 读写分离怎么保证数据同步
读写分离怎么保证数据同步
读写分离是一种常见的数据库架构设计,用于提高数据库的并发处理能力。在读写分离架构中,数据库的读操作和写操作被分离到不同的服务器上,从而实现负载均衡和性能优化。然而,读写分离也带来了数据同步的问题。如果数据同步不能得到有效保证,可能会导致数据不一致,影响业务的正常运行。
一、读写分离中的数据同步问题
- 写操作的延迟同步
在读写分离架构中,写操作通常由主服务器(Master)完成,而读操作则由从服务器(Slave)完成。为了保证数据的一致性,主服务器需要将写操作的数据同步到从服务器。然而,由于网络延迟、服务器性能等因素,写操作的数据同步可能会有一定的延迟。如果在这个延迟期间,用户读取了从服务器的数据,就可能读取到旧的数据,导致数据不一致。
- 从服务器的复制延迟
在读写分离架构中,从服务器需要实时复制主服务器的数据。然而,由于网络延迟、服务器性能等因素,从服务器的复制可能会有一定的延迟。如果在这个延迟期间,主服务器发生了数据变更,而从服务器还没有复制到最新的数据,就可能导致数据不一致。
- 主从服务器的数据不一致
在读写分离架构中,主服务器和从服务器的数据同步是通过复制实现的。然而,由于复制过程中可能出现的错误、冲突等问题,主从服务器的数据可能会出现不一致的情况。如果这种不一致的数据被用户读取,就可能导致业务逻辑错误,影响业务的正常运行。
二、保证数据同步的策略和方法
- 选择合适的同步方式
为了保证数据同步,需要选择合适的同步方式。常见的同步方式有:
(1)异步复制:主服务器在完成写操作后,立即返回结果,不等待从服务器的同步完成。这种方式的优点是写性能高,但缺点是数据同步有一定的延迟。
(2)半同步复制:主服务器在完成写操作后,等待至少一个从服务器同步完成,再返回结果。这种方式的优点是数据同步的延迟较小,但缺点是写性能略有下降。
(3)强同步复制:主服务器在完成写操作后,等待所有从服务器同步完成,再返回结果。这种方式的优点是数据同步的一致性高,但缺点是写性能较低。
根据业务需求和性能要求,可以选择不同的同步方式。
- 优化网络和服务器性能
为了减少数据同步的延迟,可以优化网络和服务器性能。具体措施包括:
(1)使用高速网络:使用高速的网络设备和线路,减少数据传输的时间。
(2)使用高性能服务器:使用高性能的服务器硬件,提高数据处理的速度。
(3)优化服务器配置:根据业务需求,合理配置服务器的内存、CPU、磁盘等资源,提高服务器的处理能力。
- 使用分布式锁
在读写分离架构中,为了保证数据的一致性,可以使用分布式锁。分布式锁可以保证在同一个时间点,只有一个服务器能够执行写操作,从而避免数据冲突和不一致的问题。
具体实现方法包括:
(1)基于Redis的分布式锁:使用Redis的原子操作命令,实现分布式锁的功能。
(2)基于ZooKeeper的分布式锁:使用ZooKeeper的节点创建和删除机制,实现分布式锁的功能。
(3)基于Etcd的分布式锁:使用Etcd的键值存储和事务机制,实现分布式锁的功能。
- 使用事务隔离级别
为了保证数据的一致性,可以使用事务隔离级别。事务隔离级别可以控制事务的可见性和并发性,从而避免数据冲突和不一致的问题。
常见的事务隔离级别包括:
(1)读未提交(Read Uncommitted):允许读取未提交的数据,可能会导致脏读。
(2)读已提交(Read Committed):只允许读取已提交的数据,可以避免脏读,但可能会出现不可重复读的问题。
(3)可重复读(Repeatable Read):在一个事务中,多次读取同一数据的结果是一致的,可以避免不可重复读的问题,但可能会出现幻读的问题。
(4)串行化(Serializable):最高的隔离级别,可以避免脏读、不可重复读和幻读的问题,但性能较低。
根据业务需求和性能要求,可以选择不同的事务隔离级别。
- 使用数据一致性检查工具
为了保证数据的一致性,可以使用数据一致性检查工具。这些工具可以定期检查主从服务器的数据是否一致,如果发现不一致的情况,可以及时进行修复。
常见的数据一致性检查工具包括:
(1)Percona Toolkit:一套开源的MySQL工具集,包括数据一致性检查工具。
(2)Tungsten Replicator:一个基于MySQL的复制工具,支持数据一致性检查。
(3)Maxwell's Daemon:一个基于MySQL的复制工具,支持数据一致性检查。
-
数据
+关注
关注
8文章
6888浏览量
88825 -
服务器
+关注
关注
12文章
9017浏览量
85182 -
数据库
+关注
关注
7文章
3763浏览量
64274
发布评论请先 登录
相关推荐
一文解析Redis读写分离技术
mysql数据库同步原理
ddr3的读写分离方法有哪些?
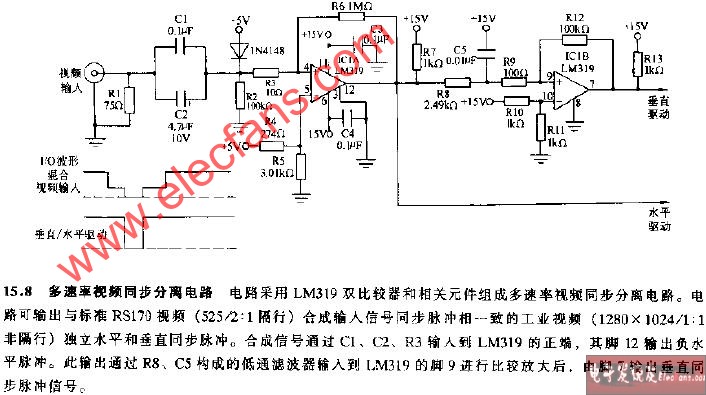
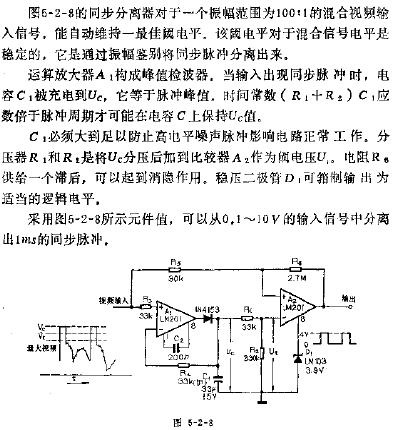
同步分离电路分析
读写分离的两种实现方式
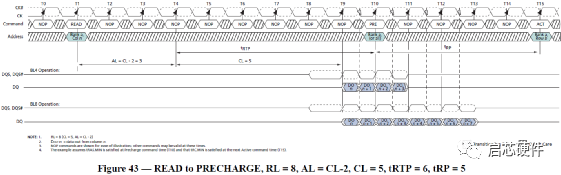
阐述DDR3读写分离的方法





 工商网监
工商网监
评论