 什么是神经网络加速器?它有哪些特点?
什么是神经网络加速器?它有哪些特点?
一、神经网络加速器概述
神经网络加速器是一种专门设计用于提高神经网络计算效率的硬件设备。随着深度学习技术的快速发展和广泛应用,神经网络模型的复杂度和计算量急剧增加,对计算性能的要求也越来越高。传统的通用处理器(CPU)和图形处理器(GPU)虽然可以处理神经网络计算,但在能效比和计算密度上往往难以满足特定应用场景的需求。因此,神经网络加速器应运而生,它通过优化硬件架构和算法实现,针对神经网络计算的特点进行定制化设计,以达到更高的计算效率和更低的功耗。
二、神经网络加速器的主要特点
- 定制化设计 :神经网络加速器针对神经网络计算的特点进行定制化设计,包括计算单元、存储结构和数据流控制等方面,以最大化计算效率和能效比。
- 高效并行处理 :神经网络加速器通常支持大量的并行计算单元,能够同时处理多个数据点和计算任务,从而显著提高计算速度。
- 低功耗 :通过优化硬件架构和算法实现,神经网络加速器能够在保证计算性能的同时降低功耗,适用于对能耗有严格要求的嵌入式和移动设备。
- 灵活性 :虽然神经网络加速器是定制化设计,但也需要具备一定的灵活性以支持不同规模和结构的神经网络模型。
三、神经网络加速器的实现方式
神经网络加速器的实现方式多种多样,包括基于FPGA(现场可编程门阵列)、ASIC(专用集成电路)和GPU等不同的硬件平台。以下分别介绍这几种实现方式的特点和实现步骤。
1. 基于FPGA的神经网络加速器
特点 :
- 可编程性 :FPGA具有高度的可编程性,可以根据需要灵活配置硬件资源,以适应不同规模和结构的神经网络模型。
- 快速迭代 :FPGA开发周期相对较短,可以快速进行算法验证和硬件迭代优化。
- 成本效益 :相比ASIC,FPGA的初始投资成本较低,且具有较高的灵活性,适用于算法快速变化和需要频繁迭代的场景。
实现步骤 :
- 算法分析 :对神经网络模型进行算法分析,确定计算量、内存访问模式和并行性需求等关键指标。
- 硬件架构设计 :根据算法分析结果设计FPGA的硬件架构,包括计算单元、存储单元和数据流控制单元等。
- HDL编码 :使用硬件描述语言(如Verilog或VHDL)对硬件架构进行编码实现。
- 仿真验证 :在FPGA开发环境中进行仿真验证,确保设计的正确性和性能满足要求。
- 综合与布局布线 :将HDL代码综合成门级网表,并进行布局布线以生成比特流文件。
- 下载与测试 :将比特流文件下载到FPGA开发板上进行实际测试,评估性能、功耗和稳定性等指标。
2. 基于ASIC的神经网络加速器
特点 :
- 高性能 :ASIC针对特定应用进行定制化设计,能够实现极高的计算性能和能效比。
- 低成本 :一旦设计完成并量产,ASIC的单位成本通常较低。
- 低灵活性 :ASIC的硬件资源一旦固定就难以更改,因此灵活性较低。
实现步骤 :
由于ASIC的设计和实现过程相对复杂且涉及的知识产权问题较多,这里不再详细展开。但一般来说,ASIC的设计流程包括需求分析、架构设计、RTL编码、仿真验证、综合与布局布线、流片生产等步骤。
3. 基于GPU的神经网络加速器
特点 :
- 高并行性 :GPU具有大量的并行计算核心和高速内存带宽,适用于处理大规模并行计算任务。
- 通用性 :GPU不仅可以用于神经网络计算,还可以用于图形渲染、科学计算等多种应用场景。
- 成本较高 :相比FPGA和ASIC,GPU的功耗和成本通常较高。
实现方式 :
基于GPU的神经网络加速器主要通过优化GPU上的神经网络计算库(如cuDNN、TensorRT等)和并行编程模型(如CUDA、OpenCL等)来实现。开发者可以利用这些库和模型来编写高效的神经网络计算程序,并充分利用GPU的并行计算能力来提高计算效率。
四、神经网络加速器的优化策略
为了提高神经网络加速器的性能和效率,研究者们提出了多种优化策略。以下是一些常见的优化策略:
- 量化与压缩 :通过将神经网络的权重和激活值从浮点数表示转换为定点数表示,并应用剪枝、量化和编码等技术来减少模型的大小和计算复杂度。这不仅可以降低存储和计算开销,还可以提高计算速度和能效比。
- 稀疏计算 :利用神经网络中的稀疏性质(即许多权重值为零或接近零),仅对非零元素进行计算。这可以显著减少计算量并提高效率。在硬件实现上,可以采用稀疏矩阵存储和稀疏矩阵乘法等技术来实现稀疏计算。
- 分布式计算 :将计算任务分配给多个计算单元或设备,实现分布式计算。这不仅可以提高计算速度,还可以利用多个计算资源来应对大规模神经网络计算的需求。在神经网络加速器中,可以通过多核处理器、多FPGA芯片或多GPU卡等方式来实现分布式计算。
- 数据流优化 :优化数据在加速器中的流动方式,减少数据搬移和缓存等待时间。例如,采用流水线技术、乒乓缓存(Ping-Pong Buffer)策略、以及直接内存访问(DMA)技术,来确保数据能够高效、连续地供给给计算单元。
- 算法级优化 :针对神经网络的特定算法特点进行优化。例如,在卷积神经网络(CNN)中,可以通过权重共享、滑动窗口和并行计算等技术来减少计算量;在循环神经网络(RNN)中,可以通过展开循环、使用LSTM或GRU等优化单元来减少梯度消失和梯度爆炸的问题。
- 自动调优技术 :利用机器学习或自动化工具来自动搜索和优化神经网络加速器的配置参数。这包括硬件资源的分配、计算单元的调度、内存访问策略等。通过自动调优技术,可以在不增加人工干预的情况下,找到最优的硬件实现方案。
- 混合精度计算 :结合使用不同精度的数据类型进行计算。例如,在训练阶段使用较高精度的浮点数来保证模型的收敛性,而在推理阶段则使用较低精度的定点数来降低计算复杂度和功耗。混合精度计算可以在保持模型性能的同时,显著提高计算效率。
- 动态可重构性 :设计支持动态可重构的神经网络加速器,以适应不同规模和结构的神经网络模型。通过在线重新配置硬件资源,可以实现计算资源的灵活调度和优化,以应对不同的计算需求。
五、神经网络加速器的应用前景
随着深度学习技术的不断发展和普及,神经网络加速器在各个领域的应用前景越来越广阔。以下是一些典型的应用场景:
- 边缘计算 :在物联网设备、智能手机和嵌入式系统等边缘设备上部署神经网络加速器,可以实现实时的人脸识别、语音识别、图像处理和物体检测等功能。这不仅可以提高设备的智能化水平,还可以减少对云服务器的依赖和延迟。
- 自动驾驶 :自动驾驶汽车需要实时处理大量的传感器数据,包括摄像头图像、雷达信号和激光雷达点云等。神经网络加速器可以显著提高这些数据的处理速度和准确性,为自动驾驶汽车提供可靠的感知和决策能力。
- 数据中心 :在数据中心中部署高性能的神经网络加速器,可以加速大规模神经网络模型的训练和推理过程。这不仅可以提高数据中心的计算能力和效率,还可以为人工智能应用提供更加快速和准确的服务。
- 医疗健康 :神经网络加速器在医疗健康领域的应用也非常广泛。例如,可以用于医学影像的自动分析和诊断、基因序列的快速比对和解析、以及药物研发的模拟和预测等方面。
综上所述,神经网络加速器作为深度学习技术的重要支撑,其发展和应用前景十分广阔。通过不断优化硬件架构、算法实现和应用场景,我们可以期待神经网络加速器在更多领域发挥重要作用,推动人工智能技术的进一步发展和普及。
-
处理器
+关注
关注
68文章
19155浏览量
229035 -
加速器
+关注
关注
2文章
795浏览量
37739 -
神经网络
+关注
关注
42文章
4762浏览量
100517
发布评论请先 登录
相关推荐
PowerVR Series2NX神经网络加速器设计
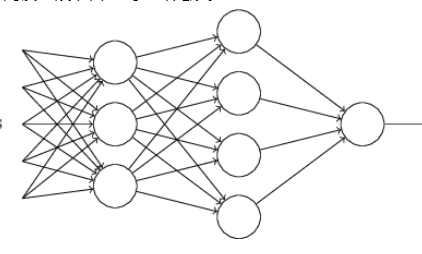
张量计算在神经网络加速器中的实现形式
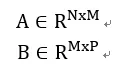
神经网络教程(李亚非)
【书籍评测活动NO.18】 AI加速器架构设计与实现
《 AI加速器架构设计与实现》+第一章卷积神经网络观后感
《 AI加速器架构设计与实现》+学习和一些思考
PowerVR与神经网络加速器





 工商网监
工商网监
评论