 操作系统的内存布局介绍
操作系统的内存布局介绍
ARM32位系统的内存布局图
32位操作系统的内存布局很经典,很多书籍都是以32位系统为例子去讲解的。32位的系统可访问的地址空间为4GB,用户空间为1GB ~ 3GB,内核空间为3GB ~ 4GB。
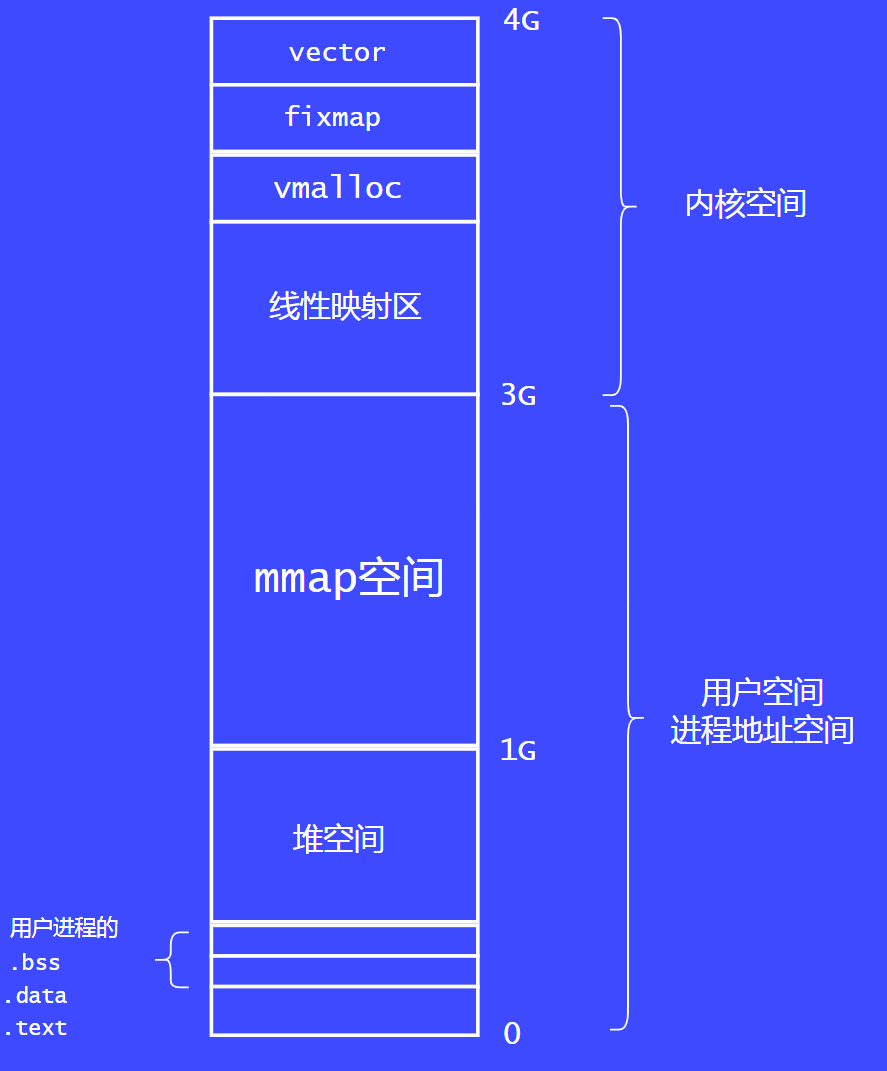
为什么要划分为用户空间和内核空间呢?
一般处理器会把运行模式分为好几个,比如x86分为rang0 ~ rang3级别。ARMv7架构中,又分为好几个模式,比如svc模式是给内核用的,usr模式是给用户态使用的。
当一个进程执行系统调用时,会陷入到内核态中,这个时候运行模式就从usr模式转换为svc模式,这就是我们常说的内核态。处于内核态的进程是可以访问内核空间的。所以就根据CPU的运行模式划分了两个空间。
我们先看下1GB的内核空间是怎么划分的,32位的系统中,通常配置的物理内存通常是大于1GB的,所以物理内存会划分为两部分,低端内存称为线性映射区,高端内存称为高端映射区。那这个分界线是怎么计算的呢,在ARM32中,分界线为760M。低端内存会做一比一映射到3GB ~ 3GB+760M。
这里讲的线性映射就是直接把物理内存的地址映射到线性映射区中,假设物理内存的DDR起始地址是0,映射的时候就有一个偏移量,这个偏移量就是0XC0000000,page offset。线性映射的地址我们就可以很方便的完成虚拟地址到物理地址的转换,只需要加减一个offset就可以。
高端内存的映射就没有线性映射那么简单了,使用高端内存时需要完成动态映射。
我们先看下1GB的内核空间剩下都做什么使用了。
vmalloc区域:分配的内存在虚拟地址是连续的,物理页面可以是离散的。vmalloc大概占用了200M物理内存。
fixmap:Fix map中的fix指的是固定的意思,那么固定什么东西呢?其实就是虚拟地址是固定的,也就是说,有些虚拟地址在编译(compile-time)的时候就固定下来了,而这些虚拟地址对应的物理地址不是固定的,是在kernel启动过程中被确定的。
vector:vector区域用于映射CPU vector page,大小一页4KB,从0xffff0000 - 0xffff1000。
接下来看下3GB用户空间的划分方式,一个进程要运行起来,必然要有自己的代码段和数据段,这部分在加载的时候就会被映射到虚拟地址。
堆空间:从进程的开始到1GB的这部分我们称为堆空间,这部分主要是给malloc使用的。
mmap空间:1GB到3GB这部分是给mmap空间使用的,mmap可以用来映射文件也可以映射匿名页面。通常用户态分配大段内存的时候,Linux通常会使用mmap来完成分配。
从进程的角度看内存布局
readelf 查看程序段
接下来,我们通过一个C语言程序学习下内存布局,这个例子很简单,用malloc函数分配了内存内存,然后使用memset将该区域清零。
使用gcc编译为elf后,可以使用readelf 查看该程序包含那些段。
#include#include #include #defineSIZE(100*1024) voidmain() { char*buf=malloc(SIZE); memset(buf,0x58,SIZE); while(1) sleep(10000); }
gcc-staticmemory_process.c-omemory_process.elf
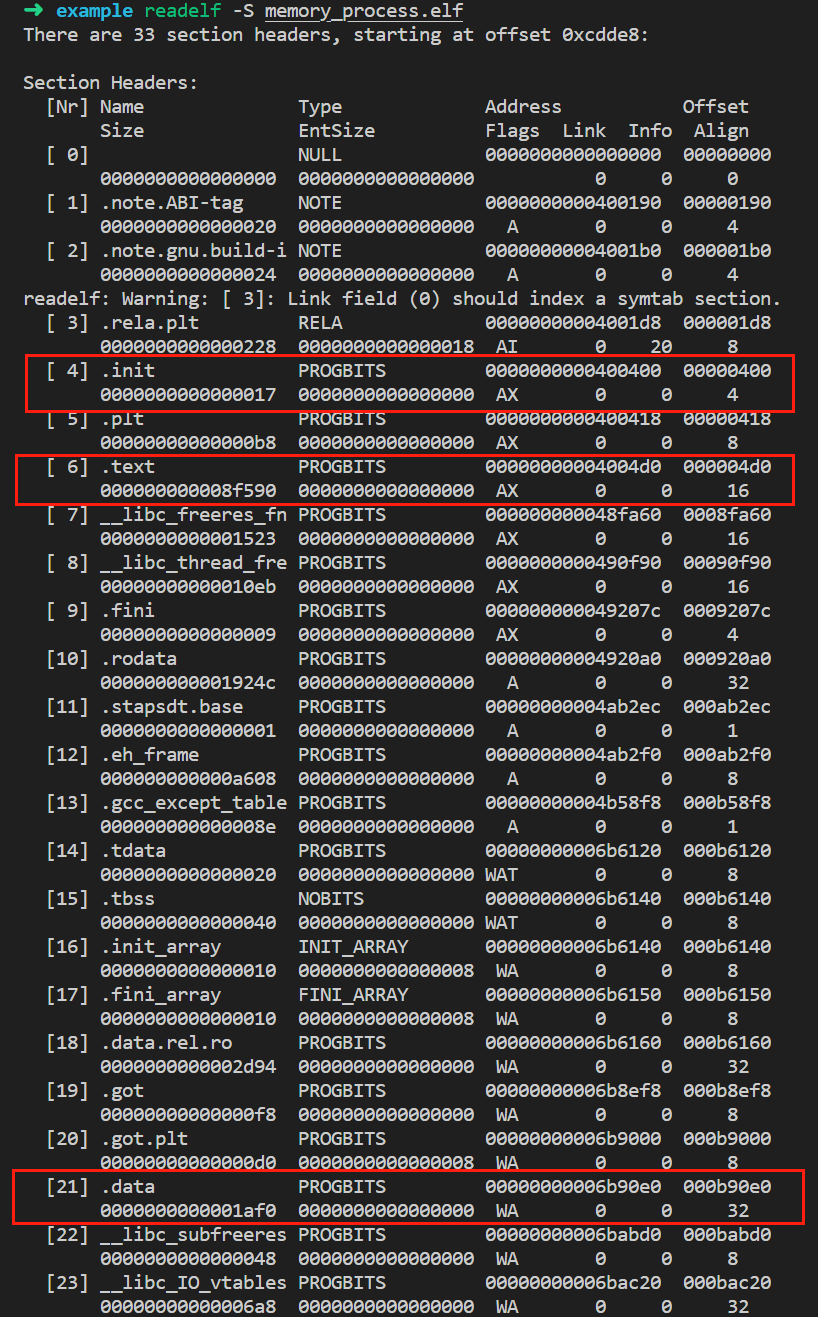
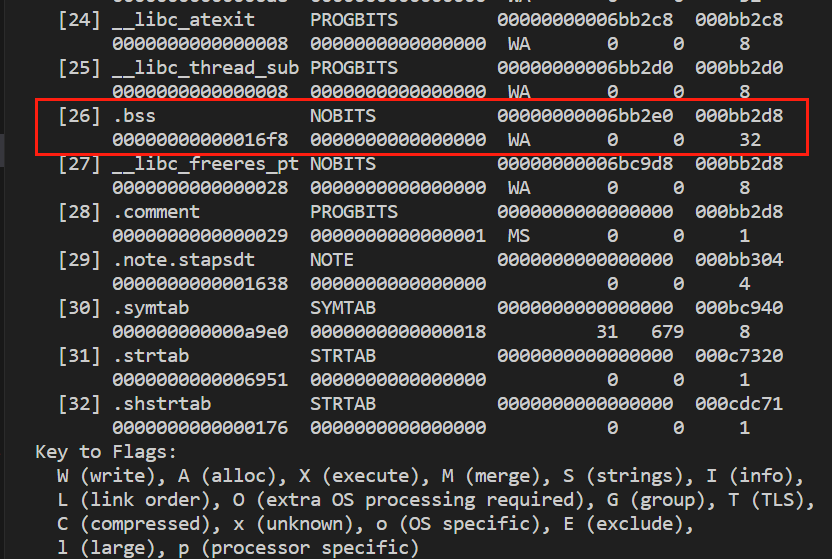
我们知道,通常Linux中流行的可执行文件的格式就是elf。使用gcc编译的elf就是我们讲的elf文件,目标文件除了包含了编译后的机器指令代码,还包含其他链接信息,比如符号表,调试信息,字符串等,通常这些信息会根据不同的属性存放在不同的段(section)中,这里我们只关注常见的段 。
.init:程序初始化的代码段。
.text:代码段,程序编译完后的机器指令。
.data:初始化过的全局的静态变量,还有一些局部的静态变量。
.rodata:只读变量,字符串,常量等。
.bss:未初始化的全局变量以及初始化为零的变量。
readelf 查看程序头
使用-l参数读下程序头(program header),它是用来描述OS是如何被映射到进程的虚拟地址空间的。
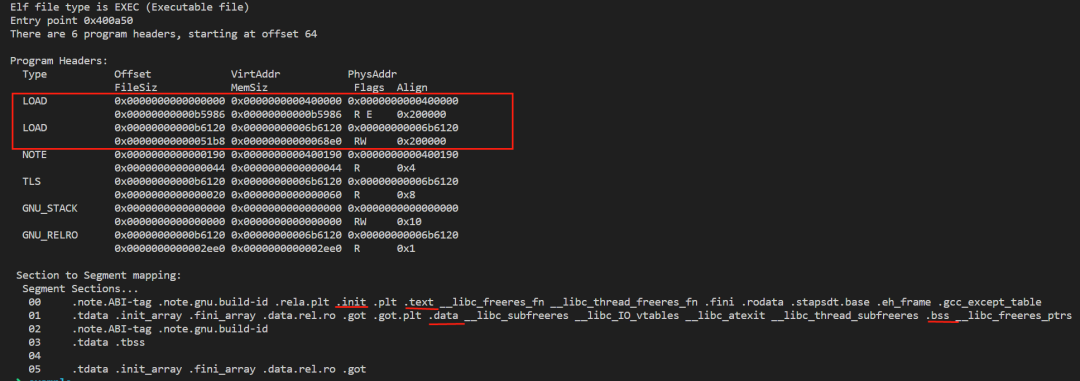
之前我们看到的30个段,在这里分成了7个族,并且显示每个族都包含那些段,这里我们只关注叫load的族,其他族主要是在程序装载的时候起到辅助作用。
第一个族里面包含init,text段,他的执行权限是只读,可执行的(RE)。起始地址0x0000000000400000,大小是0x00000000000b5986。
另外一个族主要包含data和bss段,他的执行权限是可读写(RW)。起始地址0x00000000006b6120,大小是0x00000000000051b8。
进程映射的过程

地址:本段在虚拟内存中的地址范围;对应vm_area_struct中的vm_start和vm_end。
权限:本段的权限; r-读,w-写,x-执行, p-私有;对应vm_flags。
偏移地址:即本段映射地址在文件中的偏移;对于有名映射指本段映射地址在文件中的偏移,对应vm_pgoff;对于匿名映射为vm_area_struct->vm_start。
主设备号与次设备号:所映射的文件所属设备的设备号,对应vm_file->f_dentry->d_inode->i_sb->s_dev。匿名映射为0。其中fd为主设备号,00为次设备号。
文件索引节点号:对应vm_file->f_dentry->d_inode->i_ino,与ls –i显示的内容相符。匿名映射为0。
映射的文件名:对有名映射而言,是映射的文件名,对匿名映射来说,是此段内存在进程中的作用。[stack]表示本段内存作为栈来使用,[heap]作为堆来使用,其他情况则为无。
smaps 可以查看更多的内容
➜examplecat/proc/5823/smaps 00400000-004b6000r-xp0000000008:012319863/home/zhongyi/code/example/memory_process.elf Size:728kB KernelPageSize:4kB MMUPageSize:4kB Rss:640kB Pss:640kB Shared_Clean:0kB Shared_Dirty:0kB Private_Clean:640kB Private_Dirty:0kB Referenced:640kB Anonymous:0kB LazyFree:0kB AnonHugePages:0kB ShmemPmdMapped:0kB FilePmdMapped:0kB Shared_Hugetlb:0kB Private_Hugetlb:0kB Swap:0kB SwapPss:0kB Locked:0kB THPeligible:0 VmFlags:rdexmrmwmedwsd 006b6000-006bc000rw-p000b600008:012319863/home/zhongyi/code/example/memory_process.elf Size:24kB KernelPageSize:4kB MMUPageSize:4kB Rss:24kB Pss:24kB Shared_Clean:0kB Shared_Dirty:0kB Private_Clean:8kB Private_Dirty:16kB Referenced:24kB Anonymous:16kB LazyFree:0kB AnonHugePages:0kB ShmemPmdMapped:0kB FilePmdMapped:0kB Shared_Hugetlb:0kB Private_Hugetlb:0kB Swap:0kB SwapPss:0kB Locked:0kB THPeligible:0 VmFlags:rdwrmrmwmedwacsd 006bc000-006bd000rw-p0000000000:000 Size:4kB KernelPageSize:4kB MMUPageSize:4kB Rss:4kB Pss:4kB Shared_Clean:0kB Shared_Dirty:0kB Private_Clean:0kB Private_Dirty:4kB Referenced:4kB Anonymous:4kB LazyFree:0kB AnonHugePages:0kB ShmemPmdMapped:0kB FilePmdMapped:0kB Shared_Hugetlb:0kB Private_Hugetlb:0kB Swap:0kB SwapPss:0kB Locked:0kB THPeligible:0 VmFlags:rdwrmrmwmeacsd 010cc000-010ef000rw-p0000000000:000[heap] Size:140kB KernelPageSize:4kB MMUPageSize:4kB Rss:108kB Pss:108kB Shared_Clean:0kB Shared_Dirty:0kB Private_Clean:0kB Private_Dirty:108kB Referenced:108kB Anonymous:108kB LazyFree:0kB AnonHugePages:0kB ShmemPmdMapped:0kB FilePmdMapped:0kB Shared_Hugetlb:0kB Private_Hugetlb:0kB Swap:0kB SwapPss:0kB Locked:0kB THPeligible:0 VmFlags:rdwrmrmwmeacsd 7ffd5e0db000-7ffd5e0fc000rw-p0000000000:000[stack] Size:132kB KernelPageSize:4kB MMUPageSize:4kB Rss:16kB Pss:16kB Shared_Clean:0kB Shared_Dirty:0kB Private_Clean:0kB Private_Dirty:16kB Referenced:16kB Anonymous:16kB LazyFree:0kB AnonHugePages:0kB ShmemPmdMapped:0kB FilePmdMapped:0kB Shared_Hugetlb:0kB Private_Hugetlb:0kB Swap:0kB SwapPss:0kB Locked:0kB THPeligible:0 VmFlags:rdwrmrmwmegdac 7ffd5e100000-7ffd5e103000r--p0000000000:000[vvar] Size:12kB KernelPageSize:4kB MMUPageSize:4kB Rss:0kB Pss:0kB Shared_Clean:0kB Shared_Dirty:0kB Private_Clean:0kB Private_Dirty:0kB Referenced:0kB Anonymous:0kB LazyFree:0kB AnonHugePages:0kB ShmemPmdMapped:0kB FilePmdMapped:0kB Shared_Hugetlb:0kB Private_Hugetlb:0kB Swap:0kB SwapPss:0kB Locked:0kB THPeligible:0 VmFlags:rdmrpfiodeddsd 7ffd5e103000-7ffd5e105000r-xp0000000000:000[vdso] Size:8kB KernelPageSize:4kB MMUPageSize:4kB Rss:4kB Pss:0kB Shared_Clean:4kB Shared_Dirty:0kB Private_Clean:0kB Private_Dirty:0kB Referenced:4kB Anonymous:0kB LazyFree:0kB AnonHugePages:0kB ShmemPmdMapped:0kB FilePmdMapped:0kB Shared_Hugetlb:0kB Private_Hugetlb:0kB Swap:0kB SwapPss:0kB Locked:0kB THPeligible:0 VmFlags:rdexmrmwmedesd ffffffffff600000-ffffffffff601000--xp0000000000:000[vsyscall] Size:4kB KernelPageSize:4kB MMUPageSize:4kB Rss:0kB Pss:0kB Shared_Clean:0kB Shared_Dirty:0kB Private_Clean:0kB Private_Dirty:0kB Referenced:0kB Anonymous:0kB LazyFree:0kB AnonHugePages:0kB ShmemPmdMapped:0kB FilePmdMapped:0kB Shared_Hugetlb:0kB Private_Hugetlb:0kB Swap:0kB SwapPss:0kB Locked:0kB THPeligible:0 VmFlags:ex
堆里面,匿名页面分配了108个物理内存,但我们的测试程序只分配了100k物理内存,这里匿名页面比分配的要大,这是因为进程在装载的时候也要消耗一些匿名页面。
010cc000-010ef000rw-p0000000000:000[heap] Size:140kB KernelPageSize:4kB MMUPageSize:4kB Rss:108kB Pss:108kB Shared_Clean:0kB Shared_Dirty:0kB Private_Clean:0kB Private_Dirty:108kB Referenced:108kB Anonymous:108kB LazyFree:0kB AnonHugePages:0kB ShmemPmdMapped:0kB FilePmdMapped:0kB Shared_Hugetlb:0kB Private_Hugetlb:0kB Swap:0kB SwapPss:0kB Locked:0kB THPeligible:0 VmFlags:rdwrmrmwmeacsd
根据以上信息,可以绘制出测试程序内存的布局图。
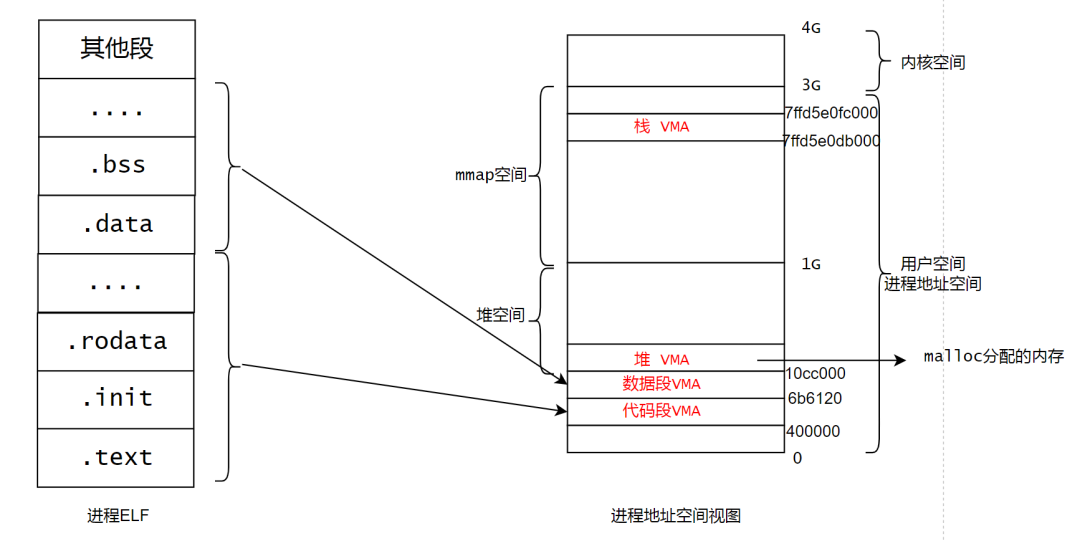
测试程序进程的elf这里只列出了常用的段。代码段的VMA属于page cache映射,这里把init段,text段,rodata段分为一个族,因为他们具有相同的权限,在进程加载的时候,会映射到代码段的VMA中。
数据段的VMA属于匿名映射,bss,data段具有相同的权限,在OS加载时,会映射到数据段的VMA中。
从数据段开始的地方就属于堆空间,我们在程序中用malloc分配了100K空间,这100K大小,也是在堆空间有对应的位置存在。
另外就是栈的VMA,进程有属于自己的VMA的栈。
以上就介绍了进程的ELF如何和进程的地址空间映射起来的。
64位系统的布局图
64位系统可以访问的空间就变得很大了。不过是ARM还是X86,实际的物理地址都不会用到64根地址线,通常是使用了48根地址线。而且,划分的用户空间和内核空间都是非常大的。
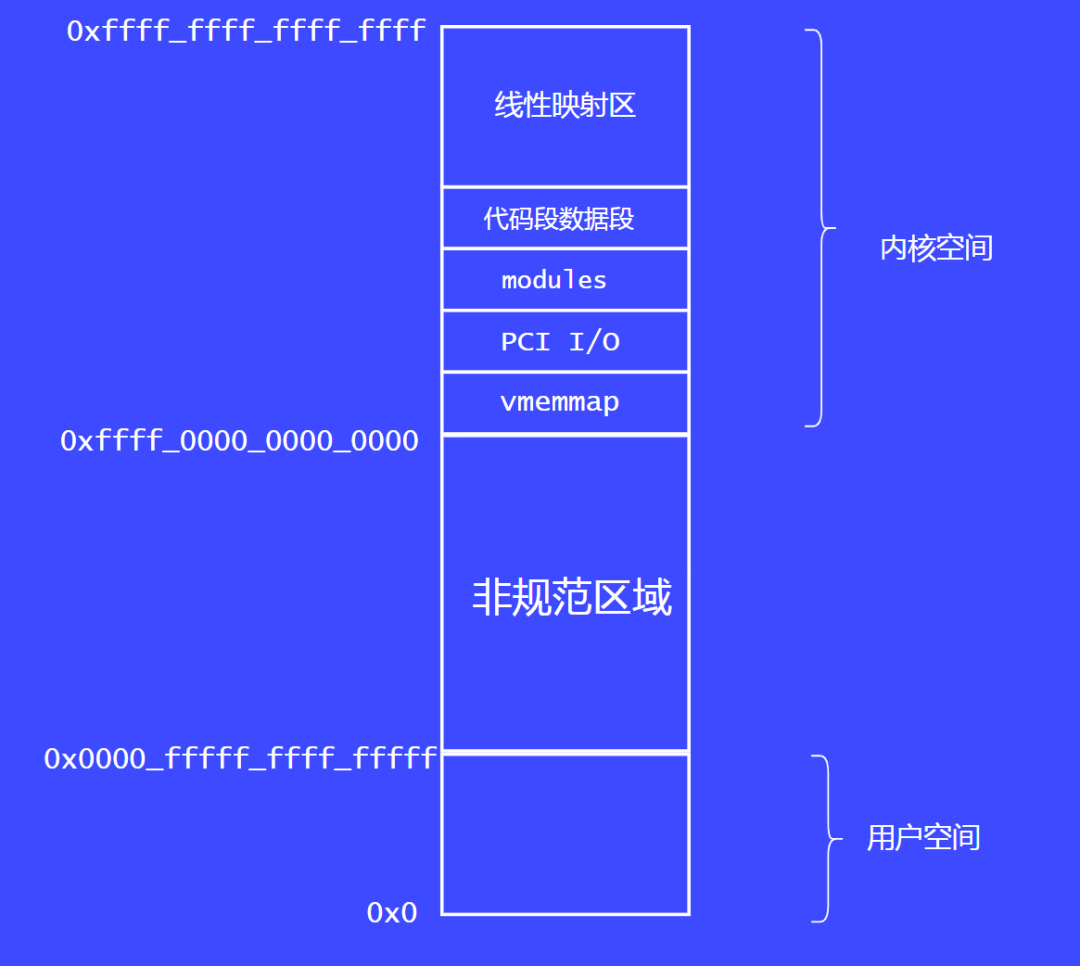
大家可以看这张图,把空间分为了三部分,一部分是内核空间,一部分是非规范区域(大家都不使用的),最后是用户空间。
用户空间:0x0000_0000_0000_0000到0x0000_ffff_ffff_ffff,一共有256TB。
非规范区域
内核空间:0xffff_0000_0000_0000到0xffff_ffff_ffff_ffff。一共有256TB。
内核空间又做了如下细分:
vmalloc区域:vmalloc函数使用的虚拟地址空间,kernel image也在vmalloc区域,内核镜像的起始地址 = KIMAGE_ADDR + TEXT_OFFSET, TEXT_OFFSET是内存中的内核镜像相对内存起始位置的偏移。
vmemmap区域:内存的物理地址如果不连续的话,就会存在内存空洞(稀疏内存),vmemmap就用来存放稀疏内存的page结构体的数据的虚拟地址空间。
PCI I/O区域:pci设备的I/O地址空间
Modules区域:内核模块使用的虚拟地址空间
normal memory线性映射区:范围是【0xffff_8000_0000_0000, 0xffff_ffff_ffff_ffff】, 一共有128TB, 但这里代码对应的是memblock_start_of_DRAM()和memblock_end_of_DRAM()函数。memory根据实际物理内存大小做了限制,所以memroy显示了实际能够访问的内存区。
MLM(__phys_to_virt(memblock_start_of_DRAM()),(unsignedlong)high_memory)) high_memory=__va(memblock_end_of_DRAM()-1)+1;
最终是通过dts或acpi中配置的memory节点确定的。
-
处理器
+关注
关注
68文章
19461浏览量
231415 -
ARM
+关注
关注
134文章
9184浏览量
369733 -
操作系统
+关注
关注
37文章
6905浏览量
123871 -
内存管理
+关注
关注
0文章
168浏览量
14204
原文标题:【内存管理】内存布局介绍
文章出处:【微信号:嵌入式与Linux那些事,微信公众号:嵌入式与Linux那些事】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Symbian和WinCE操作系统的内存管理技术研究



介绍ThreadX操作系统
ThreadX操作系统介绍
Windows XP操作系统内存条优化指南
虚拟内存在操作系统(Linux)中的实现
什么是内存 操作系统内存介绍





 工商网监
工商网监
评论