 Yuan2.0千亿大模型在通用服务器NF8260G7上的推理部署
Yuan2.0千亿大模型在通用服务器NF8260G7上的推理部署
巨量模型的智能生产力正在逐步渗透到各行各业,但它们的部署和运行通常需要专用的AI加速卡,能否在CPU上运行千亿大模型,对千行百业智能化转型的深化与普惠至关重要。
日前,浪潮信息研发工程师基于2U4路旗舰通用服务器NF8260G7,通过张量并行、模型压缩量化等技术,解决了通用服务器的CPU计算资源不足、内存带宽瓶颈、缺乏大规模并行计算环境等问题,在业内首次实现服务器仅依靠4颗CPU即可运行千亿参数“源2.0”大模型。该方案建设成本更低,首次投入可节约80%以上建设成本,且通用服务器功耗更低,运维更便捷,能够有效降低客户TCO。
大模型推理的硬件需求:内存与带宽的双重考验
当前,大模型的推理计算面临多方面的挑战,制约了大模型服务成本的降低和应用落地。
首先是对内存容量的需求。大模型的推理过程中,需要将全部的模型权重参数、计算过程中的KV Cache等数据存放在内存中,一般需要占用相当于模型参数量2-3倍的内存空间。随着业界LLM的网络架构从GPT架构走向MOE架构,主流开源模型的尺寸越来越大,千亿及以上参数的模型已经成为主流,运行一个千亿大模型(100B),则需要200-300GB的显存空间。
其次是对计算和内存读写带宽的需求。大模型的推理主要分为预填充和解码两个阶段。预填充阶段把Prompt一次性输入给模型进行计算,对显存的需求更大;解码阶段,每次推理仅生成1个token,计算访存较低,对内存带宽的需求更大。因此,千亿大模型的实时推理,计算设备需要具备较高的计算能力,以及较高的存储单元到计算单元的数据搬运效率。
NF8260G7作为一款采用高密度设计的2U4路服务器,支持16TB大内存容量,配置了4颗具有AMX(高级矩阵扩展)的AI加速功能的英特尔至强处理器,内存带宽极限值为1200GB/s。尽管NF8260G7服务器可以轻松满足千亿大模型推理的内存需求,甚至于万亿参数的MOE架构大模型推理的内存需求。但是,按照BF16的精度计算,千亿参数大模型运行时延要小于100ms,内存与计算单元之间的通信带宽至少要在2TB/s以上。因此,要在NF8260G7上实现千亿大模型的高效运行,仅靠硬件升级还远远不够,硬件资源与软件算法协同优化至关重要。
 张量并行+NF4量化,实现千亿模型极致优化
张量并行+NF4量化,实现千亿模型极致优化
Yuan2.0-102B是浪潮信息发布的新一代基础语言大模型,参数量为1026亿,通过提出全新的局部注意力过滤增强机制(LFA:Localized Filtering-based Attention),有效提升了自然语言的关联语义理解能力。
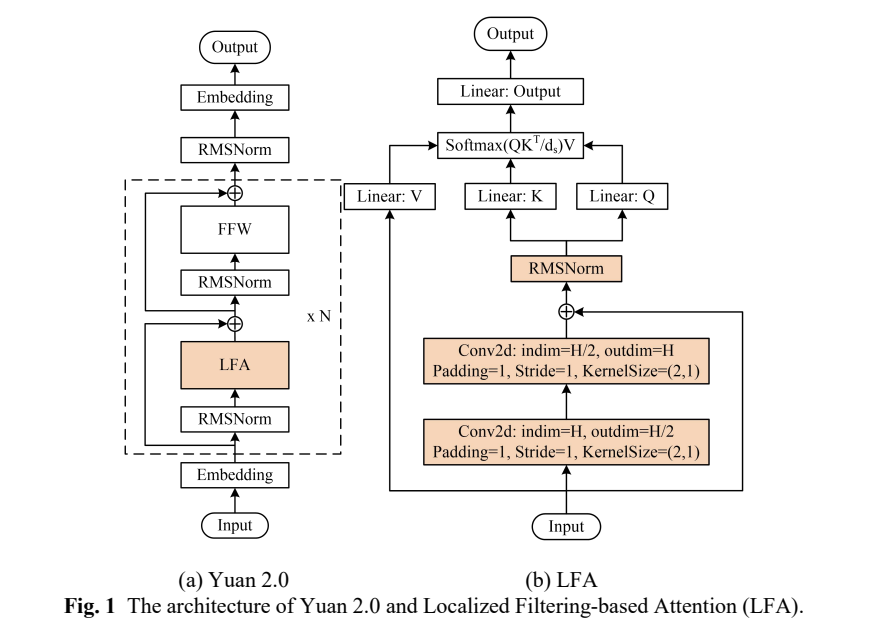
为了尽可能提升Yuan2.0-102B模型在NF8260G7服务器上的推理计算效率,浪潮信息算法工程师采用了张量并行(tensor parallel)策略。该策略改变了传统CPU服务器串行运行的模式,把Yuan2.0-102B模型中的注意力层和前馈层的矩阵计算分别拆分到多个处理器,实现同时使用4颗CPU进行计算加速。然而,张量并行对模型参数的切分粒度较细,要求CPU在每次张量计算后进行数据同步,增加了对CPU间通信带宽的需求。在传统的使用多个基于PCIe互联的AI芯片进行张量并行时,通信占比往往会高达50%,也就是AI芯片有50%的时间都在等待数据传输,极大影响了推理效率。
NF8260G7服务器的4颗CPU通过全链路UPI(Ultra Path Interconnect)总线互连,该设计带来了两个优势:首先,全链路UPI互连允许任意两个CPU之间直接进行数据传输,减少了通信延迟;其次,全链路UPI互连提供了高传输速率,高达16GT/s(Giga Transfers per second),远高于PCIe的通信带宽,保障了4颗处理器间高效的数据传输,从而支持张量并行策略下的数据同步需求。
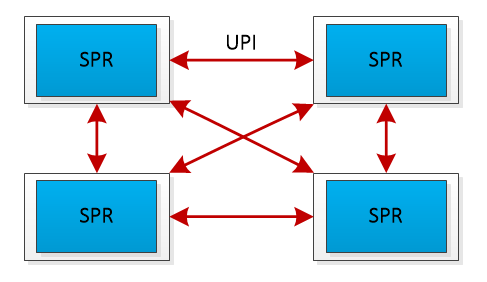
UPI总线互连示意图
为了进一步提升Yuan2.0-102B模型在NF8260G7服务器上的推理效率,浪潮信息算法工程师还采用了NF4量化技术,来进一步提升推理的解码效率,从而达到实时推理的解码需求。NF4(4位NormalFloat)是一种分位数量化方法,适合于正态分布的数据。它通过确保量化区间内输入张量的值数量相等,来实现对数据的最优量化。由于大型语言模型(LLM)的权重通常呈现零中心的正态分布,NF4量化技术可以通过调整标准差来适配量化数据类型的范围,从而获得比传统的4位整数或4位浮点数量化(这些量化方法的数据间隔通常是平均分布或指数分布的)更高的精度。
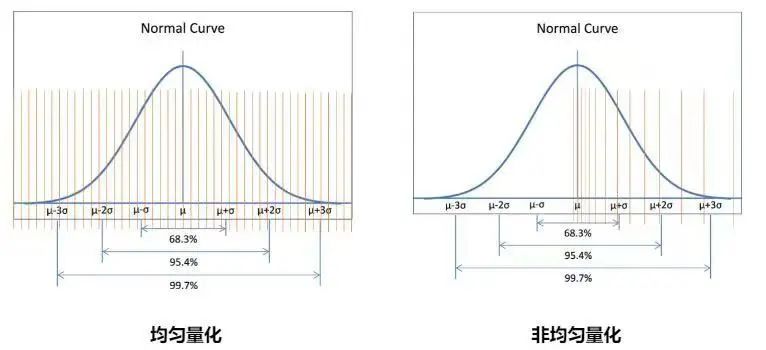
INT4数据类型与NF4数据类型对比
为了进一步压缩Yuan2.0-102B模型的权重参数,浪潮信息算法工程师采用了嵌套量化(Double Quant)技术,这是在NF4量化基础上进行的二次量化。NF4量化后,由于会产生大量的scale参数,如果使用32位浮点数(FP32)存储,会占用大量的内存空间。若以64个参数作为一个量化块(block size=64)来计算,对于一个千亿参数的大模型,仅存储scale参数就需要额外的6GB内存:
(100B/64) * 4 = 6GB
为了减少内存占用,浪潮信息工程师通过将这些scale参数量化到8位浮点数(FP8),可以显著减少所需的存储空间。在采用256为量化块大小(block size=256)的情况下,存储所有scale参数所需的额外空间仅为1.57GB:
(100B/64/256)* 4 + (100B/64) * 1 = 1.57GB
通过嵌套量化,模型的每个权重参数最终仅占用4字节的内存空间,这比原始的FP32存储方式减少了大量的内存占用,从内存到CPU的数据搬运效率提高了4倍。这样的优化显著减轻了内存带宽对Yuan2.0-102B模型推理解码效率的限制,从而进一步提升了模型的推理性能。
高算效,低成本
通过在NF8260G7服务器上应用张量并行和NF4量化技术,浪潮信息工程师成功实现了千亿大模型Yuan2.0-102B的实时推理,根据性能分析(profiling)的结果,可以清晰地看到模型中不同部分的计算时间分布:线性层运行时间占比50%,卷积运行时间占比20%,聚合通信时间占比20%,其它计算占比10%。在整个推理过程中,计算时间占比达到了80%,和此前相比,计算时间占比提升30%,大幅提升了算力利用率。
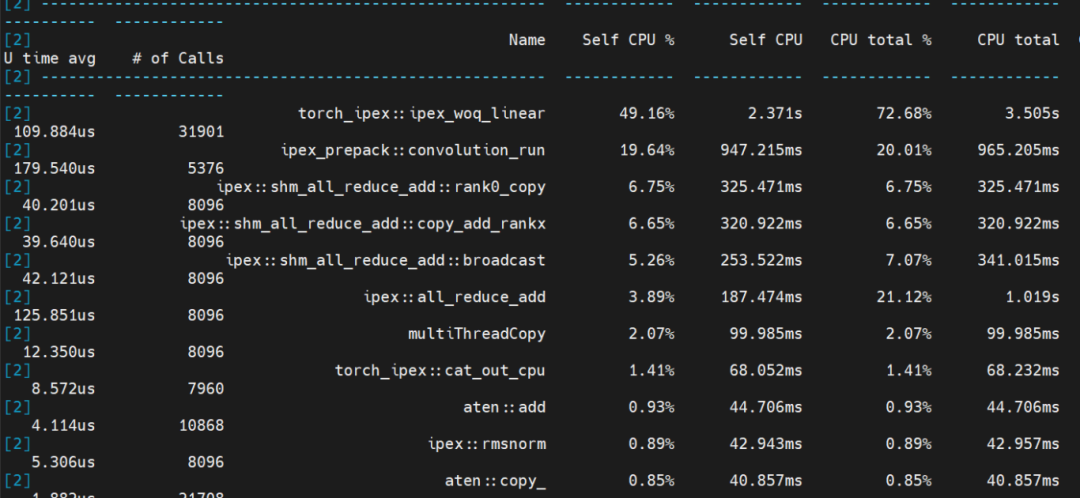
Yuan2.0-102B模型推理性能分析(profiling)结果图
浪潮信息基于通用服务器NF8260G7的软硬件协同创新,为千亿参数AI大模型在通用服务器的推理部署,提供了性能更强,成本更经济的选择,让AI大模型应用可以与云、大数据、数据库等应用能够实现更紧密的融合,从而充分释放人工智能在千行百业中的创新活力。
-
cpu
+关注
关注
68文章
11008浏览量
215093 -
服务器
+关注
关注
12文章
9588浏览量
86946 -
浪潮
+关注
关注
1文章
474浏览量
24343 -
大模型
+关注
关注
2文章
2929浏览量
3679
原文标题:服务器仅靠4颗CPU运行千亿大模型的“算法秘籍”
文章出处:【微信号:浪潮AIHPC,微信公众号:浪潮AIHPC】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
OPC服务器开发浅谈 — 服务器模型
用tflite接口调用tensorflow模型进行推理
通过Cortex来非常方便的部署PyTorch模型
浪潮AI服务器NF5488A5的实测数据分享,单机最大推理路数提升88%

使用MIG和Kubernetes部署Triton推理服务器
腾讯云TI平台利用NVIDIA Triton推理服务器构造不同AI应用场景需求
浪潮信息联合英特尔发布新一代AI服务器NF5698G7
浪潮信息NF5468服务器LLaMA训练性能
浪潮信息NF5468系列AI服务器率先支持英伟达最新推出的L40S GPU
源2.0适配FastChat框架,企业快速本地化部署大模型对话平台

摩尔线程宣布成功部署DeepSeek蒸馏模型推理服务
浪潮信息发布元脑R1推理服务器
昇腾推理服务器+DeepSeek大模型 技术培训在图为科技成功举办






 工商网监
工商网监
评论