 SOK在手机行业的应用案例
SOK在手机行业的应用案例
介绍
通过封装 NVIDIA Merlin HugeCTR,Sparse Operation Kit(以下简称 SOK)使得 TensorFlow 用户可以借助 HugeCTR 的一些相关特性和优化加速 GPU 上的分布式 Embedding 训练。
在以往文章中(Merlin HugeCTR Sparse Operation Kit 系列之一、Merlin HugeCTR Sparse Operation Kit 系列之二)我们对 HugeCTR SOK 的基本功能、性能、用法和原理做了详细的介绍。近期 SOK 又发布了多个版本迭代,这篇博客对最新 v2.0 版本中的新特性(尤其是动态 Embedding 和在线训练增量导出)、用法进行了归纳总结和介绍,并在最后介绍了 SOK 在手机行业的应用案例。
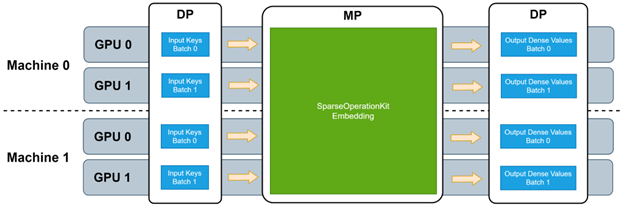
图 1. SOK 训练的数据并行
- 模型并行-数据并行流程
特性
SOK 作为 TensorFlow 的 Plugin,专注于针对 Embedding 的储存和查询过程进行优化,以下是目前 SOK 提供的主要功能:
提供 Embedding 部分的多机多卡模型并行功能;
为 Embedding Table 提供了 Hash Table 的功能,并且该 Hash Table 可以将 Embedding Vector 存放到 Device Memory 和 Host Memory 上,充分利用设备储存;
为 Embedding Lookup 提供了高性能的 Embedding Lookup Kernel,采用 HugeCTR 的 Cuda Kernel 为后端,Fuse 多个 Lookup Op 到一个 Lookup Op,提升 Embedding Lookup 性能;
提供增量导出功能,导出某个时间点后 Embedding Table 中更新过的 Key 和 Value,减少训练权重推送到推理端的开销。
立即使用 SOK
Embedding Table
SOK 基于 TensorFlow 的 Variable 的基础上,提供了 Variable 和 DynamicVariable 来储存 Embedding Table。
不同于 TensorFlow 的 Variable 将数据储存到某个 GPU 中,SOK 的 Variable 可以将数据均匀储存在训练的所有 GPU 上,也可以将数据储存到某一个 GPU 中,下面是使用 SOK 的 Variable 创建储存在每一个 GPU 和 Variable 储存到 GPU0 上的例子:
#Defaultmethodofsok.VariableisDistributedmethod,VariableevenlydistributedtoeachGPU v1 = sok.Variable(np.arange(15 * 16).reshape(15, 16), dtype=tf.float32) #If you want to assign a sok.Variable to a specific GPU, add the parameter mode=“localized:gpu_id” when defining sok.variable, where gpu_id refers to the rank number of a GPU in Horovod v2=sok.Variable(np.arange(15*16).reshape(15,16),dtype=tf.float32,mode="localized:0")
v1 的申请中,SOK 会自动将 v1 的数据均匀储存到训练域中每一个 GPU 上,v2 的申请中,在参数中添加了mode="localized:0" 这个字符串参数,SOK 会将 v2 的数据放置在 GPU0 中。
SOK 中提供了 Variable 和 DynamicVariable 两种不同的形式储存 Embedding Table。Variable 可以简称为 Static Embedding Table,一个是静态的二维数据,在申请时需要确定 Embedding Table 的 Shape,申请结束后,SOK 会相应申请好数据使用的空间(如果 Static Embedding Table 分布在所有 GPU 上,那么所有 GPU 平分这个空间)。因为 Static Embedding Table 是一个静态的二维数组,这也意味着 Lookup 时查找的 Indice,是无法超出这个二维数组第一个 Dimension 的长度的,否则会发生越界问题。
Static Embedding Table,对于 Lookup Indice 存在范围限制,很多用户输入的 Lookup Indice 又是 Hash 过的 Key,所以 SOK 提出 DynamicVariable 来解决 Lookup Indice 范围限制的问题。SOK 的 DynamicVariable 是使用 Hash Table 来储存 Embedding Table 的,解决了这个问题。
SOK 的 DynamicVariable 封装了 2 个基于 GPU 的 Hash Table(HierarchicalKV 和 Dynamic Embedding Table),其中 HierarchicalKV(以下简称 HKV)是 NVIDIA Merlin 框架下的 Hash Table Repo,它有以下 2 个特性:
HKV 可以利用 GPU Memory 和 Host Memory 储存 Embedding Table 中的 Embedding Vector,充分利用训练中的内存资源;
HKV 的 Hash Table 拥有 Eviction 功能,Hash Table 满了后不会继续增长,继续 Insert 会淘汰掉最不常用的 Key/Value,提供 LRU、LFU 等常用淘汰策略,也可以自定义淘汰策略。
HKV 的 Repo 地址为 HKV repo,提供了 C++ Level 的 Hash Table API,也为推荐系统提供了组合 API,方便推荐系统用户使用。SOK 中申请 HKV Embedding Table 的代码如下:
#init_capacityandmax_capacityareparametersacceptedbytheHKVtable.ThemeaningsoftheseparameterscanbefoundintheHKVdocumentation. v2 = sok.DynamicVariable( dimension=16, # embedding vector length var_type="hybrid", # use HKV backend initializer="uniform", # use uniform distribution random initializer init_capacity=1024 * 1024, # The number of embedding vectors allocated initially in the hash table max_capacity=1024 * 1024, # The number of embedding vectors allocated finally in the hash table max_hbm_for_vectors=2,#howmanyGPUmemoryshouldthishashtableuse,unitisGB
从上面代码可见,SOK 申请 HKV Hash Table 时,需要设置一些参数,这些参数如何设置可以阅读 SOK 和 HKV 的文档。
SOK 的 Variable 和 DynamicVariable 均继承自 TensorFlow 的 ResourceVariable,除了 SOK 的自己定义的参数外,读者和用户可以按照使用 ResourceVariable 的习惯添加 ResourceVariable 的参数。
Embedding Lookup
SOK embedding lookup_sparse 提供与 tf.nn.embedding_lookup_sparse 相似的 API,与 tf.nn.embedding_lookup_sparse 不同的是,SOK 的 embedding lookup_sparse 可以同时将多个 Lookup Fuse 到一起,代码如下:
#UseSOKembeddinglookupsparsetodo2embeddinglookups
emb1, emb2 = sok.lookup_sparse([sok_var1, sok_var2],[keys1, keys2],combiners=["sum", "mean"])
# equals to
emb1 = tf.nn.embedding_lookup_sparse(v1, indices1, combiner="sum")
emb2=tf.nn.embedding_lookup_sparse(v2,indices2,combiner="mean")
Embedding Table Dump/Load
SOK 关于 Embedding Table 的权重提供了 Dump/Load 和增量导出 Incremental Dump 的功能。
Dump/Load 可以自动并行的进行 Embedding Table 的 Key、Value、Optimizer 中状态变量(可选)在文件系统中的读写,将 Embedding Table 的 Key、Value、Optimizer 中的状态变量储存成二进制文件/从二进制文件中读取,下面是 SOK 中 Dump/Load 的例子:
#optimizerstatesareoptional.IftheyareunspecifiedincallingtheAPIsabove,onlythekeysandvaluesareloaded. optimizer = tf.keras.optimizers.SGD(learning_rate=1.0) sok_optimizer = sok.OptimizerWrapper(optimizer) path = "./weights" sok_vars = [sok_var1,sok_var2] sok.dump(path, sok_vars, sok_optimizer) sok.load(path,sok_vars,sok_optimizer)
在大部分推荐系统业务中,Embedding Table 的内存占用非常大,因此,在 Continued Training 中,用户通常会将训练一段时间后更新了的 Key 和 Value 推送到推理端,这样可以避免推送整个 Embedding Table 产生的巨大开销,SOK 同样提供了 incremental_dump 的 API 来实现这个功能。incremental_dump 接受一个 UTC Time Threshold,可以将 Time Threshold 后更新的 Key/Value 导出到 Numpy Array 中:
#sokincrementaldump import pytz from datetime import datetime #should convert datatime to utc time utc_time_threshold = datetime.now(pytz.utc) sok_vars = [sok_var1,sok_var2] #keys and values are Numpy array keys,values=sok.incremental_model_dump(sok_vars,utc_time_threshold)
SOK 与 TensorFlow 的兼容性
SOK 目前兼容 TF2 的静态图,但是不支持 TensorFlow 的 XLA,如果开启 TensorFlow 的 XLA,需要手动将 SOK 的 Lookup 的 Layer 排除在外,伪代码如下所示:
@tf.function
def sok_layer(inputs):
return sok.lookup_sparse(inputs)
@tf.function(jit_compile=True)
def xla_layer(inputs):
x = xla_layer(inputs)
returnx
应用案例分享
以下是近期 NVIDIA 技术团队开展的部分手机行业推荐场景高性能优化项目实践经验分享:
案例 1:通过 NVIDIA Merlin
HugeCTR SOK 以及 NVTabular
实现了 GPU 加速的推荐系统
应用背景:
客户的推荐系统是针对客户手机端的广告和内容,该推荐系统之前是使用 CPU PS 架构运行,客户希望使用 GPU 架构来进行加速。
应用方案/效果以及影响:
通过 HugeCTR Sparse Operation Kit + NVTabular 实现了 GPU 加速的推荐系统,性能加速如下:
实验性能对比:
SOK 将原有只能单 GPU 训练的任务扩展到多 GPU 训练,并且达到了很好的弱扩展性,支持更大的模型。SOK + tfrecord 3GPU 耗时约 1.3 个小时 vs TF + tfrecord 1GPU 耗时约 3.4 个小时。
业务性能对比:
由于业务系统输入数据较大,因此客户采取 Parquet 数据格式进行 Input 数据压缩,业务性能提升如下,NVTabular Load Parquet 耗时约 1.8 个小时 vs TF Load Parquet 耗时约 7.8 个小时。
在 SOK 加速的基础上,NVTabular Parguet Datareader 进一步解决了数据读取瓶颈的问题,在实际业务测试中,相比原生 TensorFlow Parquet Datareader 达到了 400% 的速度提升。
案例 2:通过 NVIDIA Merlin
HugeCTR SOK 实现了
GPU 加速的推荐系统
应用背景:
客户的推荐系统是针对客户手机端的广告和内容,该推荐系统使用 CPU + PS 和 GPU + PS 的架构运行。
应用方案/效果以及影响:
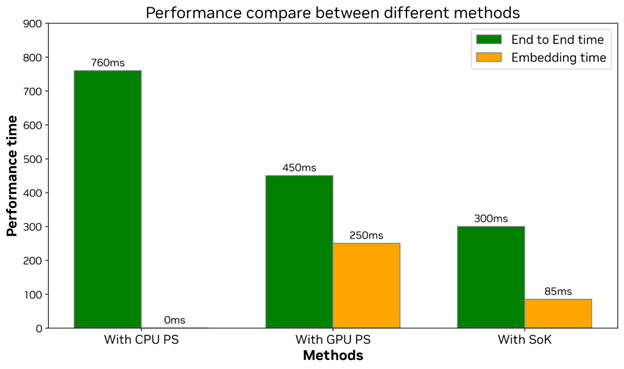
通过 HugeCTR Sparse Operation Kit 进行了 GPU 加速的推荐系统的实验,性能加速如下:
End to End 时间从 CPU + PS 的 760 毫秒优化至 300 毫秒,性能提升约 60%。GPU + PS 的 450 毫秒优化至 300 毫秒,性能提升约 33%。
GPU + PS 架构的 Embedding 部分耗时为 250 毫秒,SOK 的 Embedding 部分耗时为 85 毫秒,性能提升 67%。
结束语
SOK v2.0 通过封装 HKV 和 HugeCTR 的底层代码提供了模型并行,且功能完善的动态 Embedding Table 和高效的相关计算。在多个业内实际使用场景中,从速度效率、模型扩展、功能完善等角度,使用户获得了不错的收益。
关于作者
康晖
GPU 计算专家,2022 年加入 NVIDIA,当前主要从事 SOK 的设计与开发。研究领域包括推荐系统工程实现与优化,通讯优化。
-
NVIDIA
+关注
关注
14文章
5108浏览量
104475 -
gpu
+关注
关注
28文章
4831浏览量
129780 -
模型
+关注
关注
1文章
3417浏览量
49479 -
SOK
+关注
关注
0文章
5浏览量
6358
原文标题:借助最新 NVIDIA Merlin TensorFlow 插件实现大规模 Embedding 扩展
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
声表面滤波器有用在手机上吗?
通过GPS参数怎么在手机地图上显示
在手机上采用USB传输高清视频
5G在手机中的应用真实情况究竟是什么样的呢?
应用在手机领域的各类传感器介绍
怎么做到在手机上自主分析数据的?
UWB在手机中的应用是什么
基于ERP在手机制造行业中的应用

机器人在手机行业的应用
SOK的Embedding计算过程及原理详解
了解SOK的原理





 工商网监
工商网监
评论