 Transformer架构在自然语言处理中的应用
Transformer架构在自然语言处理中的应用
引言
随着人工智能技术的飞速发展,自然语言处理(NLP)领域取得了显著的进步。其中,Transformer架构的提出,为NLP领域带来了革命性的变革。本文将深入探讨Transformer架构的核心思想、组成部分以及在自然语言处理领域的应用,旨在帮助读者全面理解并应用这一革命性的技术。
Transformer架构的核心思想
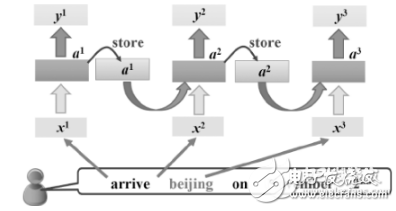
Transformer架构的核心思想是使用自注意力机制(self-attention mechanism)来建立输入序列的表示。传统的循环神经网络(RNN)架构在处理序列数据时,需要按照顺序逐步处理,这在一定程度上限制了模型的并行处理能力。而Transformer架构则打破了这一限制,通过自注意力机制并行地处理整个序列,大大提高了模型的计算效率。
自注意力机制
自注意力机制是Transformer架构的核心组成部分。它允许模型在处理序列中的每个元素时,都能够关注到序列中的其他元素,从而捕获序列中任意两个位置之间的依赖关系,无论它们之间的距离有多远。对于输入序列中的每个词,计算其与其他词的点积,然后通过softmax函数转化为权重,这些权重会被用来组合输入的词向量,生成一个新的上下文相关的词向量。
编码器与解码器
Transformer架构由两个主要组件组成:编码器(Encoder)和解码器(Decoder)。编码器负责将输入序列编码成一个表示,而解码器则根据该表示生成输出序列。每个组件都由多个层级组成,每个层级包含多头自注意力机制和全连接神经网络。
- 编码器 :编码器的主要任务是将输入序列转换为一种内部表示。在编码器中,每个层级的输入首先通过自注意力机制进行处理,然后通过全连接神经网络进行变换。经过多个层级的堆叠,编码器最终将输入序列转换为一个固定长度的向量表示。
- 解码器 :解码器的主要任务是根据编码器的输出生成目标序列。与编码器类似,解码器也包含多个层级,每个层级都包含自注意力机制和全连接神经网络。不同的是,解码器在每个层级的输入中还会引入编码器的输出作为上下文信息,以便在生成目标序列时能够考虑到源语言序列的信息。
Transformer架构的组成部分
自注意力层
自注意力层是Transformer架构中的核心层。它通过计算输入序列中每个元素与其他元素之间的相关性,来生成新的上下文相关的表示。每个自注意力层都包含多个头(head),每个头都可以独立地进行自注意力计算,并将结果拼接后通过线性变换得到最终输出。这种多头自注意力机制可以更好地捕捉到输入序列中的局部和全局信息。
前馈神经网络层
前馈神经网络层是一个普通的全连接神经网络,它会对自注意力层的输出进行进一步的处理。前馈神经网络层的作用是对自注意力层的输出进行非线性变换,以提高模型的表示能力。
残差连接与层归一化
在Transformer架构中,每个子层后面都有一个残差连接和层归一化操作。残差连接通过在网络中引入跳跃连接,将前一层的输入直接与当前层的输出相加,以避免在深度神经网络训练过程中出现梯度消失或梯度爆炸的问题。层归一化则是一种特征缩放技术,用于稳定深度神经网络的训练过程。
Transformer架构在自然语言处理中的应用
预训练语言模型
预训练语言模型(Pretrained Language Model)是利用大规模语料库进行训练,从而得到具有强大表示能力的模型。其中最具代表性的模型之一是BERT(Bidirectional Encoder Representations from Transformers),它通过使用Transformer模型进行双向上下文信息的捕捉,在多项NLP任务中取得了显著成果。另一个重要的模型是GPT(Generative Pre-trained Transformer),它通过自回归的方式进行语言建模,在文本生成、文本摘要等任务中表现出色。
机器翻译
机器翻译是自然语言处理领域的经典任务之一。传统的基于RNN或LSTM的翻译方法在处理长序列时会出现梯度消失或梯度爆炸的问题。而基于Transformer的翻译方法通过使用自注意力机制进行信息的交互与传递,可以更好地捕捉到源语言和目标语言之间的语义关系。因此,基于Transformer的翻译方法在翻译质量、速度和灵活性等方面都表现出了显著的优势。
文本分类与情感分析
Transformer模型也被广泛应用于文本分类和情感分析任务中。通过将文本输入到预训练语言模型中,可以得到文本的向量表示,进而使用分类器或回归器对文本进行分类或情感极性预测。Transformer模型在文本分类和情感分析任务中表现出了较高的准确率和鲁棒性。
其他应用
除了上述应用外,Transformer模型还被广泛应用于其他自然语言处理任务中,如问答系统、命名实体识别、文本生成等。其强大的表示能力和高效的处理能力使得它在各种NLP任务中都取得了优异的成绩。
实践建议与未来展望
实践建议
- 数据预处理 :对输入序列进行合适的数据预处理是提高模型性能的关键。例如,对于文本数据,可以进行分词、去除停用词等操作,以提高模型的泛化能力。
- 模型调优 :针对具体任务调整模型参数和结构是提高模型性能的有效途径。对于Transformer模型而言,可以通过以下几种方式进行调优:
- 调整层数和头数 :增加Transformer模型的层数和头数可以提高模型的复杂度和表示能力,但也会增加模型的计算量和训练时间。因此,需要根据具体任务的需求和计算资源来选择合适的层数和头数。
- 调整隐藏层大小 :隐藏层大小是模型参数量的一个重要因素,增加隐藏层大小可以提高模型的表示能力,但也会增加模型的复杂度和训练难度。因此,需要在模型性能和计算资源之间做出权衡。
- 使用预训练模型 :利用在大规模语料库上预训练的模型进行微调,可以显著提高模型在特定任务上的性能。预训练模型已经学习到了丰富的语言知识和表示能力,通过微调可以使其更好地适应具体任务的需求。
训练策略
采用合适的训练策略对于提高模型性能至关重要。以下是一些常用的训练策略:
- 预训练加微调 :先在大规模语料库上进行预训练,然后在具体任务上进行微调。这种方式可以充分利用预训练模型学到的语言知识和表示能力,同时避免从头开始训练模型所需的巨大计算量和时间成本。
- 混合精度训练 :通过使用混合精度(Mixed Precision)训练技术,可以在保持模型性能的同时减少计算量和内存占用。混合精度训练通常涉及使用半精度(FP16)或更低精度的浮点数进行计算,并通过特定的优化算法来减少精度损失。
- 分布式训练 :利用多台机器或多块GPU进行分布式训练,可以显著加快模型的训练速度。分布式训练通过并行计算和数据并行等方式,将训练任务分解到多个计算节点上,从而实现更快的训练速度。
未来展望
Transformer架构的未来发展潜力仍然巨大。随着技术的不断进步和应用场景的不断拓展,我们可以期待以下几个方面的发展:
- 更高效的模型设计 :未来的研究将聚焦于设计更轻量级、更高效的Transformer模型,以满足低资源场景和实时应用的需求。这可能涉及到模型剪枝、量化、蒸馏等技术,以减少模型的计算量和存储需求。
- 跨模态学习与推理 :随着多模态数据的日益丰富,Transformer架构有望扩展到音频、视频、图像等领域,实现跨模态的学习和推理。这将使得人工智能系统能够同时理解和处理多种类型的数据,从而在实际应用中发挥更大的作用。
- 增强可解释性和鲁棒性 :虽然Transformer模型在多个领域取得了显著的成果,但其内部机制仍然相对复杂,缺乏直观的解释性。未来的研究将聚焦于提高Transformer模型的可解释性,揭示其内部工作机制,并增强其鲁棒性,以应对各种复杂和不确定的情况。
- 持续学习与自适应能力 :随着人工智能应用的不断发展,模型需要不断适应新的数据和任务。未来的Transformer模型将具备更强的持续学习和自适应能力,能够在线学习和更新,以适应不断变化的环境和需求。这将使得人工智能系统更加智能、灵活和可靠。
总之,Transformer架构作为自然语言处理领域的重要里程碑,其未来发展潜力仍然无限。通过不断研究和探索,我们有信心将Transformer模型打造成为引领人工智能新纪元的关键技术。
-
人工智能
+关注
关注
1791文章
47137浏览量
238114 -
Transformer
+关注
关注
0文章
143浏览量
5995 -
自然语言处理
+关注
关注
1文章
618浏览量
13545
发布评论请先 登录
相关推荐
【推荐体验】腾讯云自然语言处理
什么是自然语言处理?
RNN在自然语言处理中的应用





 工商网监
工商网监
评论