 计算机视觉怎么给图像分类
计算机视觉怎么给图像分类

图像分类是计算机视觉领域中的一项核心任务,其目标是将输入的图像自动分配到预定义的类别集合中。这一过程涉及图像的特征提取、特征表示以及分类器的设计与训练。随着深度学习技术的飞速发展,图像分类的精度和效率得到了显著提升。本文将从图像分类的基本概念、流程、常用算法以及未来发展趋势等方面进行详细阐述。
一、图像分类的基本概念
图像分类是指利用计算机视觉技术,将输入的图像根据其内容自动分配到预定义的类别中的过程。在计算机视觉中,图像通常是以像素矩阵的形式表示,每个像素包含颜色、亮度等信息。图像分类的任务就是通过对这些像素的处理和分析,最终输出一个类别标签。
二、图像分类的流程
图像分类的流程主要包括数据准备、特征提取、特征表示、分类器训练与评估等步骤。
1. 数据准备
数据准备是图像分类的第一步,也是至关重要的一步。它包括收集并准备用于训练和测试的图像数据集。数据集通常被划分为训练集、验证集和测试集,分别用于模型的训练、参数调整和性能评估。在准备数据集时,需要对图像进行标注,即给每张图像分配一个或多个类别标签。
2. 特征提取
特征提取是将原始图像转化为可用于分类的特征向量的过程。在传统的计算机视觉方法中,特征提取通常依赖于手工设计的特征描述子,如SIFT(尺度不变特征变换)、HOG(方向梯度直方图)等。然而,这些方法在处理复杂图像时往往效果不佳。近年来,随着深度学习技术的兴起,自动特征提取成为主流。卷积神经网络(CNN)是图像分类领域最常用的深度学习模型之一,它能够自动从图像中学习并提取出具有代表性的特征。
3. 特征表示
特征表示是将提取出来的特征向量转化为一个可用于分类的固定维度的向量的过程。在传统的机器学习方法中,特征表示通常涉及特征选择、降维等操作。而在深度学习中,特征表示是通过卷积神经网络中的卷积层、池化层等自动完成的。这些层能够逐步将图像的特征从低级(如边缘、纹理)抽象到高级(如形状、对象),最终形成可用于分类的特征表示。
4. 分类器训练与评估
分类器训练是将转化后的特征向量输入到分类器中,通过学习预定义类别的样本来进行分类的过程。常用的分类器包括支持向量机(SVM)、K近邻(KNN)、决策树、随机森林等。然而,在深度学习领域,卷积神经网络本身就可以作为一个强大的分类器。通过反向传播算法和梯度下降等优化方法,可以不断调整网络参数以最小化损失函数,从而提高分类的准确率。
模型评估是检验分类器性能的重要环节。通常使用验证集对训练得到的分类器进行评估,并根据评估结果调整模型参数。最后,使用测试集对训练好的分类器进行测试评估,计算模型的准确率、精度、召回率等指标以衡量其性能。
三、常用算法与模型
1. 卷积神经网络(CNN)
卷积神经网络是图像分类领域最常用的深度学习模型之一。它由卷积层、池化层、全连接层等组成,能够自动地从图像中学习并提取出具有代表性的特征。CNN通过卷积操作实现局部感受野和权值共享,大大降低了模型的复杂度并提高了计算效率。同时,通过池化操作实现特征降维和平移不变性,进一步提高了模型的鲁棒性。
2. 经典CNN模型
- LeNet :最早的卷积神经网络之一,由Yann LeCun等人于1998年提出,主要用于手写数字的识别任务。
- AlexNet :由Alex Krizhevsky等人于2012年在ImageNet图像分类竞赛中获得了第一名,是一个具有深度结构的卷积神经网络。
- VGGNet :由Karen Simonyan和Andrew Zisserman提出,通过多个3x3的卷积层和池化层进行特征提取,并使用全连接层进行分类。
- GoogLeNet :由Google研究团队提出,创新性地使用了Inception模块,提高了模型的表示能力。
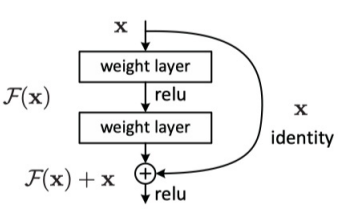
- ResNet :由Microsoft Research Asia提出,通过引入残差连接解决了深度神经网络训练中的梯度消失或梯度爆炸问题,使得网络可以更加深入地学习图像特征。
3. 其他算法与模型
除了卷积神经网络外,还有一些其他算法和模型也被应用于图像分类任务中。例如,支持向量机(SVM)是一种基于最大间隔原则的分类算法,在图像分类中表现出色。此外,还有一些基于图像分割、目标检测等技术的图像分类方法,它们能够在更细粒度的层面上对图像进行分类。
四、当前状况及未来趋势趋势
计算机视觉(Computer Vision,CV)作为人工智能领域的一个重要分支,近年来取得了显著的发展。以下是对计算机视觉领域当前状况及未来趋势的详细分析:
1.当前状况
- 技术创新与突破
- 分割技术 :如Meta AI开发的Segment Anything Model(SAM),几乎可以分割图像中的任何事物,为跨各种数据集的复杂分割任务开辟了新途径。
- 多模态大型语言模型 :如GPT-4等模型,弥合了文本和视觉数据之间的差距,使AI能够理解和解释复杂的多模态输入。
- 物体检测 :YOLOv8等模型凭借其增强的速度和准确性,为物体检测树立了新标准。YOLO系列的最新版本如YOLOv10,进一步提高了性能和效率。
- 自监督学习 :DINOv2等模型展示了自监督方法使用较少的标记图像训练高质量模型的潜力。
- 文本转图像和视频 :Midjourney creations、DALL-E 3、Stable Diffusion XL、Imagen 2等模型,以及Runway、Pika Labs和Emu Video等T2V模型,极大地提高了AI根据文本描述生成图像和视频的质量和真实感。
- 应用领域的扩展
- 自动驾驶 :计算机视觉在自动驾驶领域的应用日益成熟,通过识别道路标志、车辆和行人等,提高行驶安全。
- 医学影像 :在医疗领域,计算机视觉用于分析X射线、MRI等医学图像,帮助医生更准确地诊断疾病。
- 安全监控 :通过实时视频分析,检测异常行为、入侵者和其他安全威胁,提高公共安全水平。
- 娱乐和社交媒体 :图像分析技术用于内容推荐、用户交互和增强现实(AR)体验,如面部识别技术用于创建有趣的滤镜和效果。
- 技术挑战
- 数据隐私 :随着图像数据的大量收集和分析,如何保护个人隐私成为一个重要问题。
- 算法偏见 :机器学习模型可能会学习到训练数据中的偏见,导致不公平的结果。
- 模型可解释性 :深度学习模型通常被认为是“黑箱”,提高模型的可解释性是一个挑战。
2.未来趋势
- 动态实时数据分析
- 未来的计算机视觉技术将更加注重动态实时数据的分析,优化动态数据追踪及检测的相关算法,以满足实时应用的需求。
- 多场景融合应用
- 在应用领域方面,多场景融合应用将是重要的发展方向。计算机视觉将不仅局限于单一领域的应用,而是会与其他领域进行深度融合,如社会科学、人体健康等。
- 构建多维数据集
- 视觉数据方面,需要构建多维、全面、立体的数据集。结合物联技术、遥感技术、AI技术的成熟,将跨时空、跨地域、跨物种的视觉数据进行综合叠加,构建全周期、全过程视觉数据集。
- 视觉生成与内容理解统一建模
- 通过自监督、多模态预训练产生的基础大模型,可以指导产生更加可控、有意义的图像、视频生成。反过来,生成模型的建模方式也越来越多地成为解决复杂视觉理解任务的新思路。
- 边缘计算
- 边缘计算将变得更加普遍。在设备上处理视觉数据将提高数据处理的速度和效率,适用于自动驾驶、智能安全系统等对实时性要求高的应用。
- 道德与隐私保护
- 随着计算机视觉的广泛应用,道德和隐私问题将越来越受到关注。开发更加平衡、更加注重隐私的技术将是未来的重要趋势。
综上所述,计算机视觉领域正处于快速发展阶段,技术创新不断涌现,应用领域持续扩展。然而,也面临着数据隐私、算法偏见和模型可解释性等挑战。未来,随着技术的不断进步和应用领域的不断扩展,计算机视觉将在更多领域发挥重要作用,并推动人工智能技术的进一步发展。
-
图像分类
+关注
关注
0文章
97浏览量
12531 -
计算机视觉
+关注
关注
9文章
1715浏览量
47722 -
深度学习
+关注
关注
73文章
5608浏览量
124634
发布评论请先 登录
深度解析计算机视觉的图像分割技术

机器视觉与计算机视觉的关系简述

基于计算机视觉的多维图像智能
如何快速学习计算机视觉图像的分类



评论