 BP神经网络样本的获取方法
BP神经网络样本的获取方法

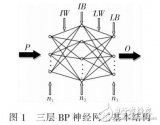
BP神经网络(Backpropagation Neural Network)是一种基于误差反向传播算法的多层前馈神经网络,广泛应用于模式识别、分类、预测等领域。在构建BP神经网络模型之前,获取高质量的训练样本是至关重要的。
- 数据收集
数据收集是构建BP神经网络模型的第一步。根据研究领域和应用场景的不同,数据来源可以分为以下几种:
1.1 实验数据:通过实验或观察获得的数据,如生物实验、化学实验等。
1.2 传感器数据:通过传感器收集的数据,如温度、湿度、压力等。
1.3 网络数据:从互联网上收集的数据,如文本、图片、视频等。
1.4 公共数据集:使用公开的数据集,如UCI机器学习库、Kaggle竞赛数据等。
1.5 专家知识:根据专家的经验或知识构建的数据。
在选择数据来源时,需要考虑数据的质量和数量。高质量的数据可以提高模型的准确性和泛化能力,而足够的数据量可以避免过拟合。
- 数据预处理
数据预处理是将原始数据转换为适合BP神经网络训练的格式。数据预处理的步骤包括:
2.1 数据清洗:去除数据中的噪声、异常值和缺失值。
2.2 数据标准化:将数据缩放到一个统一的范围,如[0, 1]或[-1, 1]。常用的标准化方法有最小-最大标准化、Z分数标准化等。
2.3 数据归一化:将数据转换为具有相同方差的分布,如高斯分布。常用的归一化方法有对数变换、Box-Cox变换等。
2.4 数据离散化:将连续数据转换为离散数据,以适应神经网络的离散性。
2.5 数据编码:将非数值数据(如文本、图像)转换为数值数据。常用的编码方法有独热编码、词嵌入等。
- 特征选择
特征选择是从原始数据中选择对模型预测最有用的特征。特征选择的方法包括:
3.1 过滤方法:根据特征的统计特性(如方差、相关性)进行选择。
3.2 包装方法:使用模型(如决策树、随机森林)评估特征的重要性。
3.3 嵌入方法:在模型训练过程中自动进行特征选择。
3.4 降维方法:使用主成分分析(PCA)、线性判别分析(LDA)等方法降低数据的维度。
- 数据增强
数据增强是通过生成新的训练样本来增加数据集的多样性,提高模型的泛化能力。数据增强的方法包括:
4.1 旋转、平移、缩放等几何变换。
4.2 颜色变换、亮度调整等图像处理方法。
4.3 随机噪声、缺失值等数据扰动。
4.4 对比样本、合成样本等样本生成方法。
- 样本划分
将收集到的数据划分为训练集、验证集和测试集。训练集用于模型的训练,验证集用于模型的调参和正则化,测试集用于评估模型的性能。通常,训练集占总数据的70%,验证集占15%,测试集占15%。
- 样本平衡
在某些情况下,数据集中的类别分布可能是不平衡的,即某些类别的样本数量远多于其他类别。这可能导致模型对多数类过于敏感,而忽略少数类。为了解决这个问题,可以采用以下方法:
6.1 重采样:通过增加少数类的样本数量或减少多数类的样本数量来平衡数据集。
6.2 权重调整:为不同类别的样本分配不同的权重,使模型在训练过程中更加关注少数类。
6.3 合成样本:使用SMOTE(Synthetic Minority Over-sampling Technique)等方法生成新的少数类样本。
- 样本评估
在模型训练过程中,需要定期对样本进行评估,以监控模型的性能。常用的评估指标包括:
7.1 准确率(Accuracy):正确预测的样本数占总样本数的比例。
7.2 精确率(Precision):正确预测为正的样本数占预测为正的样本数的比例。
7.3 召回率(Recall):正确预测为正的样本数占实际为正的样本数的比例。
7.4 F1分数(F1 Score):精确率和召回率的调和平均值。
7.5 混淆矩阵(Confusion Matrix):展示模型预测结果与实际标签之间的关系。
-
传感器
+关注
关注
2578文章
55811浏览量
795379 -
数据
+关注
关注
8文章
7363浏览量
95157 -
BP神经网络
+关注
关注
2文章
127浏览量
31690 -
机器学习
+关注
关注
67文章
8570浏览量
137420
发布评论请先 登录
labview BP神经网络的实现
基于BP神经网络的手势识别系统
基于BP神经网络的PID控制
基于BP神经网络的小麦病害诊断知识获取
BP神经网络风速预测方法
BP神经网络概述




评论