 机器学习中的数据预处理与特征工程
机器学习中的数据预处理与特征工程
在机器学习的整个流程中,数据预处理与特征工程是两个至关重要的步骤。它们直接决定了模型的输入质量,进而影响模型的训练效果和泛化能力。本文将从数据预处理和特征工程的基本概念出发,详细探讨这两个步骤的具体内容、方法及其在机器学习中的应用。
一、数据预处理
数据预处理是机器学习过程中的第一步,也是至关重要的一步。它的主要目的是提高数据的质量,确保数据的一致性和准确性,从而为后续的模型训练提供可靠的基础。数据预处理通常包括以下几个方面:
1. 数据清洗
数据清洗是数据预处理的核心环节,主要目的是消除数据中的噪声、缺失值和异常值。具体方法包括:
- 缺失值处理 :对于数据中的缺失值,可以采用删除法或插补法进行处理。删除法包括删除观测样本、删除变量、使用完整原始数据分析以及改变权重等方法。插补法则是在条件允许的情况下,找到缺失值的替代值进行插补,常用的插补方法包括均值插补、回归插补、热平台插补和冷平台插补等。
- 异常值处理 :异常值(或称离群点)是指与数据集中其他观测值有显著不同的数据点。这些点可能是由于测量误差、数据输入错误或真实的异常情况造成的。处理异常值的方法包括删除这些点、使用鲁棒的统计数据代替受影响的统计量,或在模型训练中使用能够抵抗异常点的算法。
- 噪声处理 :噪声是数据中的随机错误和偏差,可以通过分箱、聚类、回归等方法进行“光滑”处理,以去除数据中的噪声。
2. 数据集成
数据集成是将多个数据源中的数据合并到一个一致的数据存储中的过程。这些数据源可能包括多个数据库、数据立方体或一般文件。在数据集成过程中,需要解决的主要问题包括如何对多个数据集进行匹配以及如何处理数据冗余。
3. 数据变换
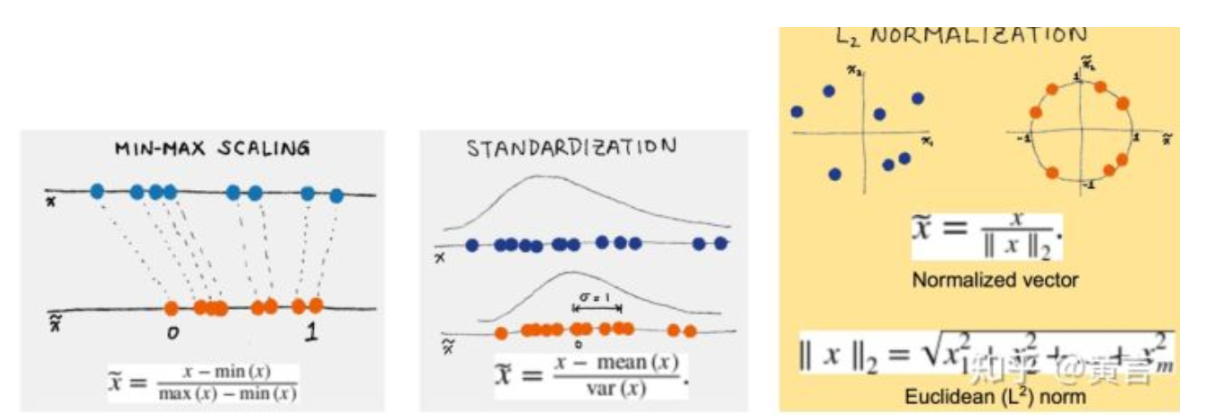
数据变换是找到数据的特征表示,用维度变换来减少有效变量的数目或找到数据的不变式。常用的数据变换方法包括规格化、规约、切换和投影等操作。其中,规格化(如标准化和归一化)是常用的特征缩放方法,旨在将不同范围的特征值归一化到相同的尺度,以消除数据不同特征的尺度差异。
二、特征工程
特征工程是机器学习中至关重要的步骤,它是指将原始数据转换为机器可理解的特征表示形式的过程。特征工程的目标是提取和选择对于机器学习算法来说最有信息量和预测能力的特征,从而改善模型的性能。
1. 特征构建
特征构建是通过对原始特征进行组合、转换和提取来创建新的特征的过程。特征构建可以帮助机器学习算法更好地捕捉数据中的模式和关系。常用的特征构建方法包括多项式特征、交互特征和集合特征等。多项式特征通过对原始特征进行多项式扩展来创建新的特征;交互特征通过对多个特征进行相乘或相除来创建新的特征;集合特征则通过统计数据集中某个特征的计数或频率来创建新的特征。
2. 特征编码
特征编码是将非数值特征转换为机器学习算法能够处理的数值特征的过程。常用的特征编码方法包括独热编码和标签编码。独热编码将一个具有n个不同取值的特征转换为一个n维的二进制向量,其中只有一个元素为1,其余元素都为0。标签编码则将不同取值的特征分配一个整数标签。
3. 特征选择
特征选择是从原始特征中选择最重要的特征子集的过程。特征选择有助于减少特征维度,提高模型的泛化能力和训练速度。常用的特征选择方法包括过滤法、包装法和嵌入法。过滤法通过计算特征与目标变量之间的相关性来选择特征;包装法通过训练并评估模型的性能来选择特征;嵌入法则将特征选择嵌入到模型训练的过程中。
4. 特征降维
特征降维是减少特征维度的过程,它可以简化模型的复杂度并提高模型的训练效率和泛化能力。常用的特征降维方法包括主成分分析(PCA)和线性判别分析(LDA)。PCA通过线性变换将原始特征投影到一个低维度的子空间中;LDA则通过最大化类间距离和最小化类内距离来选择重要的特征。
三、数据预处理与特征工程在机器学习中的应用
在机器学习的实际应用中,数据预处理与特征工程往往是紧密结合在一起的。有效的数据预处理可以提高数据的质量,为后续的特征工程提供可靠的基础;而精心的特征工程则可以进一步提取和选择最有信息量和预测能力的特征,从而显著提升模型的性能。
具体来说,数据预处理与特征工程在机器学习中的应用可以概括为以下几个步骤:
- 数据收集与整理 :首先收集相关的原始数据,并进行初步的整理和清洗,以消除数据中的噪声、缺失值和异常值。
- 特征构建与编码 :根据问题的需求和数据的特点,构建新的特征并进行编码处理,以便机器学习算法能够理解和处理这些数据。3. 特征选择与降维 :在构建了丰富的特征集之后,接下来进行特征选择和降维。这一步骤旨在剔除冗余或无关的特征,减少模型的复杂度,提高训练效率和泛化能力。通过特征选择,我们可以识别出哪些特征对模型的预测性能贡献最大,从而保留这些重要特征,去除或忽略其他不重要的特征。同时,特征降维技术如PCA、LDA等可以帮助我们进一步减少特征的数量,同时尽量保留原始数据中的信息。
- 模型训练与评估 :在完成了数据预处理和特征工程之后,我们就可以使用处理好的数据来训练机器学习模型了。训练过程中,我们会不断调整模型的参数,以最小化损失函数,提高模型的预测准确性。同时,为了评估模型的性能,我们需要使用一部分未参与训练的数据(如验证集或测试集)来测试模型的泛化能力。
- 模型优化与迭代 :根据模型在测试集上的表现,我们可能会发现模型在某些方面存在不足,如过拟合、欠拟合或泛化能力差等。这时,我们需要回到数据预处理和特征工程的步骤,重新审视我们的数据处理和特征选择策略,进行必要的调整和优化。这个过程可能需要多次迭代,直到我们找到最佳的模型配置为止。
四、数据预处理与特征工程的挑战与解决策略
尽管数据预处理与特征工程在机器学习中扮演着至关重要的角色,但它们也面临着一些挑战。以下是一些常见的挑战及其解决策略:
- 数据质量差 :原始数据中可能存在大量的噪声、缺失值和异常值,这会严重影响模型的性能。解决策略包括使用数据清洗技术来消除这些不良数据,以及采用鲁棒的机器学习算法来抵抗噪声和异常值的影响。
- 特征维度高 :在许多实际应用中,数据的特征维度可能非常高,这会导致计算复杂度高、模型训练时间长等问题。解决策略包括使用特征选择和降维技术来减少特征的数量,同时尽量保留原始数据中的有用信息。
- 特征冗余 :特征之间可能存在冗余或相关性,这会导致模型过拟合或降低预测准确性。解决策略包括使用相关性分析或聚类分析等方法来识别冗余特征,并在特征选择过程中予以剔除。
- 领域知识不足 :在某些领域,如医学、金融等,数据可能具有高度的专业性和复杂性,而机器学习工程师可能缺乏相应的领域知识。这会导致在特征构建和选择过程中难以把握关键特征。解决策略包括与领域专家合作,共同进行特征工程的设计和实施。
五、结论
数据预处理与特征工程是机器学习中不可或缺的两个步骤。它们对于提高模型性能、防止过拟合和增强模型泛化能力具有至关重要的作用。通过精心设计和实施数据预处理与特征工程策略,我们可以从原始数据中提取出最有价值的信息,为机器学习模型的训练提供可靠的基础。然而,我们也应该认识到这两个步骤所面临的挑战,并采取相应的解决策略来克服这些挑战。随着数据科学和机器学习技术的不断发展,我们相信数据预处理与特征工程将会变得更加高效和智能化,为更多的应用场景提供有力的支持。
-
模型
+关注
关注
1文章
3238浏览量
48824 -
机器学习
+关注
关注
66文章
8414浏览量
132604 -
数据预处理
+关注
关注
1文章
20浏览量
2758
发布评论请先 登录
相关推荐










 工商网监
工商网监
评论