 NVIDIA NeMo加速并简化自定义模型开发
NVIDIA NeMo加速并简化自定义模型开发
如果企业希望充分发挥出 AI 的力量,就需要根据其行业需求量身定制的自定义模型。
NVIDIA AI Foundry 是一项使企业能够使用数据、加速计算和软件工具创建并部署自定义模型的服务,这些模型将为企业的生成式 AI 项目提供强力支持。
就像台积电制造其他公司设计的芯片一样,NVIDIA AI Foundry 为其他公司提供基础设施和工具,使他们能够使用 DGX Cloud、基础模型、NVIDIA NeMo 软件、NVIDIA 专业知识以及各种生态系统工具和支持,开发和自定义 AI 模型。
关键的区别在于产品:台积电生产实体半导体芯片,而 NVIDIA AI Foundry 则帮助创建自定义模型。两者都在推动创新,并与庞大的工具和合作伙伴生态系统相连接。
企业可以使用 AI Foundry 自定义 NVIDIA 模型和开放社区模型,包括新推出的 Llama 3.1 系列以及 NVIDIA Nemotron、Google DeepMind 的 CodeGemma、CodeLlama、Google DeepMind 的 Gemma、Mistral、Mixtral、Phi-3 和 StarCoder2 等。
行业领导者推动 AI 创新
行业领导者 Amdocs、Capital One、Getty Images、KT、现代汽车公司、SAP、ServiceNow 和 Snowflake 是 NVIDIA AI Foundry 的首批企业用户。这些领军企业正在企业软件、技术、通信和媒体领域开辟一个由 AI 驱动创新的新时代。
ServiceNow AI 产品副总裁 Jeremy Barnes 表示:“部署 AI 的企业可以通过融合了行业和业务知识的自定义模型获得竞争优势。ServiceNow 正在使用 NVIDIA AI Foundry 微调和部署可以轻松集成到客户现有的工作流中的模型。”
NVIDIA AI Foundry 的关键支柱
NVIDIA AI Foundry 的关键支柱包括基础模型、企业软件、加速计算、专家支持和庞大的合作伙伴生态系统。
这项服务的软件包括来自 NVIDIA 和 AI 社区的 AI 基础模型,以及能够加速模型开发的完整 NVIDIA NeMo 软件平台。
NVIDIA AI Foundry 的计算核心是 NVIDIA DGX Cloud,该加速计算资源网络由 NVIDIA 与全球公有云领军企业亚马逊云科技、谷歌云和 Oracle Cloud Infrastructure 共同设计。通过 DGX Cloud,AI Foundry 客户能够以前所未有的便捷和效率开发和微调自定义生成式 AI 应用,并根据需要扩展他们的 AI 项目,而无需在前期进行大量硬件方面的投入。这种灵活性对于希望在瞬息万变的市场中保持灵活性的企业来说至关重要。
NVIDIA AI Enterprise 专家会在 AI Foundry 客户需要时提供帮助。NVIDIA 专家可以指导客户完成使用专有数据构建、微调和部署模型所需的各个步骤,确保模型贴合客户的业务需求。
NVIDIA AI Foundry 客户可以进入到一个全球合作伙伴生态系统,以获得全方位的支持。埃森哲、德勤、Infosys、Wipro 等 NVIDIA 合作伙伴将为他们提供 AI Foundry 咨询服务,涵盖设计、实施和管理 AI 驱动的数字化转型项目。埃森哲率先推出了基于 AI Foundry 的自定义模型开发产品——Accenture AI Refinery 框架。
另外,Data Monsters、Quantiphi、Slalom 和 SoftServe 等服务交付合作伙伴帮助企业解决将 AI 集成到现有 IT 环境中所遇到的复杂问题,确保 AI 应用的可扩展性、安全性和与业务目标的吻合性。
Cleanlab、DataDog、Dataiku、Dataloop、DataRobot、Domino Data Lab、Fiddler AI、New Relic、Scale、Weights & Biases 等 NVIDIA 合作伙伴还为客户提供用于开发生产级 NVIDIA AI Foundry 模型的 AIOps 和 MLOps 平台。
客户可以将其 AI Foundry 模型导出为 NVIDIA NIM 推理微服务(包括自定义模型、优化引擎和标准 API),以便在其选择的加速基础设施上运行。
像 NVIDIA TensorRT-LLM 这样的推理解决方案为 Llama 3.1 模型提供了更高的效率,以最大限度地减少延迟和最大限度地提高吞吐量。这使企业能够更快地生成 token,同时降低在生产中运行模型的总成本。企业级的支持和安全性由 NVIDIA AI Enterprise 软件套件提供。
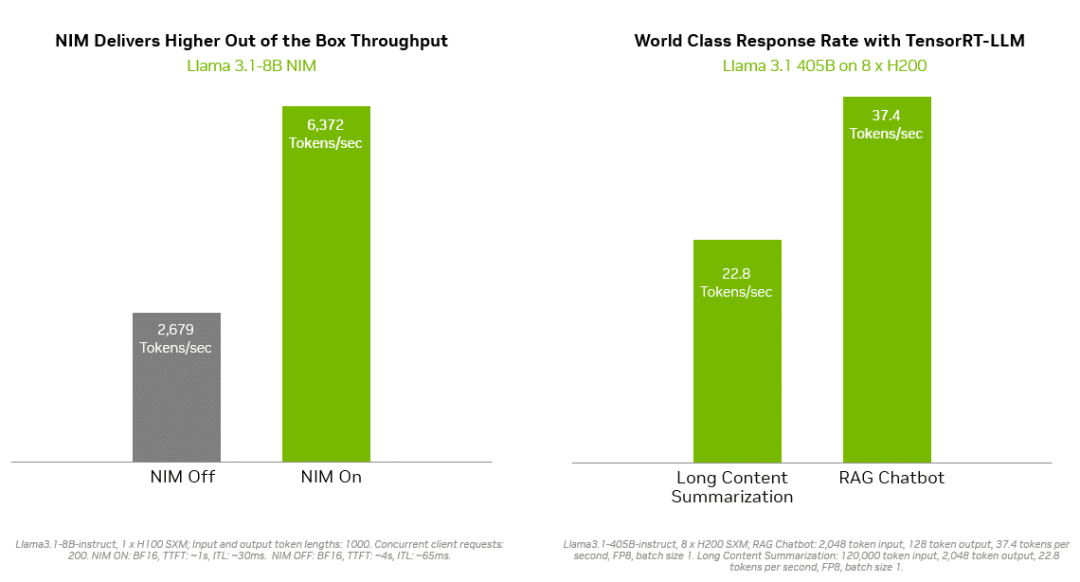
NVIDIA NIM 和 TensorRT-LLM 最大限度地减少了 Llama 3.1 模型的推理延迟并最大限度地提高了吞吐量,从而更快地生成 token。
它们可部署在多种基础设施上,包括思科、戴尔科技、慧与、联想、超微等全球服务器制造合作伙伴的 NVIDIA 认证系统以及亚马逊云科技、谷歌云和 Oracle Cloud 的云实例。
此外,领先的 AI 加速云平台 Together AI 宣布,将让其拥有超过 10 万名开发者和企业的生态系统能够使用 NVIDIA GPU 加速推理堆栈,在 DGX Cloud 上部署 Llama 3.1 端点和其他开放模型。Together AI 创始人兼首席执行官 Vipul Ved Prakash 表示:“每个运行生成式 AI 应用程序的企业都希望获得更快的用户体验,使效率更高,成本更低。现在,使用 Together Inference Engine 的开发者和企业可以在 NVIDIA DGX Cloud 上最大化其性能、可扩展性和安全性。”
NVIDIA NeMo 加速并简化
自定义模型开发
通过集成在 AI Foundry 中的 NVIDIA NeMo,开发者可以随时使用所需的工具来整理数据、自定义基础模型和评估性能。NeMo 将提供以下技术:
NeMo Curator:一个由 GPU 提供加速的数据管理库,通过为预训练和微调准备大规模、高质量的数据集,提高生成式 AI 模型的性能。
NeMo Customizer:一项高性能且可扩展的微服务,可简化针对特定领域用例的 LLM 微调和对齐。
NeMo Evaluator:可在任何加速云或数据中心上,使用各种学术和自定义基准测试对生成式 AI 模型进行自动评估。
NeMo Guardrails:能够编排对话管理,通过大语言模型提高智能应用的准确性、适当性和安全性,为生成式 AI 应用提供保障。
借助 NVIDIA AI Foundry 中的 NeMo 平台,企业能够创建出精准满足其需求的自定义 AI 模型。这种定制化与战略目标更加吻合,提高了决策的准确性以及运营的效率。例如企业可以开发出理解行业术语、符合监管要求并与现有工作流无缝集成的模型。
SAP 首席人工智能官 Philipp Herzig 表示:“作为我们合作的下一步,SAP 计划使用 NVIDIA 的 NeMo 平台,来帮助企业去加速由 SAP Business AI 驱动的 AI 生产力。”
企业可以通过 NVIDIA NeMo Retriever NIM 推理微服务将其自定义 AI 模型部署到生产中。它们可以帮助开发者获取专有数据,然后通过检索增强生成(RAG)为其 AI 应用生成知识渊博的回答。
Snowflake AI 主管 Baris Gultekin 表示:“安全、可信的 AI 是企业充分利用生成式 AI 的必要前提,而检索的准确性直接影响到 RAG 系统中生成的回答的相关性和质量。通过 NVIDIA AI Foundry 中的 NeMo Retriever 组件,Snowflake Cortex AI 可以使用企业的自定义数据,进一步为企业提供简单、高效和可信的回答。”
自定义模型为企业带来竞争优势
NVIDIA AI Foundry 的一大优势是能够解决企业在采用 AI 时所面临的独特挑战。通用 AI 模型可能无法满足特定的业务需求和数据安全要求,而自定义 AI 模型则具有出色的灵活性、适应性和性能,是企业获得竞争优势的理想途径。
-
NVIDIA
+关注
关注
14文章
4984浏览量
103015 -
AI
+关注
关注
87文章
30812浏览量
268955 -
模型
+关注
关注
1文章
3236浏览量
48822
原文标题:NVIDIA AI Foundry 如何帮助企业打造自定义生成式 AI 模型
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
请问multisim怎么自定义元器件?
开发用于将四个ADC通道连接到MCU/MPU的自定义多通道SPI

Mistral AI与NVIDIA推出全新语言模型Mistral NeMo 12B
NVIDIA AI Foundry 为全球企业打造自定义 Llama 3.1 生成式 AI 模型

揭秘NVIDIA AI Workbench 如何助力应用开发
如何为ESP8266构建自定义盾牌?
HarmonyOS开发案例:【 自定义弹窗】

AWTK 开源串口屏开发(18) - 用 C 语言自定义命令

TSMaster 自定义 LIN 调度表编程指导

HarmonyOS开发案例:【UIAbility和自定义组件生命周期】





 工商网监
工商网监
评论