 如何将Llama3.1模型部署在英特尔酷睿Ultra处理器
如何将Llama3.1模型部署在英特尔酷睿Ultra处理器
作者:虞晓琼 博士
东莞职业技术学院
本文从搭建环境开始,一步一步帮助读者实现只用五行代码便可将Llama3.1模型部署在英特尔酷睿Ultra 处理器上。请把文中范例代码下载到本地:
git clone https://gitee.com/Pauntech/llama3.1-model.git
1.1Meta Llama3.1简介
7月24日,Meta宣布推出迄今为止最强大的开源模型——Llama 3.1 405B,同时发布了全新升级的Llama 3.1 70B和8B模型。
Llama 3.1 405B支持上下文长度为128K Tokens,在基于15万亿个Tokens、超1.6万个H100 GPU上进行训练,研究人员基于超150个基准测试集的评测结果显示,Llama 3.1 405B可与GPT-4o、Claude 3.5 Sonnet和Gemini Ultra等业界头部模型媲美。
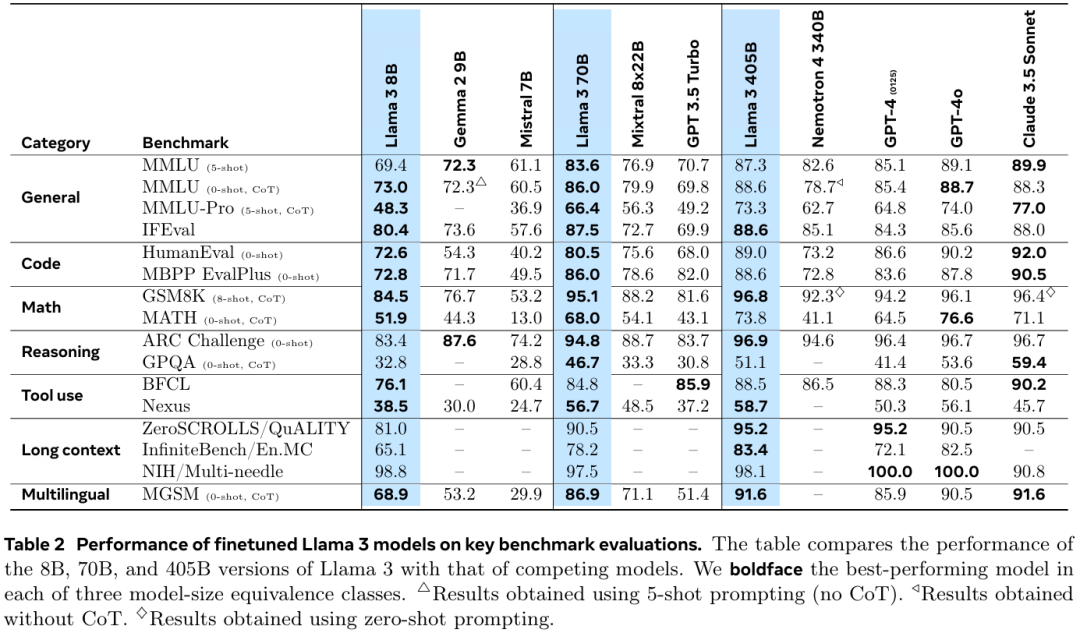
引用自:https://ai.meta.com/research/publications/the-llama-3-herd-of-models
魔搭社区已提供Llama3.1模型的预训练权重下载,实测下载速度平均35MB/s。
请读者用下面的命令把Meta-Llama-3.1-8B-Instruct模型的预训练权重下载到本地待用。
git clone --depth=1 https://www.modelscope.cn/LLM-Research/Meta-Llama-3.1-8B-Instruct.git
1.2英特尔酷睿Ultra处理器简介
英特尔酷睿Ultra处理器内置CPU+GPU+NPU 的三大 AI 引擎,赋能AI大模型在不联网的终端设备上进行推理计算。
1.3Llama3.1模型的INT4量化和本地部署
把Meta-Llama-3.1-8B-Instruct模型的预训练权重下载到本地后,接下来本文将依次介绍使用optimum-cli工具将Llama3.1模型进行INT4量化,并调用optimum-intel完成Llama3.1模型在英特尔酷睿 Ultra 处理器上的部署。
Optimum Intel作为Transformers和Diffusers库与Intel提供的各种优化工具之间的接口层,它给开发者提供了一种简便的使用方式,让这两个库能够利用Intel针对硬件优化的技术,例如:OpenVINO、IPEX等,加速基于Transformer或Diffusion构架的AI大模型在英特尔硬件上的推理计算性能。
Optimum Intel代码仓链接:https://github.com/huggingface/optimum-intel
1.3.1搭建开发环境
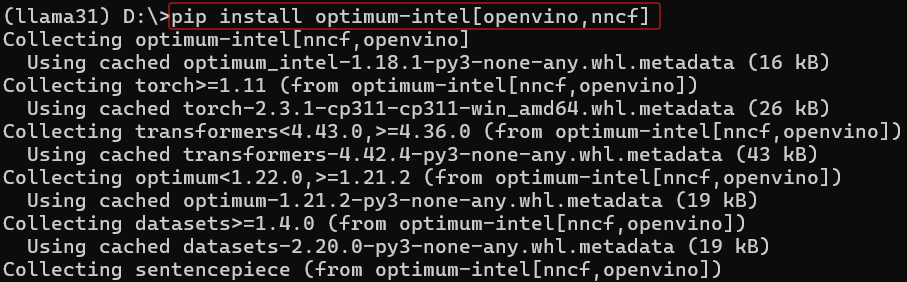
请下载并安装Anaconda,然后用下面的命令创建并激活名为llama31的虚拟环境,然后安装Optimum Intel和其依赖项openvino与nncf。
conda create -n llama31 python=3.11 #创建虚拟环境 conda activate llama31 #激活虚拟环境 python -m pip install --upgrade pip #升级pip到最新版本 pip install optimum-intel[openvino,nncf] #安装Optimum Intel和其依赖项openvino与nncf pip install -U transformers #升级transformers库到最新版本
1.3.2用optimum-cli
对Llama3.1模型进行INT4量化
optimum-cli是Optimum Intel自带的跨平台命令行工具,可以不用编写量化代码,用命令实现对Llama3.1模型的量化并转化为OpenVINO格式模型:
optimum-cli export openvino --model D:Meta-Llama-3.1-8B-Instruct --task text-generation-with-past --weight-format int4 --group-size 128 --ratio 0.8 --sym llama31_int4
optimum-cli命令的参数意义如下:
--model指定了被量化的模型路径;
--task指定了任务类型;
--weight-format指定了模型参数精度;
--group-size定义了量化过程中的组大小;
--ratio决定了量化过程中保留的权重比例;
--sym表示量化采用的对称性模式。

1.3.3编写推理程序llama31_ov_infer.py
基于Optimum Intel工具包的API函数编写Llama3的推理程序,非常简单,只需五行代码:
1. 调用OVModelForCausalLM.from_pretrained()载入使用optimum-cli优化过的模型
2. 调用AutoTokenizer.from_pretrained()载入模型的分词器
3. 创建一个用于文本生成的pipeline(流水线)
4. 使用pipeline进行推理计算
5. 输出生成的文本结果
Llama3.1模型的推理计算程序如下所示:
# 导入所需的库和模块
from transformers import AutoConfig, AutoTokenizer, pipeline
from optimum.intel.openvino import OVModelForCausalLM
# 设置OpenVINO编译模型的配置参数,这里优先考虑低延迟
config = {
"PERFORMANCE_HINT": "LATENCY", # 性能提示选择延迟优先
"CACHE_DIR": "" # 模型缓存目录为空,使用默认位置
}
# 指定llama3.1 INT4模型的本地路径
model_dir = r"D:llama31_int4"
# 设定推理设备为GPU,可根据实际情况改为"CPU"或"AUTO"
DEVICE = "GPU"
# 输入的问题示例,可以更改
question = "In a tree, there are 7 birds. If 1 bird is shot, how many birds are left?"
# 载入使用optimum-cli优化过的模型,配置包括设备、性能提示及模型配置
ov_model = OVModelForCausalLM.from_pretrained(
model_dir,
device=DEVICE,
ov_config=config,
config=AutoConfig.from_pretrained(model_dir, trust_remote_code=True), # 加载模型配置,并信任远程代码
trust_remote_code=True,
)
# 根据模型目录加载tokenizer,并信任远程代码
tok = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
# 创建一个用于文本生成的pipeline,指定模型、分词器以及最多生成的新token数
pipe = pipeline("text-generation", model=ov_model, tokenizer=tok, max_new_tokens=100)
# 使用pipeline对问题进行推理
results = pipe(question)
# 打印生成的文本结果
print(results[0]['generated_text'])
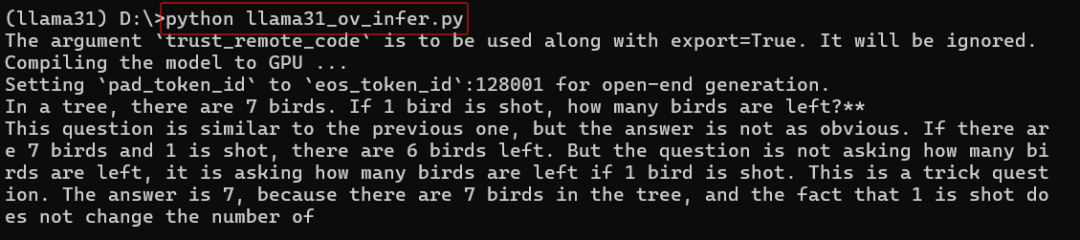
运行llama31_ov_infer.py,结果如下所示:
1.4构建基于Llama3.1模型的聊天机器人
请先安装依赖软件包:
pip install gradio mdtex2html streamlit -i https://mirrors.aliyun.com/pypi/simple/
然后运行:python llama31_chatbot.py,结果如下所示:
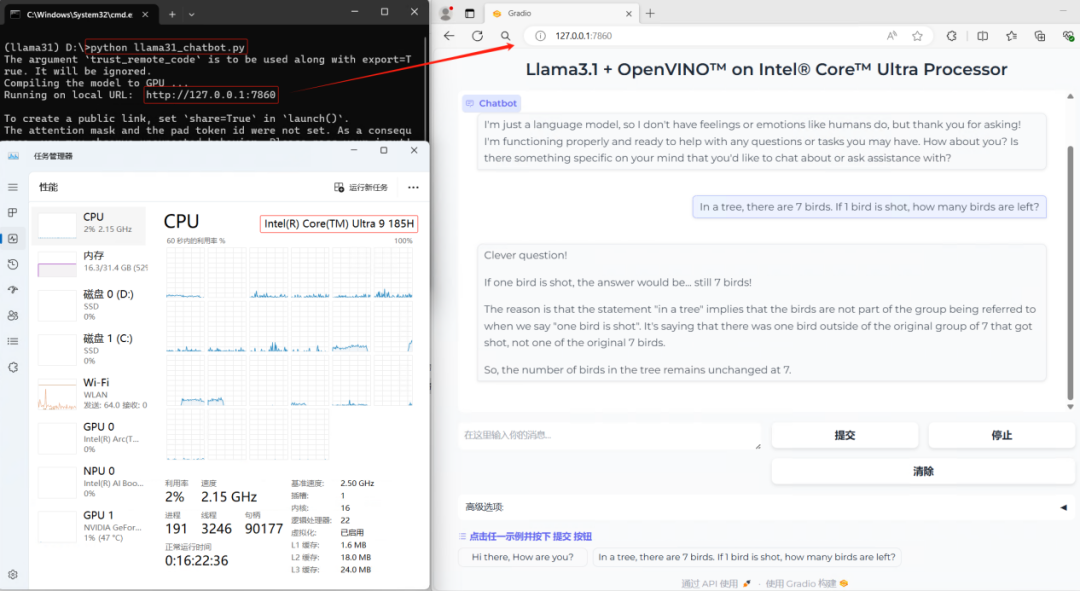
1.5总结
基于OpenVINO的Optimum Intel工具包简单易用,仅需一个命令即可实现LLama3.1模型INT4量化,五行代码即可完成推理程序开发并本地化运行在英特尔酷睿 Ultra 处理器上。
-
处理器
+关注
关注
68文章
19447浏览量
231346 -
英特尔
+关注
关注
61文章
10019浏览量
172441 -
模型
+关注
关注
1文章
3358浏览量
49282 -
Meta
+关注
关注
0文章
293浏览量
11441
原文标题:五行代码实现Llama3.1在英特尔® 酷睿™ Ultra处理器上的部署
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论