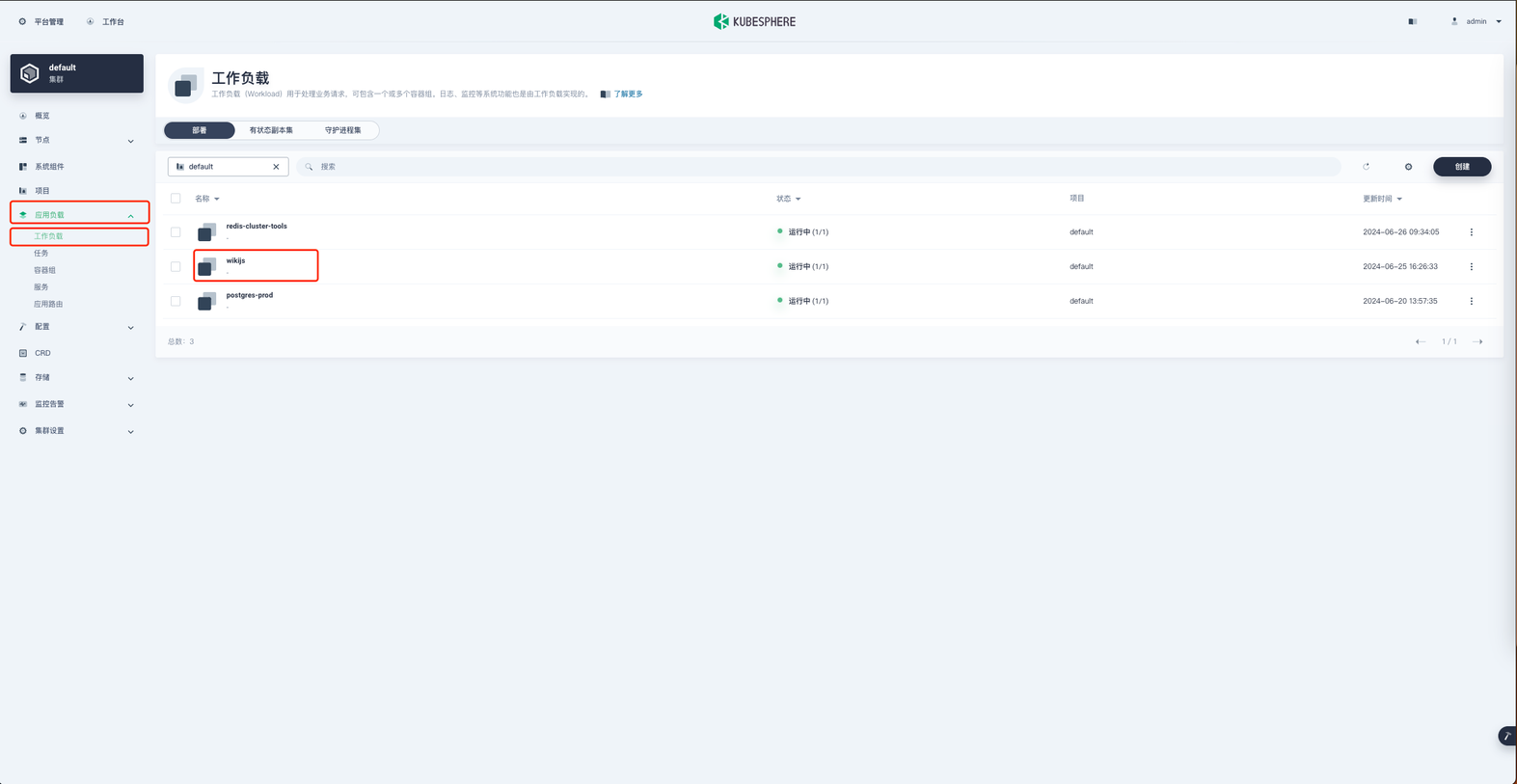
点击左侧更多操作,选择编辑设置
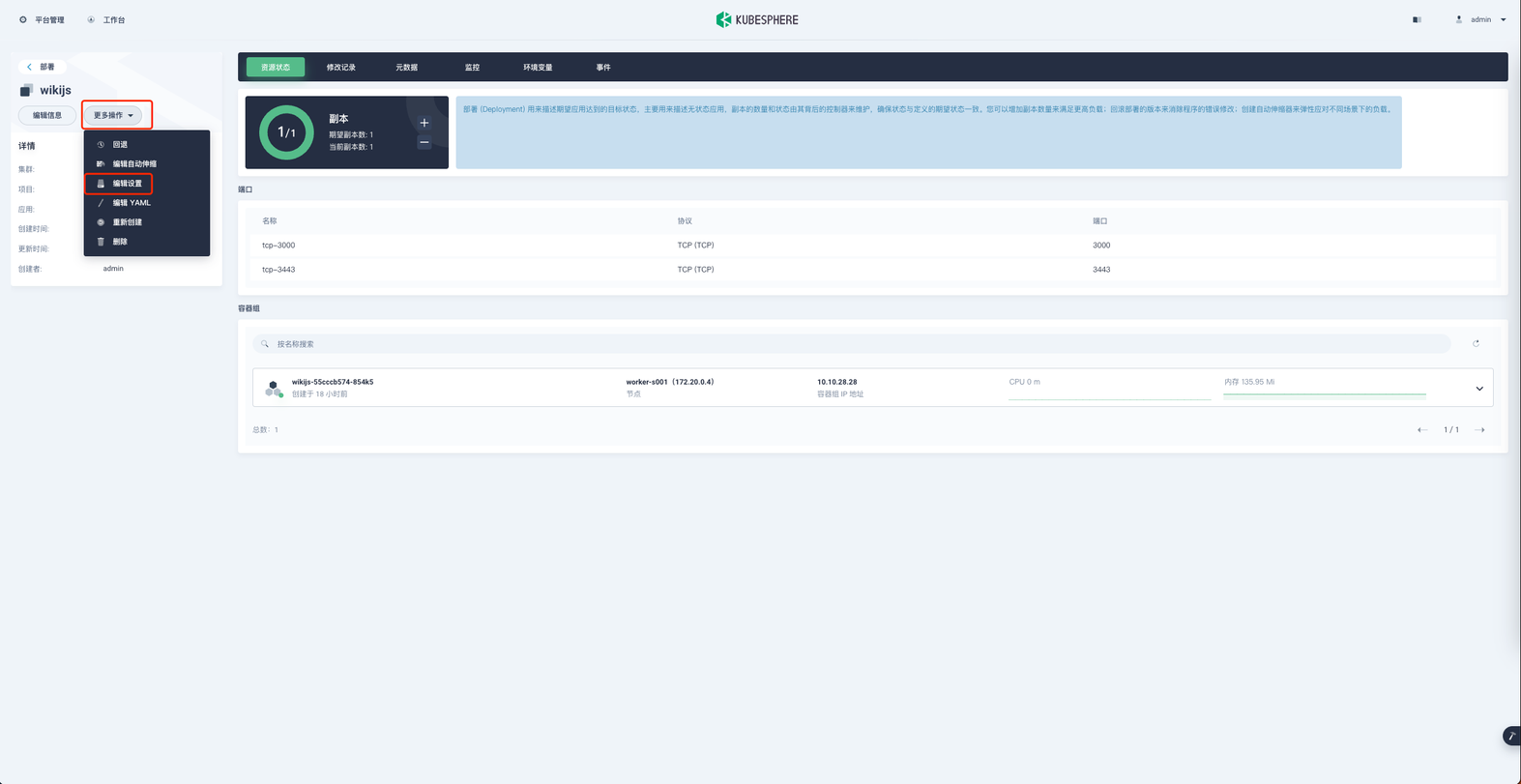
点击 存储卷 → 挂载配置字典或保密字典
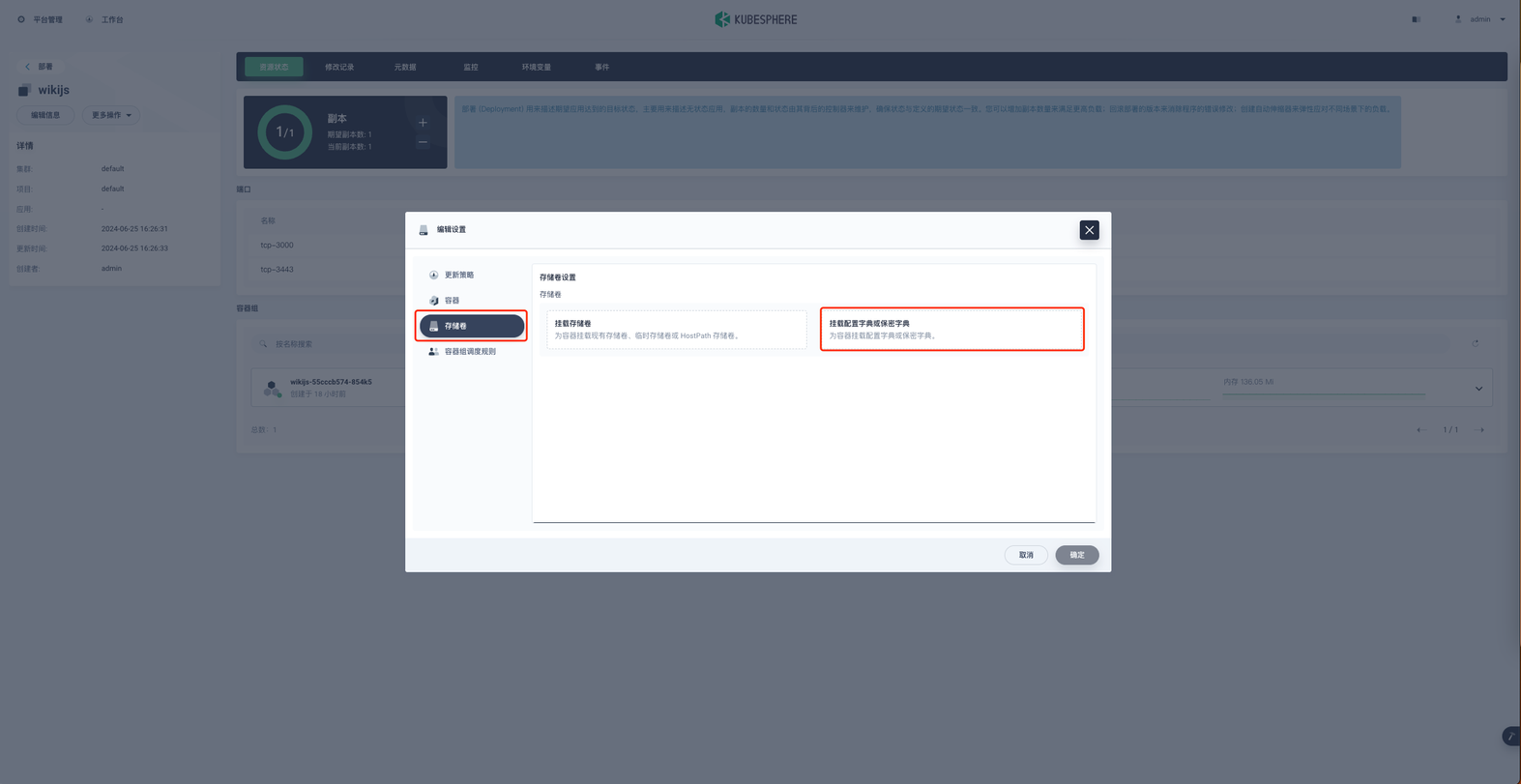
选择配置字典 wikijs-zhparser ,权限为只读,挂载地址为 /wiki/server/modules/search/postgres ,配置好后点击对勾完成配置
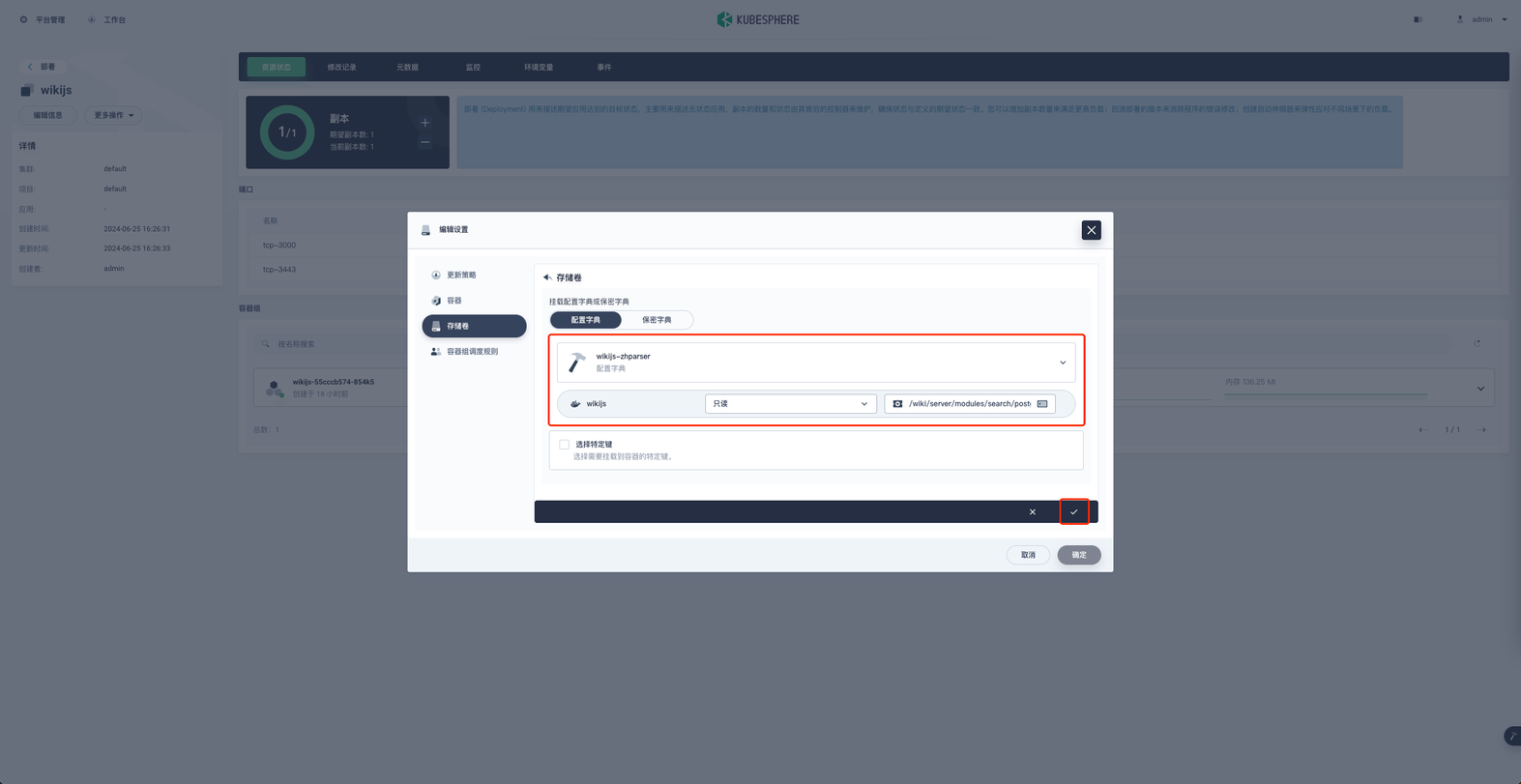
点击确定完成存储卷的修改
配置 wiki.js ,启用基于 PostgreSQL 的全文检索
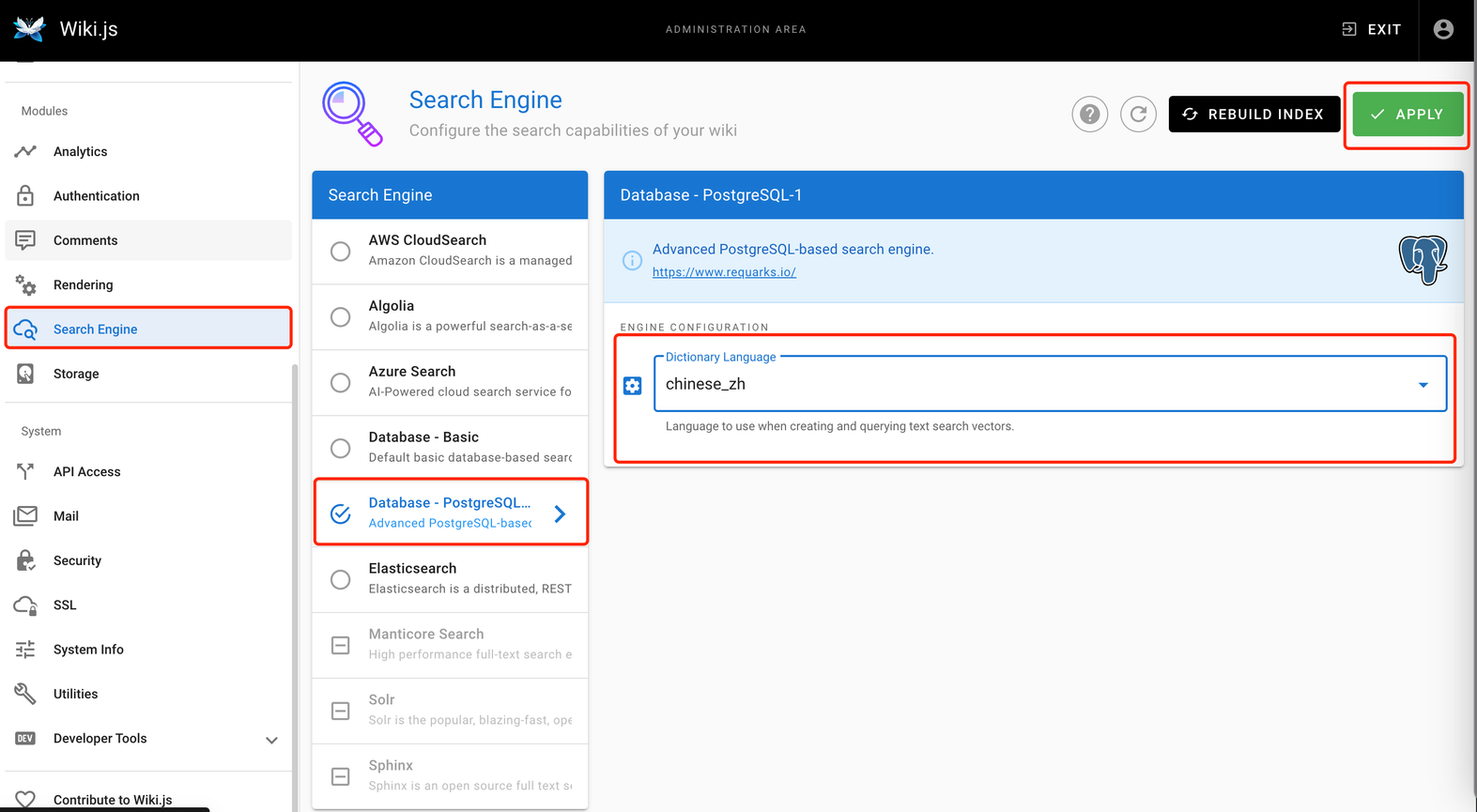
1. 新的 Deployment 创建完成后
2. 打开 wiki.js 管理3. 点击搜索引擎
4. 选择 Database - PostgreSQL
5. 在 Dictionary Language 的下拉菜单里选择 chinese_zh。
6. 点击应用,并重建索引。
7. 完成配置。
总结
“K8S学习教程(三):在PetaExpress KubeSphere 容器部署 Wiki 系统 wiki.js 并启用中文全文检索”重点讲解了wiki.js的部署方式,特别强调了其
对中文全文检索功能的支持。集成了 PostgreSQL 和 zhparser 中文分词插件。
相对于标准的 wiki.js 安装部署过程,主要做了以下配置:
1、wiki.js 镜像外挂了 ConfigMap ,用于修改原 Docker 镜像里关于 PostgreSQL 搜索引擎配置的信息,以支持 chinese_zh 选项。
2、PostgreSQL 镜像采用了 abcfy2/zhparser:12-alpine ,这个镜像自带 zhparser 中文分词插件。
凭此文章可以去petaexpress官网发工单 充值≥1美元送10美元,奖励数量有限先到先得。申领步骤:注册→登录→充值→发工单 回复“文章 网址+文章标题+申请奖励”,
审核编辑 黄宇
-
开源
+关注
关注
3文章
3471浏览量
42936 -
Wiki
+关注
关注
0文章
5浏览量
8854
发布评论请先 登录
相关推荐
搭建k8s需要买几台云主机?
在华为云 X 实例上安装部署企业 Wiki 知识分享平台的实践

k8s和docker区别对比,哪个更强?
k8s微服务架构就是云原生吗?两者是什么关系
混合云部署k8s集群方法有哪些?
k8s可以部署私有云吗?私有云部署全攻略
k8s云原生开发要求

k8s容器启动失败的常见原因及解决办法
云服务器部署k8s需要什么配置?
纳尼?自建K8s集群日志收集还能通过JMQ保存到JES
常用的k8s容器网络模式有哪些?
如何使用Kubeadm命令在PetaExpress Ubuntu系统上安装Kubernetes集群
K8S学习教程(二):在 PetaExpress KubeSphere容器平台部署高可用 Redis 集群
K8S学习教程一:使用PetaExpress云服务器安装Minikube 集群






 工商网监
工商网监
评论