 自编码器的原理和类型
自编码器的原理和类型
一、自编码器概述
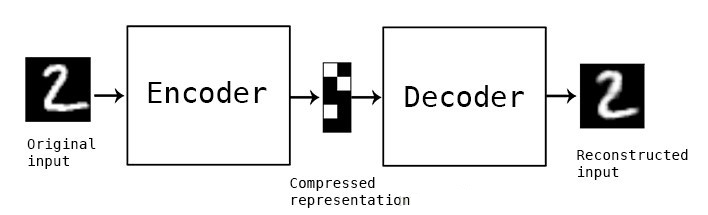
自编码器(Autoencoder, AE)是一种无监督学习的神经网络模型,它通过编码器和解码器的组合,实现了对输入数据的压缩和重构。自编码器由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器负责将输入数据映射到一个低维的潜在空间(latent space),而解码器则负责将这个低维表示映射回原始输入空间,从而实现对输入数据的重构。自编码器的目标是最小化重构误差,即使得解码器的输出尽可能接近原始输入数据。
自编码器最早由Yann LeCun在1987年提出,用于解决表征学习中的“编码器问题”,即基于神经网络的降维问题。随着深度学习的发展,自编码器在数据压缩、特征提取、图像生成等领域得到了广泛应用。
二、自编码器的原理
1. 编码器
编码器的主要作用是将输入数据映射到一个低维的潜在空间。这一过程通常通过多层神经网络实现,每一层都会对数据进行一定的变换和压缩,最终得到一个低维的编码表示。这个编码表示是输入数据的一种压缩形式,它包含了输入数据的主要特征信息,但去除了冗余和噪声。
2. 解码器
解码器的作用是将编码器的输出(即低维表示)映射回原始输入空间。与编码器相反,解码器通过多层神经网络逐层上采样和变换,将低维表示恢复成原始输入数据的近似形式。解码器的目标是使得重构后的数据与原始输入数据尽可能接近,即最小化重构误差。
3. 重构误差
重构误差是衡量自编码器性能的重要指标。它表示了原始输入数据与重构数据之间的差异程度。在训练过程中,自编码器通过不断调整编码器和解码器的参数来减小重构误差,从而实现对输入数据的更好重构。
4. 学习过程
自编码器的训练过程是一个无监督学习的过程。在训练过程中,不需要额外的标签信息,只需要输入数据本身即可。通过前向传播计算重构误差,然后通过反向传播算法调整网络参数以减小重构误差。这个过程会不断迭代进行,直到重构误差达到一个可接受的范围或者训练轮次达到预设的上限。
三、自编码器的类型
自编码器根据其结构和功能的不同可以分为多种类型,包括但不限于以下几种:
1. 基本自编码器(Vanilla Autoencoder)
基本自编码器是最简单的自编码器形式,由一个编码器和一个解码器组成。它主要用于数据压缩和去噪等任务。
2. 稀疏自编码器(Sparse Autoencoder)
稀疏自编码器在基本自编码器的基础上增加了稀疏性约束,通过限制隐藏层神经元的激活程度来避免过拟合和提高特征表示的稀疏性。
3. 收缩自编码器(Contractive Autoencoder)
收缩自编码器通过添加对编码器输出关于输入数据变化的惩罚项来鼓励学习到的表示对数据变化具有鲁棒性。这种自编码器对于异常值检测等任务特别有效。
4. 变分自编码器(Variational Autoencoder, VAE)
变分自编码器是一种生成模型,它通过引入随机变量来生成输入数据的潜在表示。VAE可以生成与原始数据分布相似的新数据样本,因此在图像生成、文本生成等领域具有广泛应用。
5. 卷积自编码器(Convolutional Autoencoder)
卷积自编码器特别适用于图像数据的处理。它通过卷积层和池化层来实现对图像数据的压缩和重构,能够保留图像的主要特征信息并去除噪声。
四、自编码器的应用
自编码器在多个领域都有广泛的应用,包括但不限于以下几个方面:
1. 数据压缩
自编码器通过将输入数据映射到低维潜在空间来实现数据压缩。与传统的数据压缩方法相比,自编码器能够学习到更加紧凑和有效的数据表示方式。
2. 特征提取
自编码器在特征提取方面表现出色。通过训练自编码器,可以得到输入数据的有效特征表示,这些特征表示可以用于后续的分类、聚类等任务。
3. 图像生成
变分自编码器等生成模型可以生成与原始图像相似的新图像样本。这对于图像增强、图像修复等任务具有重要意义。
4. 异常值检测
收缩自编码器等类型的自编码器可以通过学习输入数据的正常分布来检测异常值。当输入数据偏离正常分布时,自编码器的重构误差会显著增加,从而可以识别出异常值。
五、代码实现
下面是一个使用Python和TensorFlow实现的基本自编码器的示例代码:
import tensorflow as tf
# 定义编码器和解码器
def encoder(x, encoding_dim):
hidden = tf.layers.dense(x, 1
hidden = tf.layers.dense(x, encoding_dim, activation='relu')
return hidden
def decoder(x, decoding_dim, input_shape):
hidden = tf.layers.dense(x, decoding_dim, activation='relu')
output = tf.layers.dense(hidden, np.prod(input_shape), activation='sigmoid')
output = tf.reshape(output, [-1, *input_shape])
return output
# 输入数据的维度
input_shape = (28, 28, 1) # 例如,MNIST数据集的图像大小
input_img = tf.keras.layers.Input(shape=input_shape)
# 编码维度
encoding_dim = 32 # 可以根据需要调整
# 通过编码器获取编码
encoded = encoder(input_img, encoding_dim)
# 解码器输出重构的图像
decoded = decoder(encoded, encoding_dim, input_shape)
# 自编码器模型
autoencoder = tf.keras.Model(input_img, decoded)
# 编码器模型
encoder_model = tf.keras.Model(input_img, encoded)
# 解码器模型(需要自定义输入层)
encoder_output = tf.keras.layers.Input(shape=(encoding_dim,))
decoder_layer = decoder(encoder_output, encoding_dim, input_shape)
decoder_model = tf.keras.Model(encoder_output, decoder_layer)
# 编译模型
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
# 假设我们有一些MNIST数据用于训练
# 这里仅展示模型构建过程,数据加载和训练过程略去
# ...
# data_x = ... # 训练数据
# autoencoder.fit(data_x, data_x, epochs=50, batch_size=256, shuffle=True, validation_split=0.2)
# 使用自编码器进行预测(重构)
# reconstructed_imgs = autoencoder.predict(data_x)
# 注意:上述代码是一个框架示例,实际使用时需要根据你的具体数据和需求进行调整。
# 例如,你可能需要加载MNIST数据集,预处理数据,然后训练模型。
在这个示例中,我们定义了一个基本自编码器的编码器和解码器部分。编码器通过一个全连接层将输入图像压缩成一个低维的编码表示,而解码器则通过另一个全连接层和重塑操作将编码表示恢复成原始图像的大小。
我们使用了TensorFlow的高级API tf.keras 来构建和编译模型。模型autoencoder是一个完整的自编码器,它包含了编码器和解码器两部分。此外,我们还分别构建了只包含编码器的encoder_model和只包含解码器的decoder_model,以便在需要时单独使用它们。
请注意,这个示例代码并没有包含数据加载和训练的部分,因为那将取决于你具体使用的数据集和训练环境。在实际应用中,你需要加载你的数据集(如MNIST手写数字数据集),将其预处理为适合模型输入的格式,并使用autoencoder.fit()方法来训练模型。
自编码器的性能很大程度上取决于其结构和超参数的选择,如编码维度encoding_dim、隐藏层的大小和激活函数等。这些参数需要通过实验和调整来找到最优的组合。
-
编码器
+关注
关注
45文章
3584浏览量
134105 -
神经网络
+关注
关注
42文章
4762浏览量
100517 -
模型
+关注
关注
1文章
3158浏览量
48700
发布评论请先 登录
相关推荐
基于变分自编码器的异常小区检测
是什么让变分自编码器成为如此成功的多媒体生成工具呢?

自编码器介绍
稀疏自编码器及TensorFlow实现详解
基于稀疏自编码器的属性网络嵌入算法SAANE
自编码器基础理论与实现方法、应用综述
自编码器神经网络应用及实验综述
六种不同类型的编码器 对应旋转和线性编码器有什么区别?
旋转编码器如何工作?有哪些类型?
堆叠降噪自动编码器(SDAE)
自编码器 AE(AutoEncoder)程序

磁性编码器和光电编码器的比较
旋转编码器的常见类型
编码器类型详解:探索不同编码技术的奥秘






 工商网监
工商网监
评论