 芯动力科技论文入选ISCA 2024,与国际巨头同台交流研究成果
芯动力科技论文入选ISCA 2024,与国际巨头同台交流研究成果
近日,珠海市芯动力科技有限公司团队携手帝国理工、剑桥大学、清华大学、中山大学等顶尖学府的计算机架构团队,共同撰写的论文《Circular Reconfigurable Parallel Processor for Edge Computing》(RPP芯片架构)成功被第51届计算机体系结构国际研讨会(ISCA 2024)的Industry Track收录。此外,我们荣幸地受邀在阿根廷布宜诺斯艾利斯举行的ISCA 2024会议上发表演讲,与Intel、AMD等国际知名企业同台交流。


本届ISCA共收到来自全球423篇高质量论文投稿,经过严谨的评审流程,仅有83篇论文脱颖而出,总体接收率低至19.6%。其中,Industry Track的录取难度尤为突出,接收率仅为15.3%。
作为计算机体系结构领域的顶级学术盛会,ISCA由ACM SIGARCH与IEEE TCCA联合举办,自1973年创办以来,始终是推动计算机系统结构领域进步的先锋力量。其广泛的影响力和卓越的贡献,使其成为谷歌、英特尔、英伟达等行业巨头竞相展示前沿研究成果的高端平台。ISCA与MICRO、HPCA、ASPLOS并称为四大顶级会议,而ISCA更是其中的佼佼者,论文录取率常年保持在18%左右。多年来,众多在ISCA上发表的研究成果已成为推动半导体和计算机行业发展的关键动力。
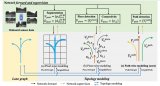
本次入选的论文提出了一款创新型可重构并行处理器(RPP),为边缘计算领域注入了强劲动力。RPP是并行处理器的设计,特别适宜应对大模型并行边缘计算的挑战。该设计允许程序指令在空间上展开,形成数据流经每个计算单元的流水线处理。这意味着无限长的代码可以被循环地放置在有限的处理单元中,通过循环使用gasket memory,实现任意长度的编程代码,而不需要编程人员了解底层的硬件细节。
为进一步提升RPP的实用性,研究团队还开创性地提出了一种近存计算,旨在满足不同应用对内存访问的多样化需求,有效减少数据在计算单元间的传输,从而显著降低功耗,提升计算效率。
为了发挥RPP的最大潜力,团队还开发了一套完整的软件堆栈,包括编译器、运行时环境及各类RPP库,且从指令级别兼容CUDA语言,为其广泛应用打下坚实基础。
实验结果充分证实,作为一款并行边缘计算的硬件平台,RPP的性能全面超越当前市场上的GPU,特别是在对延迟、功耗和体积有着极高要求的应用场景中表现尤为出色。
随着并行计算在计算机科学领域的日益崛起,RPP无疑为边缘计算的发展开辟了新的道路,我们有理由期待它在未来能够展现出更加耀眼的光芒。同时我们也期待在ISCA 2024上,芯动力团队能为全球计算机体系结构领域的研究和应用带来新的突破和启示。
审核编辑 黄宇
-
芯片
+关注
关注
455文章
50714浏览量
423115 -
计算机
+关注
关注
19文章
7488浏览量
87847 -
架构
+关注
关注
1文章
513浏览量
25468
发布评论请先 登录
相关推荐
软通动力入选新华社年度智能零碳成果展
广电计量入选2024商业航天与应用技术创新学术优秀成果
紫光国芯LPDDR4产品荣获“汽车芯片创新成果典型案例”
SynSense时识科技与海南大学联合研究成果发布

经纬恒润功能安全AI 智能体论文成功入选EMNLP 2024!

中移芯昇发布智能可信城市蜂窝物联网基础设施研究成果

软通动力受邀出席2024中国国际金融展
芯海科技亮相COMPUTEX 2024台北电脑展览会
云知声入选亿欧智库《2024北京国际车展展后洞察研究报告》
直击ISEDA 2024现场:思尔芯的EDA技术与教育并行

量子计算+光伏!本源研究成果入选2023年度“中国地理科学十大研究进展”

微纳核芯4项AIoT芯片成果入选ISSCC 2024
智芯公司所属杭州万高科技成果成功入选2024年度ISSCC






 工商网监
工商网监
评论