 人工神经元模型的三要素是什么
人工神经元模型的三要素是什么
人工神经元模型是人工智能和机器学习领域中非常重要的概念之一。它模仿了生物神经元的工作方式,通过数学和算法来实现对数据的处理和学习。
一、人工神经元模型的基本概念
1.1 生物神经元与人工神经元
生物神经元是构成神经系统的基本单元,它们通过突触与其他神经元相互连接,实现信息的传递和处理。人工神经元则是模仿生物神经元的一种数学模型,它通过数学和算法来实现对数据的处理和学习。
1.2 人工神经元模型的发展
人工神经元模型的发展可以追溯到20世纪40年代,当时科学家们开始尝试使用数学模型来模拟生物神经元的工作方式。随着计算机技术的发展,人工神经元模型逐渐成为人工智能和机器学习领域中的重要工具。
1.3 人工神经元模型的应用
人工神经元模型在许多领域都有广泛的应用,包括图像识别、语音识别、自然语言处理、推荐系统等。通过训练人工神经元模型,我们可以自动识别和处理大量的数据,从而实现智能化的决策和预测。
二、人工神经元模型的三要素
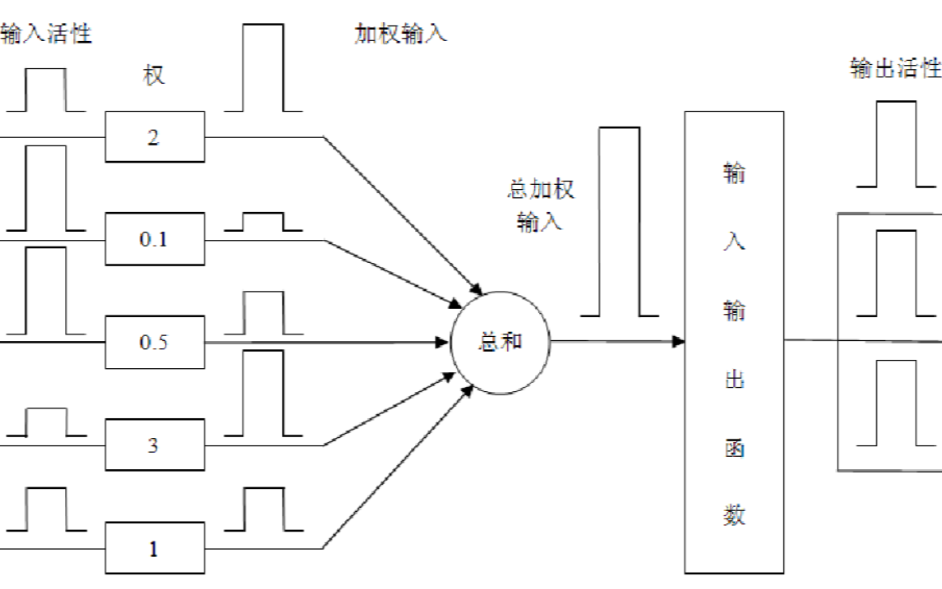
2.1 权重
权重是人工神经元模型中非常重要的一个概念,它代表了神经元之间的连接强度。在人工神经元模型中,每个神经元都与其他神经元相连,权重决定了这些连接的强度。权重的值可以是正数或负数,正数表示激活作用,负数表示抑制作用。
权重的设置对人工神经元模型的性能有很大的影响。在训练过程中,我们通过调整权重的值来优化模型的性能。权重的调整通常采用梯度下降算法,通过计算损失函数的梯度来更新权重。
2.2 激活函数
激活函数是人工神经元模型中的另一个关键要素,它决定了神经元的输出。激活函数通常是一个非线性函数,它可以将神经元的输入线性组合转换为非线性输出。常见的激活函数包括Sigmoid函数、Tanh函数、ReLU函数等。
激活函数的选择对人工神经元模型的性能有很大的影响。不同的激活函数具有不同的特点,例如Sigmoid函数具有平滑的曲线和良好的收敛性,但容易出现梯度消失的问题;ReLU函数具有计算简单和收敛速度快的优点,但容易出现梯度爆炸的问题。
2.3 损失函数
损失函数是评估人工神经元模型性能的一个重要指标,它衡量了模型预测值与实际值之间的差异。损失函数的选择对模型的训练和优化有很大的影响。常见的损失函数包括均方误差损失、交叉熵损失、Hinge损失等。
损失函数的计算通常涉及到模型的预测值和实际值,以及模型的参数。在训练过程中,我们通过最小化损失函数来优化模型的参数,从而提高模型的预测性能。
三、人工神经元模型的训练过程
3.1 数据预处理
在训练人工神经元模型之前,我们需要对数据进行预处理,包括数据清洗、特征选择、特征缩放等。数据预处理的目的是提高模型的训练效率和预测性能。
3.2 模型初始化
模型初始化是训练人工神经元模型的第一步,我们需要为模型设置初始的权重和偏置。权重和偏置的初始化方法有很多,例如随机初始化、零初始化等。合理的初始化方法可以提高模型的训练效率和预测性能。
3.3 前向传播
前向传播是计算模型输出的过程,它包括输入数据的线性组合、激活函数的计算等。在前向传播过程中,我们可以得到模型的预测值。
3.4 损失计算
损失计算是评估模型性能的过程,它通过计算损失函数来衡量模型预测值与实际值之间的差异。在损失计算过程中,我们可以得到模型的损失值。
3.5 反向传播
反向传播是优化模型参数的过程,它通过计算损失函数的梯度来更新模型的权重和偏置。在反向传播过程中,我们可以使用梯度下降算法、随机梯度下降算法等来调整模型的参数。
3.6 模型评估
模型评估是检验模型性能的过程,它通过计算模型在测试集上的损失和准确率等指标来评估模型的预测性能。在模型评估过程中,我们可以使用交叉验证、混淆矩阵等方法来评估模型的性能。
四、人工神经元模型的优化方法
4.1 正则化
正则化是一种防止模型过拟合的方法,它通过在损失函数中添加正则项来限制模型的复杂度。常见的正则化方法包括L1正则化、L2正则化等。
4.2 Dropout
Dropout是一种防止模型过拟合的方法,它通过在训练过程中随机丢弃一些神经元来增加模型的鲁棒性。Dropout可以有效地减少模型对训练数据的依赖,提高模型的泛化能力。
-
人工智能
+关注
关注
1800文章
48064浏览量
242053 -
模型
+关注
关注
1文章
3410浏览量
49465 -
机器学习
+关注
关注
66文章
8460浏览量
133400 -
人工神经元
+关注
关注
0文章
11浏览量
6327
发布评论请先 登录
相关推荐
基于非联合型学习机制的学习神经元模型
神经网络与神经网络控制的学习课件免费下载
一种具有高度柔性与可塑性的超香肠覆盖式神经元模型





 工商网监
工商网监
评论