 深度神经网络中的前馈过程
深度神经网络中的前馈过程
深度神经网络(Deep Neural Networks,DNNs)中的前馈过程是其核心操作之一,它描述了数据从输入层通过隐藏层最终到达输出层的过程,期间不涉及任何反向传播或权重调整。这一过程是神经网络进行预测或分类任务的基础。
一、引言
深度神经网络作为深度学习领域的基石,通过多层非线性变换来捕捉数据中的复杂模式和特征,进而实现高精度的预测和分类任务。在前馈神经网络(Feedforward Neural Networks,FNNs)中,信息严格地从输入层流向输出层,每一层都通过一系列的权重和偏置对输入进行线性组合和非线性变换,最终生成网络的输出。本文将深入剖析深度神经网络中的前馈过程,包括其基本原理、实现步骤、激活函数的作用以及实际应用中的挑战与解决方案。
二、深度神经网络的基本结构
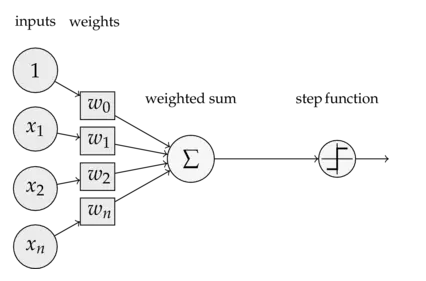
深度神经网络由多个层次组成,包括输入层、隐藏层和输出层。每一层都包含一定数量的神经元(或称节点),神经元之间通过权重和偏置相互连接。在前馈过程中,输入数据首先被送入输入层,然后逐层向前传播,经过各隐藏层的线性组合和非线性变换,最终生成输出层的结果。
- 输入层 :接收原始数据作为输入,不进行任何变换,仅将数据传递给下一层。
- 隐藏层 :位于输入层和输出层之间,是神经网络中最重要的部分。隐藏层可以对输入数据进行多次非线性变换,提取出数据中的高级特征。随着隐藏层数的增加,网络能够学习到更加复杂和抽象的特征表示。
- 输出层 :接收来自隐藏层的最后一组数据,经过适当的变换后输出最终的结果。对于分类任务,输出层通常采用softmax函数等将输出转换为概率分布;对于回归任务,则直接输出预测值。
三、前馈过程的实现步骤
深度神经网络中的前馈过程可以概括为以下几个步骤:
- 初始化参数 :在训练开始前,需要随机初始化网络中的权重和偏置。这些参数将在训练过程中通过反向传播算法进行更新。
- 接收输入数据 :将待处理的数据送入输入层。在实际应用中,输入数据通常需要经过预处理操作,如标准化、归一化等,以加快训练速度和提高模型性能。
- 前向传播 :从输入层开始,逐层计算每一层的输出。对于隐藏层中的每一个神经元,其输入为前一层所有神经元的输出加权和加上偏置项;然后,通过激活函数对加权和进行非线性变换,得到该神经元的输出。这一过程将一直持续到输出层生成最终结果。
- 计算输出 :在输出层,根据具体任务的需求对最后一层神经元的输出进行适当的变换(如softmax函数、sigmoid函数等),以得到最终的预测结果或分类概率。
四、激活函数的作用
激活函数是深度神经网络中不可或缺的一部分,它引入了非线性因素,使得神经网络能够学习复杂的模式和表示。在前馈过程中,激活函数对每一层神经元的加权和进行非线性变换,从而生成该神经元的输出。常见的激活函数包括Sigmoid、ReLU、Tanh等。
- Sigmoid函数 :将输入映射到(0,1)区间内,常用于二分类问题的输出层。然而,Sigmoid函数在深度网络中容易出现梯度消失问题,且其输出不是以0为中心的,这可能导致收敛速度变慢。
- ReLU函数 (Rectified Linear Unit):是目前最常用的激活函数之一。它对于所有正数输入返回其本身,对于负数输入则返回0。ReLU函数具有计算简单、收敛速度快等优点,且在一定程度上缓解了梯度消失问题。然而,当输入小于0时,ReLU函数的导数为0,这可能导致部分神经元在训练过程中“死亡”,即不再对输入数据产生任何响应。
- Tanh函数 :将输入映射到(-1,1)区间内,其输出是以0为中心的。与Sigmoid函数相比,Tanh函数在训练初期收敛速度更快,但其计算复杂度和梯度消失问题仍然存在。
五、实际应用中的挑战与解决方案
在将深度神经网络应用于实际问题时,可能会遇到一系列挑战,如梯度消失/爆炸、过拟合、计算资源限制等。针对这些问题,研究人员提出了多种解决方案:
- 梯度消失/爆炸 :通过选择合适的激活函数(如ReLU)、使用批归一化(Batch Normalization)等技术来缓解梯度消失/爆炸问题。此外,调整学习率、采用更先进的优化算法(如Adam)等也有助于改善梯度传播效果。
- 过拟合 :通过增加数据集规模、采用正则化技术(如L1/L2正则化、Dropout等)、提前停止训练等方法来防止过拟合。此外,还可以利用集成学习方法,如Bagging、Boosting等,通过结合多个模型的预测结果来提高整体模型的泛化能力。
- 计算资源限制 :随着深度神经网络层数的增加和模型复杂度的提升,对计算资源的需求也急剧增加。为了应对这一挑战,研究人员开发了多种优化技术,包括模型剪枝(去除不重要的神经元和连接)、量化(将模型权重从浮点数转换为整数或更低精度的浮点数)、知识蒸馏(将一个大型模型的知识迁移到一个小型模型中)等。此外,利用分布式计算和并行处理技术也是加速深度神经网络训练的有效手段。
- 数据不平衡 :在实际应用中,不同类别的样本数量往往存在显著差异,这会导致模型在少数类样本上的性能较差。为了解决数据不平衡问题,可以采用过采样(增加少数类样本的数量)、欠采样(减少多数类样本的数量)、合成少数类过采样技术(SMOTE)等方法来平衡各类样本的数量。同时,调整损失函数,如使用加权交叉熵损失,也可以在一定程度上缓解数据不平衡带来的问题。
- 可解释性 :虽然深度神经网络在许多任务上取得了卓越的性能,但其决策过程往往难以解释,这在一些需要高度可解释性的领域(如医疗、法律等)中成为了一个障碍。为了提高深度神经网络的可解释性,研究人员提出了多种方法,如特征可视化、注意力机制、LIME(Local Interpretable Model-agnostic Explanations)等。这些方法可以帮助我们理解模型是如何做出决策的,从而增加我们对模型预测结果的信任度。
六、前馈过程在深度学习框架中的实现
在现代深度学习框架(如TensorFlow、PyTorch等)中,前馈过程的实现变得非常简便。这些框架提供了丰富的API和工具,使得我们可以轻松地构建、训练和评估深度神经网络。在这些框架中,前馈过程通常通过定义一个计算图(Computational Graph)来实现,该图描述了数据在网络中的流动方向和变换过程。在训练过程中,框架会自动执行前馈过程,并根据损失函数的梯度进行反向传播和参数更新。
七、结论与展望
深度神经网络中的前馈过程是神经网络进行预测和分类任务的基础。通过逐层传递和变换输入数据,深度神经网络能够学习到数据中的复杂模式和特征,并生成准确的预测结果。然而,在实际应用中,我们还需要面对梯度消失/爆炸、过拟合、计算资源限制、数据不平衡和可解释性等挑战。为了解决这些问题,研究人员提出了多种优化技术和方法。未来,随着深度学习技术的不断发展和完善,我们有理由相信深度神经网络将在更多领域发挥重要作用,并为人类带来更多的便利和福祉。
同时,我们也应该注意到,虽然深度神经网络在许多任务上取得了令人瞩目的成绩,但其背后仍存在许多未解之谜和待探索的领域。例如,如何进一步提高深度神经网络的泛化能力、如何更好地理解和解释深度神经网络的决策过程、如何更有效地利用有限的计算资源等。这些问题的解决不仅需要我们不断探索和创新,还需要我们加强跨学科合作和交流,共同推动深度学习技术的发展和进步。
-
函数
+关注
关注
3文章
4352浏览量
63250 -
深度学习
+关注
关注
73文章
5527浏览量
121833 -
深度神经网络
+关注
关注
0文章
62浏览量
4604
发布评论请先 登录
相关推荐
基于三层前馈BP神经网络的图像压缩算法解析
基于递归神经网络和前馈神经网络的深度学习预测算法
快速了解神经网络与深度学习的教程资料免费下载





 工商网监
工商网监
评论