 大语言模型的预训练
大语言模型的预训练
引言
随着人工智能技术的飞速发展,自然语言处理(NLP)作为人工智能领域的一个重要分支,取得了显著的进步。其中,大语言模型(Large Language Model, LLM)凭借其强大的语言理解和生成能力,逐渐成为NLP领域的研究热点。大语言模型的预训练是这一技术发展的关键步骤,它通过在海量无标签数据上进行训练,使模型学习到语言的通用知识,为后续的任务微调奠定基础。本文将深入探讨大语言模型预训练的基本原理、步骤以及面临的挑战。
大语言模型的基本概念
大语言模型指的是具有数十亿甚至数千亿参数的神经网络模型,这些模型能够在海量文本数据上进行训练,并学习到丰富的语言知识和语义信息。相比传统的自然语言处理模型,大语言模型具有以下几个显著优势:
- 强大的语言理解能力 :能够理解复杂的语义信息,并生成高质量的文本内容。
- 广泛的应用场景 :可以应用于机器翻译、文本摘要、问答系统、对话生成等多个领域。
- 持续的性能提升 :随着模型规模和训练数据的不断增加,大语言模型的性能也在持续提升。
预训练的基本原理
预训练是迁移学习的一种形式,它通过在大规模无标签数据上进行训练,使模型学习到通用的语言知识,然后再针对特定任务进行微调。预训练的主要目的是解决数据稀缺性和迁移学习问题,提高模型的泛化能力和训练效率。
Transformer模型
在大语言模型中,Transformer模型因其强大的语言处理能力而备受青睐。Transformer是一种基于自注意力机制的神经网络架构,它能够有效地捕捉文本序列中的长距离依赖关系,从而提升模型的语言理解能力。Transformer架构包含多个编码器层和解码器层,每个编码器层包含一个自注意力模块和一个前馈神经网络,解码器层则在此基础上增加了一个交叉注意力模块,用于关注编码器层的输出。
自注意力机制
自注意力机制是Transformer架构的核心组成部分,它允许模型在处理每个词语时,同时关注句子中的其他词语,从而更好地理解词语之间的语义联系。
预训练的具体步骤
大语言模型的预训练过程通常包括以下几个关键步骤:
数据收集与预处理
- 数据收集 :收集大量的文本数据,包括书籍、新闻、社交媒体、网页等,以便训练模型。
- 数据预处理 :对收集到的数据进行清洗、分词、去除停用词、词干提取等处理,以提高模型的训练效果。
模型设计
选择合适的模型架构,如Transformer,并设置模型参数。在大语言模型中,Transformer模型因其高效性和强大的语言处理能力而被广泛应用。
模型训练
- 预训练目标 :预训练的主要目标是学习通用的语言知识,以便在后续的特定任务中进行微调。常见的预训练目标包括语言模型(预测下一个词语的概率)、掩码语言模型(预测被掩盖词语的概率)和句子顺序预测(判断两个句子的顺序是否正确)。
- 训练过程 :使用随机梯度下降等优化算法对模型进行训练,同时设置合适的学习率、批次大小等超参数。在训练过程中,模型会学习到词语的语义、句子的语法结构以及文本的一般知识和上下文信息。
模型评估与优化
- 模型评估 :使用测试数据对模型进行评估,以衡量其语言理解能力。常见的评估指标包括困惑度(衡量模型预测下一个词语的不确定性)和下游任务性能(衡量模型在特定任务上的性能表现)。
- 模型优化 :根据评估结果对模型进行优化,如调整超参数、使用正则化技术、使用预训练模型等,以提高模型的性能和泛化能力。
模型部署
将训练好的模型部署到生产环境中,以便实现对文本的自然语言处理。在实际应用中,还需要对模型进行微调,以适应特定的任务需求。
预训练的优势与挑战
优势
- 提高模型的泛化能力 :通过大规模预训练,模型可以学习到更多的数据和知识,从而提高其对未知数据的泛化能力。
- 减少训练时间和数据量 :预训练可以大幅减少后续任务所需的训练时间和数据量,因为预训练的结果可以直接应用到其它任务上。
- 提高算法的效率 :预训练可以使得算法更加高效,因为预训练的结果可以作为其它任务的初始值,避免从头开始训练的时间和计算资源浪费。
挑战
- 计算成本高昂 :大语言模型由于参数量巨大,训练过程中需要消耗大量的计算资源。随着模型规模的增加,计算成本也呈指数级增长,这对硬件设备和能源效率提出了巨大挑战。
- 数据隐私与偏见 :在收集和处理大量数据时,数据隐私成为一个关键问题。如何确保个人隐私不被泄露,同时避免模型学习到数据中的偏见和歧视性信息,是预训练过程中必须面对的挑战。
- 模型可解释性 :尽管大语言模型在性能上取得了显著进步,但其内部工作机制仍然相对不透明。这导致模型在做出决策时缺乏可解释性,增加了在关键应用领域中应用的难度和风险。
- 优化超参数 :预训练模型通常包含数以亿计的参数,如何有效地优化这些参数以最大化模型性能是一个复杂的问题。超参数的调整需要大量的实验和计算资源,且往往依赖于经验和直觉。
- 持续学习与适应性 :现实世界的数据是不断变化的,新的词汇、表达方式和知识不断涌现。大语言模型需要具备持续学习的能力,以适应这些变化,并保持其性能优势。然而,如何在不破坏已学知识的前提下进行持续学习,仍然是一个未解难题。
- 模型压缩与部署 :尽管大语言模型在性能上表现出色,但其庞大的体积限制了其在资源受限设备上的部署。因此,如何在保持模型性能的同时进行压缩和优化,是另一个重要的研究方向。
未来展望
面对上述挑战,未来的大语言模型预训练研究将朝着以下几个方向发展:
- 更高效的算法与架构 :研究人员将继续探索更高效的算法和神经网络架构,以降低计算成本并提高训练效率。例如,通过引入稀疏连接、量化技术和混合精度训练等方法来减少模型参数和计算量。
- 数据隐私保护与去偏见 :在数据收集和处理过程中,将更加注重隐私保护和去偏见技术的研究。例如,通过差分隐私、联邦学习等技术来保护用户隐私;通过数据增强、对抗性训练等方法来减少模型偏见。
- 可解释性增强 :为了提高模型的可解释性,研究人员将探索更多的解释性技术。例如,通过注意力可视化、知识蒸馏等方法来揭示模型的内部工作机制;通过构建可解释性更强的模型架构来直接提高模型的可解释性。
- 持续学习与自适应 :为了应对现实世界数据的变化,研究人员将研究更加高效的持续学习和自适应技术。例如,通过增量学习、元学习等方法来使模型能够在线更新并适应新数据;通过引入记忆模块来保存并利用历史知识。
- 模型压缩与优化 :在模型部署方面,研究人员将继续探索模型压缩与优化技术。例如,通过剪枝、量化、蒸馏等方法来减少模型体积并提高计算效率;通过优化模型架构来直接减少参数数量并保持性能优势。
综上所述,大语言模型的预训练是自然语言处理领域的一个重要研究方向。虽然目前仍面临诸多挑战,但随着技术的不断进步和创新,相信未来大语言模型将在更多领域展现出其巨大的潜力和价值。
-
人工智能
+关注
关注
1791文章
46820浏览量
237455 -
模型
+关注
关注
1文章
3158浏览量
48700 -
自然语言处理
+关注
关注
1文章
611浏览量
13503
发布评论请先 登录
相关推荐
一文详解知识增强的语言预训练模型
【大语言模型:原理与工程实践】大语言模型的预训练
一套新的自然语言处理(NLP)评估基准,名为 SuperGLUE
微软团队发布生物医学领域NLP基准
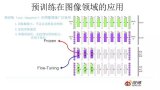
自然语言模型预训练的发展史






 工商网监
工商网监
评论