 数据中心的AI时代转型:挑战与机遇
数据中心的AI时代转型:挑战与机遇
来源:SDNLAB
随着人工智能(AI)的迅速发展和广泛应用,数据中心作为AI技术的基石,也面临着前所未有的挑战和机遇。为了满足AI的高性能和低延迟要求,数据中心基础设施必须进行相应的改变和升级。
01、基础设施的升级需求数十年来,企业一直在不断改变和升级基础设施,以适应新的应用程序和工作负载。人工智能工作负载通常需要专门的基础设施,随着人工智能的普及,这一过程依然持续。
最近发布的IDC全球半年度人工智能跟踪报告进一步证实:硬件支出在整个人工智能领域(包括服务和软件)中占比最小,但有望实现巨大增长。
与传统应用程序和工作负载相比,人工智能工作负载对计算和网络资源提出了全新的、独特的需求,涉及处理器、核心网络元素、功耗等多个方面的变革。当然,企业也曾通过升级计算基础设施,迁移到更快的处理器、更高性能的存储和更高速的互连技术来适应类似的变化。然而,当前情况与先前的升级有两个关键不同:首先,主体范围更广。过去为了运行更复杂应用程序而升级基础设施的公司主要是领先的大型企业。但大多数公司未受到直接影响,无需改变其基础设施。而在人工智能时代,各种规模的公司都积极尝试利用人工智能来优化运营、提升客户体验、增加收入等。其次,升级的必要性更强烈。当下,许多人工智能应用程序都是基于对来自不同内外部数据源的大量数据进行收集和分析。在大多数情况下,一旦企业缺乏适当的基础设施,就无法有效地将大量数据传输到其计算设施中。
多年来,企业一直通过采用更快的处理器、更高效的存储和更快速的互连技术来升级计算基础设施。例如,使用GPU和协同处理器来加速工作负载,采用并行分布式文件系统以提高存储性能,以及利用无限波段网络来加速存储和计算系统之间的数据传输等等。总体而言,采用新技术以满足日益增长的工作负载需求的趋势一直在演变,而随着人工智能的普及,这一趋势也在持续发展。
02、数据中心如何支持人工智能人工智能工作负载通常是数据和计算密集型的,数据中心提供安全、可扩展且可靠的基础设施,用于存储、处理和分析人工智能应用生成的大量数据。数据中心通过高性能计算 (HPC)、托管专用硬件、数据存储和网络来支持人工智能。高性能计算(HPC)AI的计算需求巨大,这主要是因为AI模型的训练和推理工作负载所需。为了满足这种需求,数据中心采用了高性能计算(HPC)集群来支撑AI应用和任务。这些HPC集群由一系列通过高速网络连接的服务器组成,使其能够实现并行处理和加速训练过程。在数据中心环境中,HPC系统通常都是按照标准的19英寸宽度设计的四柱机架形式。这种设计不仅适合各种服务器类型(如1U服务器、刀片服务器和存储设备),还具备了模块化和可扩展的特性,这使得它可以根据AI任务的需求进行灵活的扩展和升级。
考虑到机架的功率处理能力,它们的功率密度可以在20 kW至60 kW的范围内变化。以一个42U机架为例,如果每台1U服务器的功耗是500瓦,那么机架的总功率会达到21 kW。但如果这些服务器的功耗增加到1,430瓦,那么机架的总功率将增加到60 kW。相对地,某些低功耗服务器可能只需100瓦,这意味着42U机架上所有服务器的总功率只有4.2 kW。
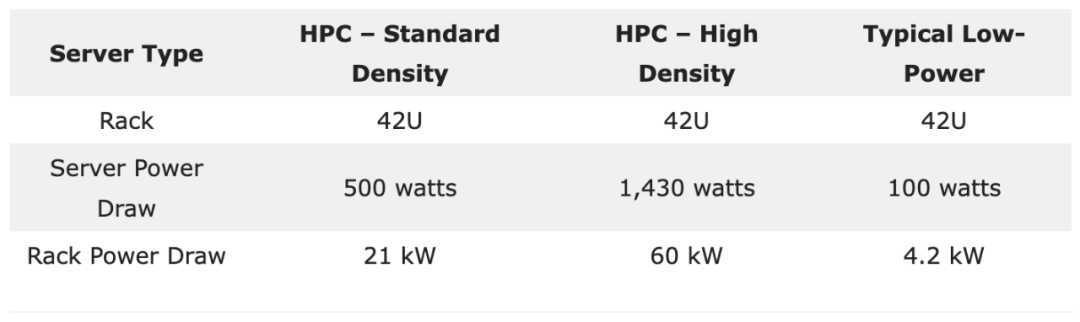
假设在一个拥有400个机架的数据中心中,部署了“标准”和“高”密度的HPC系统。这意味着整个数据中心的电力需求范围在8.4兆瓦(MW)到24.0兆瓦(MW)之间。对于那些具有非常高功率需求的场景,我们可以利用专用的高性能计算(HPC)环境,这样的环境专门针对大规模的、计算密集型的人工智能任务设计。HPC系统中使用的专用硬件
HPC系统通过整合高性能处理器(CPU)、高速内存和GPU等专用硬件,有效处理大量数据并支持AI工作负载。这些高端处理器具备迅速高效执行复杂计算和数据分析的能力。采用这类处理器可确保HPC系统在处理苛刻工作负载,如数据挖掘、科学模拟、高级分析和机器学习(ML)任务时,能够以快速处理速度和最小延迟的方式运行。
深度学习(DL)模型和实时人工智能需要专门的计算加速器来实现深度学习算法。最初,这种计算依赖于广泛使用的图形处理单元(GPU)。然而,一些云服务提供商后来开发了自己的定制芯片,如谷歌的TPU,一种专用集成电路(ASIC),以及微软的Project Catapult,它使用现场可编程门阵列(FPGA),以满足不断增长的人工智能工作负载需求。
GPU、ASIC和FPGA等专用硬件能够加速机器学习算法,已经成为现代HPC系统的重要组成部分。这些专用处理器旨在执行矩阵计算,特别适用于需要并行处理大量数据的机器学习任务。通过充分利用这些专用处理器,HPC系统能够显著提高对AI工作负载的处理速度。数据存储AI模型在进行训练和推理时需要大量数据,而数据中心提供了必要的存储容量,以容纳这些数据集。此外,人工智能应用会执行大量输入/输出(I/O)操作,例如从存储设备读取或写入数据,以及通过通信网络在设备之间交换信息。对于机器学习、深度学习和数据处理等人工智能工作负载而言,高速存储访问至关重要。这些工作负载需要存储系统具有快速的数据访问和传输速率。这种快速访问使得人工智能模型能够实时或接近实时地高效读取、写入和处理数据,从而提高训练、推理和数据分析等任务的性能并减少延迟。
数据中心通常使用硬盘驱动器(HDD)、固态驱动器(SSD)和网络附加存储(NAS)等大容量存储设备来存储和管理庞大的人工智能数据集。云服务提供商(CSP)如AWS、Microsoft Azure和Google Cloud提供低延迟和高吞吐量的存储解决方案。例如,Amazon FSx for Lustre是一种专为计算密集型工作负载设计的高性能文件系统,包括机器学习、高性能计算(HPC)和大数据处理。
网络
AI工作负载涉及大量的矩阵计算,这些计算分散在多个处理器上,如CPU、GPU、DPU等。为了有效地支持这些工作负载,我们需要一个高容量、可扩展且高可靠性的网络。随着人工智能集群等应用的普及,对网络带宽和容量的需求也在不断增长,这进一步挑战了网络的性能和可靠性。
在AI工作负载中,高性能网络的关键特性包括:
# 吞吐量
在运行大型AI应用时,网络的带宽对数据中心的整体性能至关重要。以GPU集群为例,它们通常需要比传统计算网络多出约3倍的带宽。
# Disaggregated AI应用
在该场景下,高性能网络的重要性进一步提升,由于AI应用的各个组件分布在数据中心内的多个硬件和软件资源上,它们需要快速而可靠地进行通信。这些组件之间需要无缝的通信,只有通过强大的网络基础设施才能实现,例如NVIDIA Mellanox 400G InfiniBand,其网络容量为每秒400吉比特(Gbps)。
# 效率
人工智能基础设施的效率与其网络性能直接相关。缓慢的网络可能会在整个基础设施中造成瓶颈,从而降低AI应用的运行效率。因此,为了确保AI工作负载的高效运行,一个完备的网络结构,包括拥塞控制和带宽管理等功能,是至关重要的。
03、AI数据中心散热AI应用和工作负载对IT设备提出了高功率密度的要求,这导致了大量的热量产生,从而增加了服务器的冷却需求。数据中心因此面临更多的冷却挑战,通常需要进行重新设计以确保维持适当的温度。低效的冷却不仅可能缩短设备的使用寿命和降低计算性能,还会增加冷却系统的负担。
为了应对这些冷却挑战,液体冷却和浸入式冷却成为了两种主要的解决方案。尤其在每个机架功率超过30 kW的高密度环境中,热点问题变得尤为明显,这时可能需要采用特殊的策略(如液冷)。当功率密度达到每机架60 kW至80 kW时,直接芯片液体冷却变得更加常见。
液冷液体冷却是一种涉及通过与 CPU 或 GPU 等电子组件直接接触的冷板循环冷却剂(例如水或 3M Novec 或 Fluorinert 等专用液体)的方法。在这个过程中,热量被液体冷却剂吸收,然后通过热交换器或散热器传输到空气中。冷却后的液体重新循环使用。
液体冷却在管理高密度人工智能工作负载方面特别有效,因为相比传统的空气冷却系统,它更有效地散热。值得注意的是,每单位体积液体的散热效率比空气高数千倍,因此内部硬件电子设备中往往采用循环液冷,液体循环可以有效地处理小空间中产生的大量热量,并将其传递到硬件外部的介质,比如空气。
总体而言,液冷系统在高功率密度环境中表现理想。然而,需要注意的是,液体冷却通常仅用于冷却CPU或GPU,而在房间中会产生一些余热,可能需要额外的空调来冷却其他组件。
浸没式冷却浸入式冷却是一种将电子元件浸入非导电液体冷却剂(如3M Novec或Fluorinert)中的方法。在这个过程中,冷却剂吸收部件产生的热量,通过循环送至热交换器进行冷却,然后再循环。浸入式冷却因其在运行HPC环境的数据中心中提供更高功率密度和更低电源使用效率(PUE)而备受关注。浸入式冷却不仅可以冷却CPU,还能够冷却印刷电路板(PCB)或主板上的其他组件。
案例研究 – Meta Platforms 的AI数据中心Meta Platforms,原名Facebook,是一家主要提供社交媒体和社交网络服务的科技巨头。为了满足其业务需求,Meta 在全球范围内拥有和运营了21个数据中心园区,总面积超过5000万平方英尺,并且还从其他第三方提供商那里租用了多个数据中心。截至2023年,该公司计划将超过300亿美元的资本支出中的大部分用于增强其人工智能(AI)能力,主要通过对GPU、服务器和数据中心的投资来实现。Meta 正在兴建专门支持下一代人工智能硬件的新数据中心。该公司的人工智能投资和产能将为各种产品和服务提供支持,包括广告、Feed、Reels和Metaverse。到目前为止,Meta 通过使用大规模GPU集群已经取得了一些成果,通过GPU协同工作可以更高效、更有效地处理复杂的人工智能工作负载。
基于Grand Teton GPU的硬件平台相比其前身Zion有多项性能提升,包括4倍的主机到GPU带宽、2倍的计算和数据网络带宽以及2倍的功率包络。Grand Teton的设计具有更高的计算能力,能更有效地支持内存带宽限制的工作负载,例如Meta的深度学习推荐模型(DLRM)。
总体而言,Meta的战略目标是在其所有的数据中心中实现标准化设计,以适应高功率密度的AI工作负载,其功率范围从每机架25 kW到每机架40 kW不等。为此,Meta目前正与能够构建经济高效、高功率密度AI基础设施的数据中心运营商进行合作。
Meta Platforms的液体冷却
为了支持其高功率密度的人工智能工作负载,Meta采用了液冷技术来确保服务器始终处于最佳的运行温度。具体来说,Meta使用空气辅助液体冷却(AALC)技术,结合闭环系统和后门热交换器,从而无需借助高架地板或外部管道就能实现服务器的冷却。这一技术的采纳是Meta向更为健壮的数据中心设计转型的一个关键步骤,进而推动了液体冷却技术的广泛应用。
05、AI时代的数据中心设计思考AI应用和工作负载使用高功率密度的机架,这些机架可以部署在各种设施类型中,包括大型的超大规模/云数据中心到小型的边缘数据中心。在超大规模/云数据中心方面,像AWS、Microsoft Azure和Google Cloud等云服务提供商提供了专门用于构建和部署AI模型的服务。由于这些设施规模宏大,它们特别适用于处理机器学习和深度学习训练、大数据分析、自然语言处理(NLP)和计算机视觉等人工智能应用程序和工作负载。至于边缘数据中心,这些设施相对较小而分散,位于更靠近数据生成和使用的地方,提供计算和存储服务。边缘数据中心的设计旨在满足对低延迟的快速响应时间要求的人工智能应用,例如实时视频分析、增强现实(AR)和虚拟现实(VR)、自动驾驶汽车以及无人机等。值得注意的是,由于不同的人工智能应用和系统对数据中心的要求各异,不是所有的数据中心都可以针对单一用例进行优化。例如,深度学习和人工智能系统需要较高数量的CPU或GPU处理器核心来缩短训练时间,而用于人工智能推理的引擎则可以利用较少的处理器核心来完成其任务。
-
数据中心
+关注
关注
16文章
4855浏览量
72364 -
AI
+关注
关注
87文章
31493浏览量
270190 -
人工智能
+关注
关注
1796文章
47643浏览量
240103
发布评论请先 登录
相关推荐
康普携五大解决方案亮相2024 CDCC数据中心标准大会
全球视野 算领未来,施耐德电气助力数据中心把握智算机遇

人工智能对数据中心的挑战
当今数据中心新技术趋势
数据中心产品通常包括哪些

安森美引领数据中心能效革命
AI时代,我们需要怎样的数据中心?AI重新定义数据中心

HNS 2024:星河AI数据中心网络,赋AI时代新动能













 工商网监
工商网监
评论