 在Dify中使用PerfXCloud大模型推理服务
在Dify中使用PerfXCloud大模型推理服务
近日,Dify全面接入了Perf XCloud,借助Perf XCloud提供的大模型调用服务,用户可在Dify中构建出更加经济、高效的LLM应用。
PerfXCloud 介绍
Perf XCloud是澎峰科技为开发者和企业量身打造的AI开发和部署平台。专注于满足大模型的微调和推理需求,为用户提供极致便捷的一键部署体验:
◦平台提供Open AI API兼容的模型调用服务,开发者可实现已有应用的快速迁移。
◦借助澎峰科技自研推理框架PerfXLM,Perf XCloud实现了主流模型在国产算力上的广泛适配和高效推理。
◦目前已支持Qwen2系列、llama3系列、bge-m3等模型,更多模型即将上线。
同时,Perf XCloud为算力中心提供大模型AI科学与工程计算的整体运营解决方案,助力算力中心升级成为“AI超级工厂”。
Dify介绍
Dify是一个开源的LLM应用开发平台。其直观的界面结合了AI工作流、RAG Pipeline、Agent、模型管理、可观测性功能等,让您可以快速从原型到生产:
◦工作流:在画布上构建和测试功能强大的AI工作流程。
◦RAG Pipeline:广泛的RAG功能,涵盖从文档摄入到检索的所有内容,支持从PDF、PPT和其他常见文档格式中提取文本的开箱即用的支持。
◦Agent智能体:您可以基于LLM函数调用或ReAct定义Agent,并为 Agent添加预构建或自定义工具。
◦LLMOps:随时间监视和分析应用程序日志和性能。您可以根据生产数据和标注持续改进提示、数据集和模型。
注册使用PerfXCloud
Perf XCloud注册地址:www.perfxcloud.net
现在注册,即可深度体验主流大模型,提供大量示范案例,手把手视频教学。并可参与向基石用户赠送∞亿Token的激励计划。
在Dify中使用PerfXCloud大模型推理服务
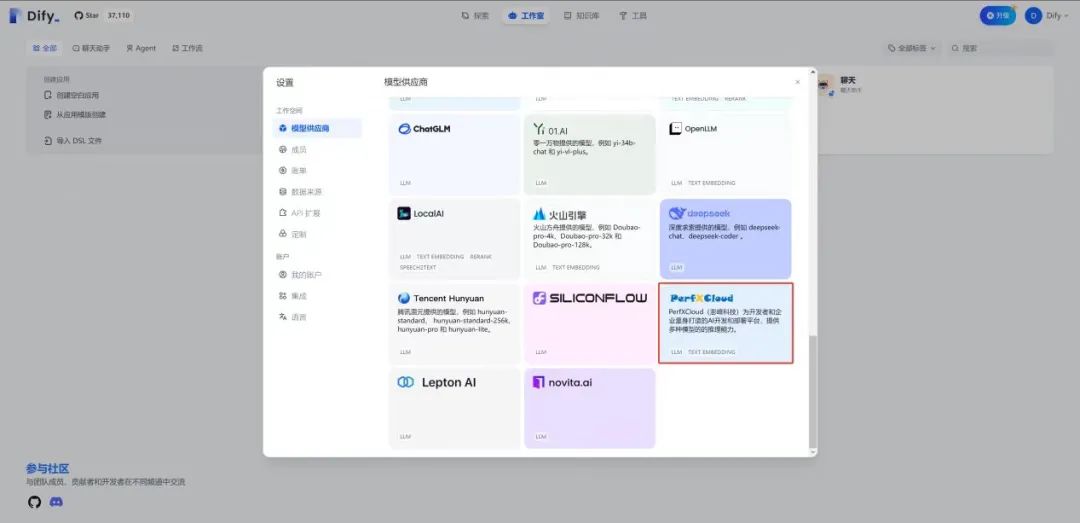
1.首先进入Dify设置页面,选择Perf XCloud作为模型供应商:
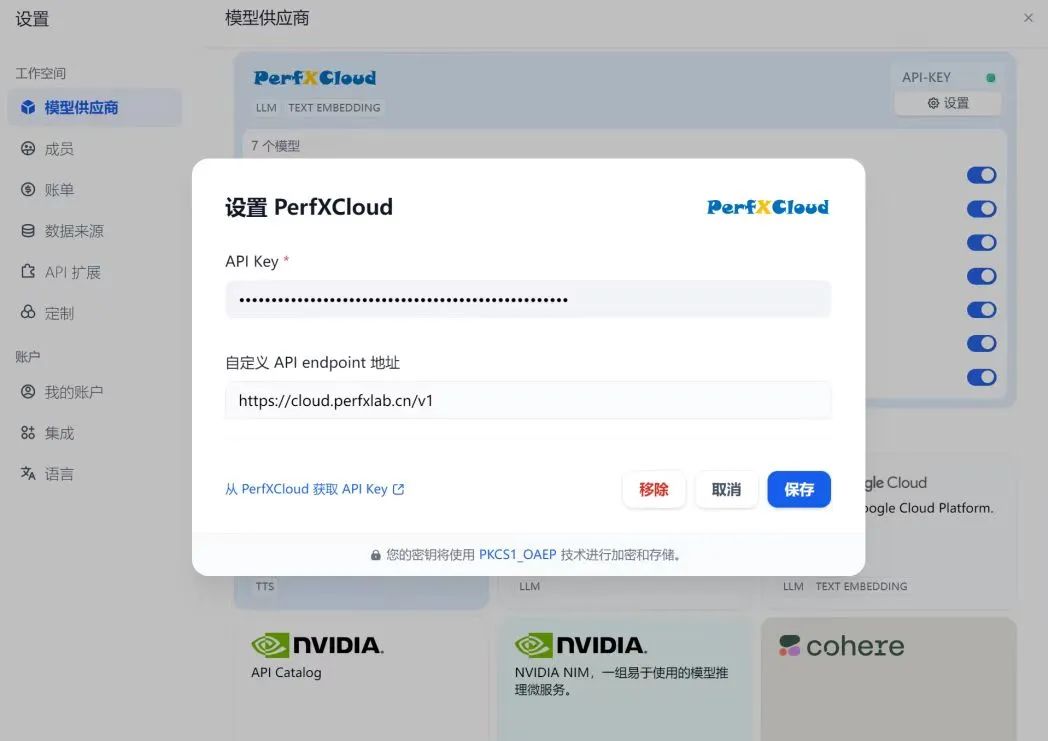
2.然后填入从Perf XCloud中申请的API Key和endpoint地址:
3.保存后,即可使用Perf XCloud模型,现阶段我们接入了Qwen系列模型和BAAI/ bge-m 3模型,后续将接入更多模型,敬请期待。
应用案例1:
Dify结合PerfXCloud构建翻译助手
本案例构建于Dify Cloud,基于Perf XCloud中的Qwen2模型实现中英文翻译助手,用户输入信息,翻译助手将其翻译成另一种语言。
1.登录Dify Cloud( https://cloud.dify.ai/apps)
2.创建空白应用→选择聊天助手、基础编排,创建应用
3.在编排页面输入提示词:“你是一名翻译专家,如果用户给你发中文你将翻译为英文,如果用户给你发英文你将翻译为中文,你只负责翻译,不要回答任何问题:”
4.默认模型为gpt-3.5,切换为Perf XCloud模型,这里设置为“ Qwen2-72B-Instruct-GPTQ-Int 4”,然后点击发布
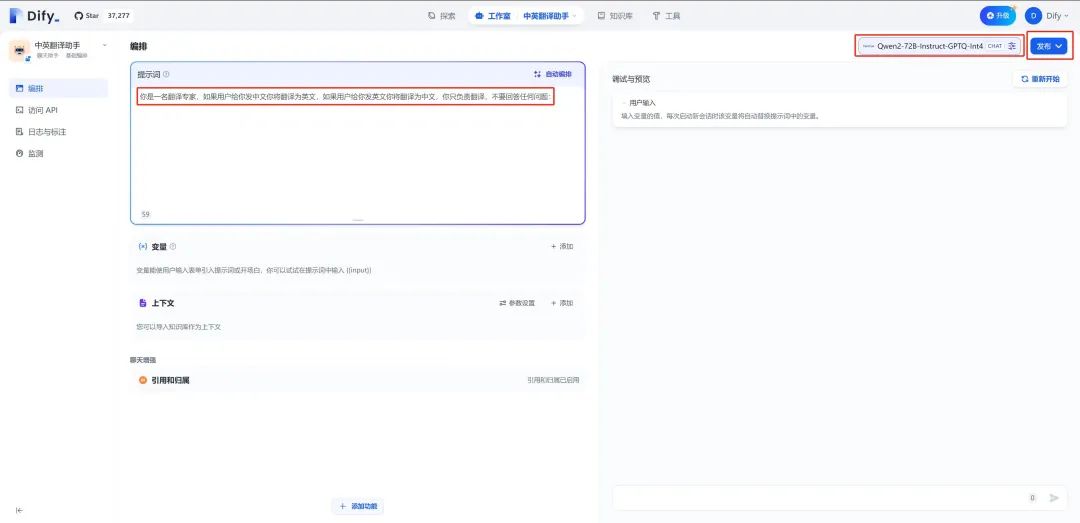
完成发布后, 即可运行使用。
应用案例2:
Dify结合PerfXCloud构建邮编查询助手
本案例构建与Dify Cloud,使用Dify中的知识库和工作流功能,结合Perf XCloud中的bge-m 3模型与Qwen2-72B-Instruct-GPTQ-Int 4模型,邮编查询助手基于上传的邮编信息构建知识库,并从中检索信息作为大模型回答问题的上下文,提高模型回答的准确性。
1.在Dify Cloud( https://cloud.dify.ai/datasets)中创建知识库,上传本地准备好的中国邮政编码数据文件。
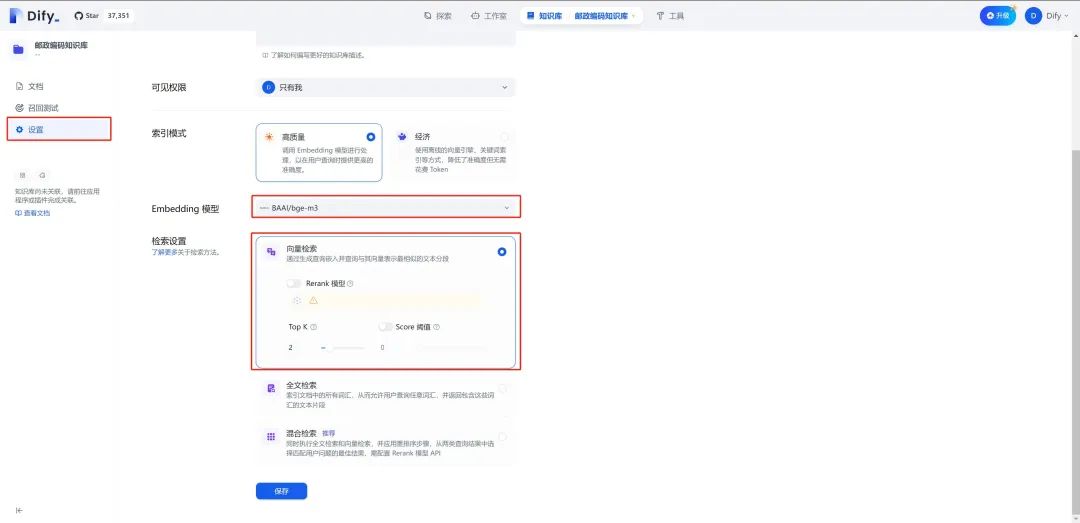
2.知识库默认使用经济模式创建索引,该模式是基于关键词的检索,这里我们使用Perf XCloud中的bge-m3向量模型创建索引,提高检索精度。在知识库侧边栏选择“设置”,设置“高质量”索引模式,同时Embedding模型选择“BAAI/bge-m 3”,使用“向量检索”
3.返回Dify工作室→创建空白应用→ 聊天助手→工作流编排,将工作流初始化成如下形式
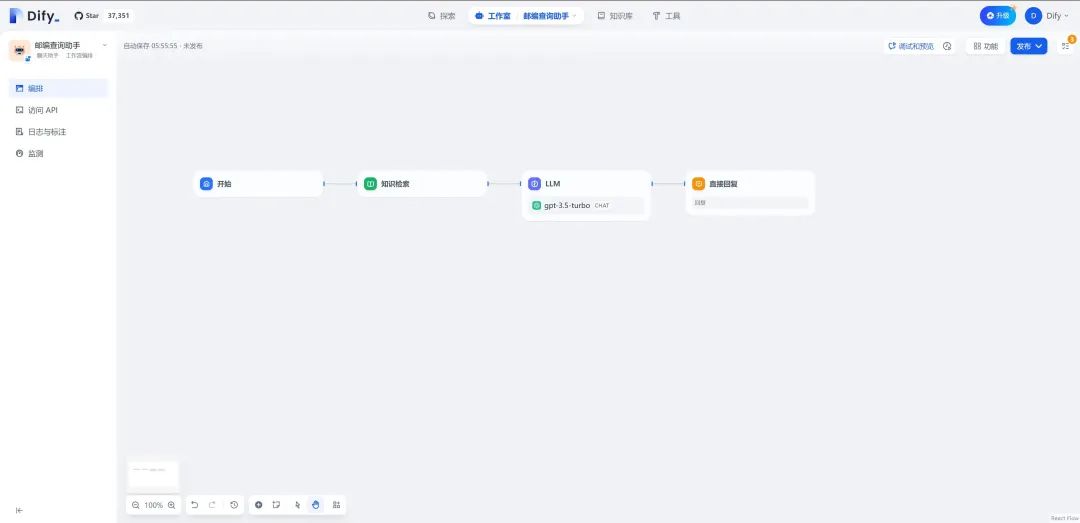
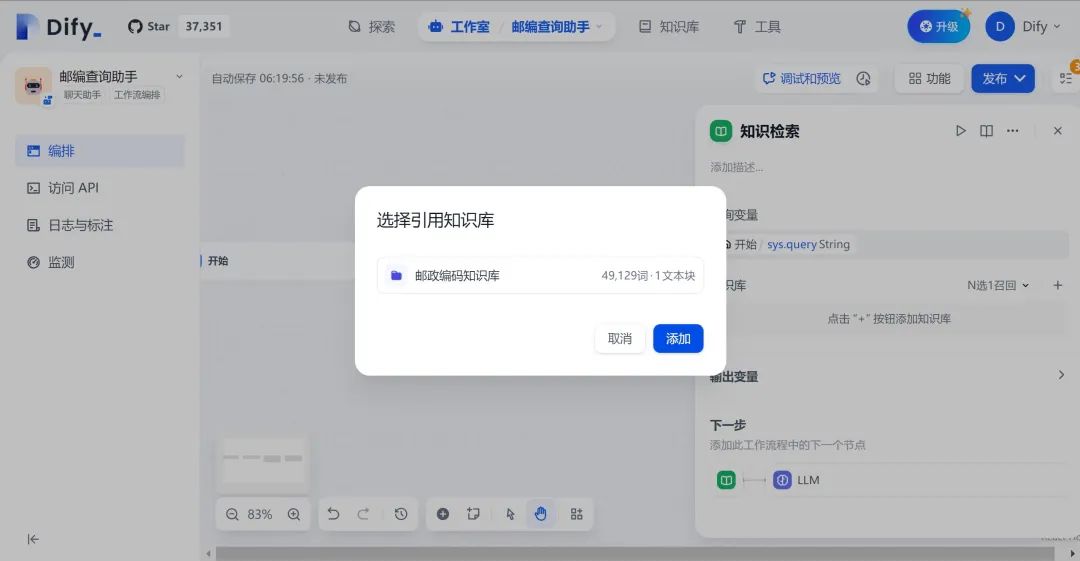
4.配置“知识检索”模块,将知识库设置为步骤2中创建的“邮政编码知识库”
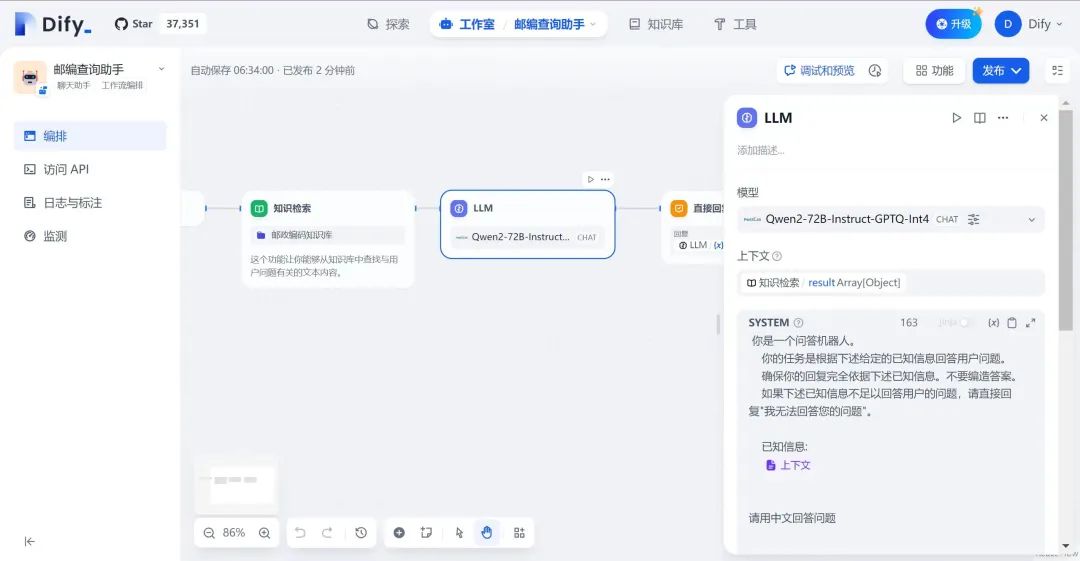
5.配置“LLM”模块,将模型设置为Perf XCloud中Qwen2-72B-Instruct-GPTQ-Int 4,并设置prompt:
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
确保你的回复完全依据下述已知信息。不要编造答案。
如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
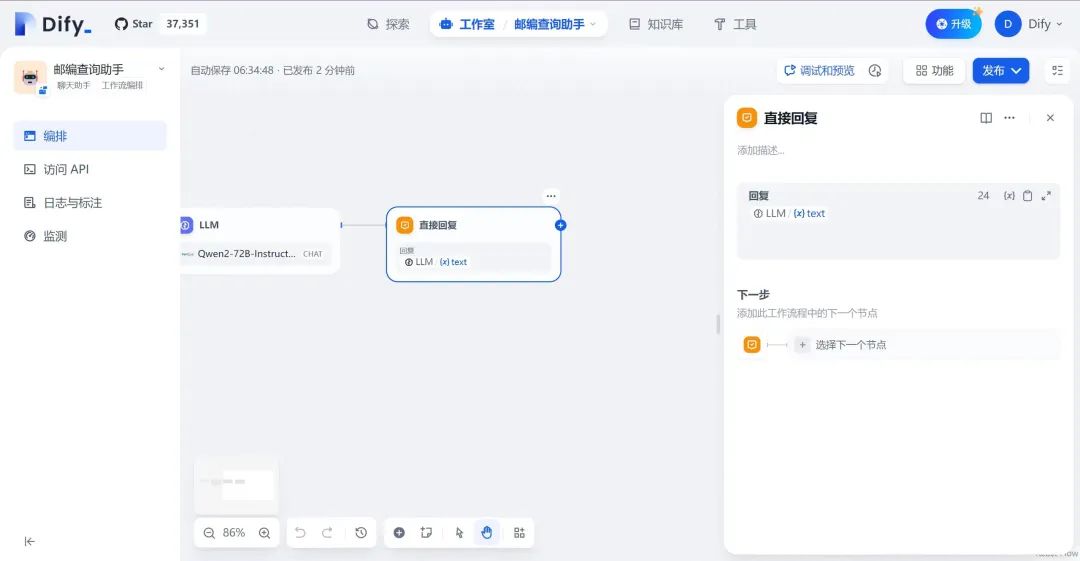
6.配置“直接回复” 模块,直接输出LLM的生成结果
7.完成上述步骤后,运行查看效果,模型会根据知识库中检索出的信息进行回答,若检索结果为空,则直接输出“我无法回答您的问题”
-
AI
+关注
关注
87文章
32431浏览量
271592 -
澎峰科技
+关注
关注
0文章
67浏览量
3276 -
大模型
+关注
关注
2文章
2779浏览量
3432 -
LLM
+关注
关注
1文章
308浏览量
511
原文标题:借助PerfXCloud和Dify,低成本构建大模型应用
文章出处:【微信号:perfxlab,微信公众号:perfxlab】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
压缩模型会加速推理吗?
HarmonyOS:使用MindSpore Lite引擎进行模型推理
英伟达推出AI模型推理服务NVIDIA NIM
PerfXCloud-AI大模型夏日狂欢来袭,向基石用户赠送 ∞ 亿Token!
PerfXCloud大模型开发与部署平台开放注册
PerfXCloud大模型人工智能生态技术大会圆满落幕
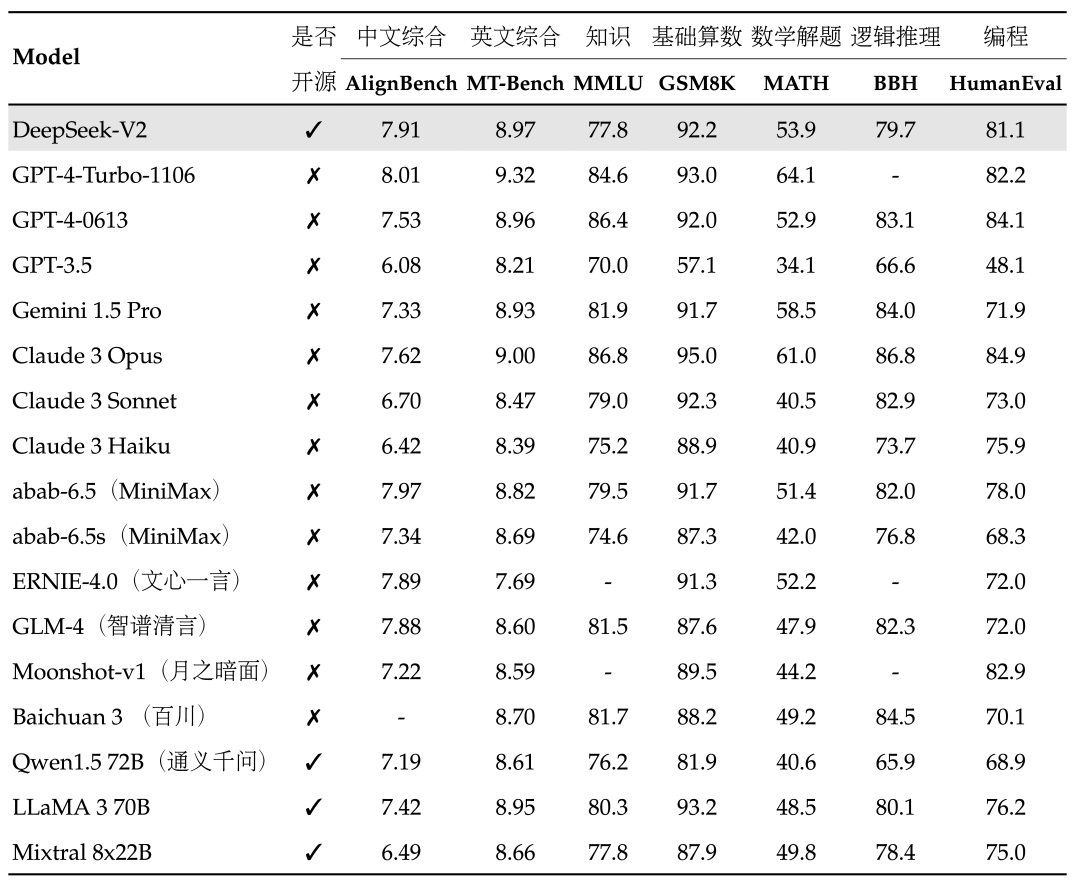
PerfXCloud顺利接入MOE大模型DeepSeek-V2
NVIDIA助力提供多样、灵活的模型选择
高效大模型的推理综述






 工商网监
工商网监
评论