 使用NumPy实现前馈神经网络
使用NumPy实现前馈神经网络
要使用NumPy实现一个前馈神经网络(Feedforward Neural Network),我们需要从基础开始构建,包括初始化网络参数、定义激活函数及其导数、实现前向传播、计算损失函数、以及实现反向传播算法来更新网络权重和偏置。这里,我将详细介绍一个包含单个隐藏层的前馈神经网络的实现。
一、引言
前馈神经网络是一种最基础的神经网络结构,其中信息只向前传播,不形成循环。它通常由输入层、若干隐藏层(至少一层)和输出层组成。在这个实现中,我们将构建一个具有一个隐藏层的前馈神经网络,用于解决二分类问题。
二、准备工作
首先,我们需要导入NumPy库,并定义一些基本的函数,如激活函数及其导数。
import numpy as np
def sigmoid(x):
"""Sigmoid激活函数"""
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
"""Sigmoid激活函数的导数"""
return x * (1 - x)
def mse_loss(y_true, y_pred):
"""均方误差损失函数"""
return np.mean((y_true - y_pred) ** 2)
三、网络结构定义
接下来,我们定义网络的结构,包括输入层、隐藏层和输出层的节点数。
input_size = 3 # 输入层节点数
hidden_size = 4 # 隐藏层节点数
output_size = 1 # 输出层节点数
# 初始化权重和偏置
np.random.seed(0) # 为了可重复性设置随机种子
weights_input_to_hidden = np.random.randn(input_size, hidden_size) * 0.01
bias_hidden = np.zeros((1, hidden_size))
weights_hidden_to_output = np.random.randn(hidden_size, output_size) * 0.01
bias_output = np.zeros((1, output_size))
四、前向传播
前向传播涉及将输入数据通过网络传播到输出层。
def forward_pass(X):
# 输入层到隐藏层
hidden_layer_input = np.dot(X, weights_input_to_hidden) + bias_hidden
hidden_layer_output = sigmoid(hidden_layer_input)
# 隐藏层到输出层
output_layer_input = np.dot(hidden_layer_output, weights_hidden_to_output) + bias_output
output_layer_output = sigmoid(output_layer_input)
return output_layer_output
五、反向传播
反向传播用于计算损失函数关于网络参数的梯度,并据此更新这些参数。
def backward_pass(X, y_true, y_pred):
# 输出层梯度
d_output = y_pred - y_true
d_output_wrt_output_input = sigmoid_derivative(y_pred)
d_hidden_to_output = d_output * d_output_wrt_output_input
# 更新输出层权重和偏置
grad_weights_hidden_to_output = np.dot(hidden_layer_output.T, d_hidden_to_output)
grad_bias_output = np.sum(d_hidden_to_output, axis=0, keepdims=True)
# 隐藏层梯度
d_hidden = np.dot(d_hidden_to_output, weights_hidden_to_output.T)
d_hidden_wrt_hidden_input = sigmoid_derivative(hidden_layer_output)
d_input_to_hidden = d_hidden * d_hidden_wrt_hidden_input
# 更新输入层到隐藏层的权重和偏置
grad_weights_input_to_hidden = np.dot(X.T, d_input_to_hidden)
grad_bias_hidden = np.sum(d_input_to_hidden, axis=0, keepdims=True)
return grad_weights_input_to_hidden, grad_bias_hidden, grad_weights_hidden_to_output, grad_bias_output
def update_parameters(def update_parameters(learning_rate, grad_weights_input_to_hidden, grad_bias_hidden, grad_weights_hidden_to_output, grad_bias_output):
"""
根据梯度更新网络的权重和偏置。
Parameters:
- learning_rate: 浮点数,学习率。
- grad_weights_input_to_hidden: 输入层到隐藏层的权重梯度。
- grad_bias_hidden: 隐藏层的偏置梯度。
- grad_weights_hidden_to_output: 隐藏层到输出层的权重梯度。
- grad_bias_output: 输出层的偏置梯度。
"""
global weights_input_to_hidden, bias_hidden, weights_hidden_to_output, bias_output
weights_input_to_hidden -= learning_rate * grad_weights_input_to_hidden
bias_hidden -= learning_rate * grad_bias_hidden
weights_hidden_to_output -= learning_rate * grad_weights_hidden_to_output
bias_output -= learning_rate * grad_bias_output
# 示例数据
X = np.array([[0.1, 0.2, 0.3], [0.4, 0.5, 0.6], [0.7, 0.8, 0.9]]) # 示例输入
y_true = np.array([[0], [1], [0]]) # 示例真实输出(二分类问题,使用0和1表示)
# 训练过程
epochs = 10000 # 训练轮次
learning_rate = 0.1 # 学习率
for epoch in range(epochs):
# 前向传播
y_pred = forward_pass(X)
# 计算损失
loss = mse_loss(y_true, y_pred)
# 如果需要,可以在这里打印损失值以监控训练过程
if epoch % 1000 == 0:
print(f'Epoch {epoch}, Loss: {loss}')
# 反向传播
grad_weights_input_to_hidden, grad_bias_hidden, grad_weights_hidden_to_output, grad_bias_output = backward_pass(X, y_true, y_pred)
# 更新参数
update_parameters(learning_rate, grad_weights_input_to_hidden, grad_bias_hidden, grad_weights_hidden_to_output, grad_bias_output)
# 训练结束后,可以使用训练好的网络进行预测
# ...
六、评估与预测
在上面的代码中,我们仅打印了训练过程中的损失值来监控训练过程。在实际应用中,你还需要在训练结束后对模型进行评估,并使用它来对新数据进行预测。评估通常涉及在一个与训练集独立的测试集上计算模型的性能指标,如准确率、召回率、F1分数等。
七、扩展与改进
- 增加隐藏层 :可以通过增加更多的隐藏层来扩展网络,构建更深的神经网络。
- 使用不同的激活函数 :除了Sigmoid外,还可以使用ReLU、Tanh等激活函数,它们在不同的应用场景中可能表现更好。
- 引入正则化 :为了防止过拟合,可以在损失函数中加入正则化项,如L1正则化、L2正则化或Dropout(虽然在这里我们手动实现了网络,但NumPy本身不提供内置的Dropout支持,通常需要使用其他库如TensorFlow或PyTorch来实现)。
- 优化算法 :除了基本的梯度下降法外,还可以使用更高效的优化算法,如Adam、RMSprop等。
- 批处理与数据增强 :为了进一步提高模型的泛化能力,可以使用批处理来加速训练过程,并使用数据增强技术来增加训练数据的多样性。
八、结论
通过上面的介绍,我们了解了如何使用NumPy从头开始实现一个具有单个隐藏层的前馈神经网络。虽然这个实现相对简单,但它为理解更复杂的深度学习模型和框架(如TensorFlow和PyTorch)奠定了基础。在实际应用中,我们通常会使用这些框架来构建和训练神经网络,因为它们提供了更多的功能和优化。然而,了解底层的实现原理对于深入理解深度学习仍然是非常重要的。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
神经网络
+关注
关注
42文章
4779浏览量
101139 -
函数
+关注
关注
3文章
4345浏览量
62946
发布评论请先 登录
相关推荐
基于递归神经网络和前馈神经网络的深度学习预测算法
蛋白质二级结构预测是结构生物学中的一个重要问题。针对八类蛋白质二级结构预测,提出了一种基于递归神经网络和前馈神经网络的深度学习预测算法。该算法通过双向递归
发表于 12-03 09:41
•9次下载
基于Numpy实现同态加密神经网络
在分布式AI环境下,同态加密神经网络有助于保护商业公司知识产权和消费者隐私。本文介绍了如何基于Numpy实现同态加密神经网络。
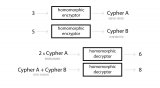
基于Numpy实现神经网络:反向传播
和DeepMind数据科学家、Udacity深度学习导师Andrew Trask一起,基于Numpy手写神经网络,更深刻地理解反向传播这一概念。

BP神经网络概述
BP 神经网络是一类基于误差逆向传播 (BackPropagation, 简称 BP) 算法的多层前馈神经网络,BP算法是迄今最成功的神经网络

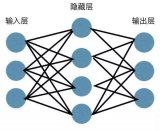
bp神经网络是前馈还是反馈
BP神经网络,即反向传播(Backpropagation)神经网络,是一种前馈神经网络(Feedforward Neural Network
前馈神经网络的工作原理和应用
前馈神经网络(Feedforward Neural Network, FNN),作为最基本且应用广泛的一种人工神经网络模型,其工作原理和结构对于理解深度学习及人工智能领域至关重要。本文
深度神经网络中的前馈过程
深度神经网络(Deep Neural Networks,DNNs)中的前馈过程是其核心操作之一,它描述了数据从输入层通过隐藏层最终到达输出层的过程,期间不涉及任何反向传播或权重调整。这一过程是
全连接前馈神经网络与前馈神经网络的比较
Neural Network, FCNN)和前馈神经网络(Feedforward Neural Network, FNN)因其结构简单、易于理解和实现,成为了研究者们关注的热点。本文
前馈神经网络的基本结构和常见激活函数
前馈神经网络(Feedforward Neural Network, FNN)是人工神经网络中最基本且广泛应用的一种结构,其结构简单、易于理解,是深度学习领域中的基石。FNN通过多层节





 工商网监
工商网监
评论