 通过多样的几何形状来训练机器人从仿真到现实转换的装配技能
通过多样的几何形状来训练机器人从仿真到现实转换的装配技能
家庭和工业环境中的大多数物品都由多个部件组装而成。而装配工作一般交给人工,但在汽车等一些行业,机器人装配已十分普遍。
这些机器人大多用于执行重复性较高的任务,它们被部署在精心设计的环境中,处理特定的部件。在多品种的小批量制造中(即小批量生产各种产品的流程),机器人还必须适应不同的零件、姿态和环境。在保持高精度和高准确度的前提下实现这种适应性是机器人技术所面临的一大挑战。
得益于 NVIDIA 在接触丰富交互的超实时仿真技术方面的最新进展,现在已经可以对机器人装配任务(如插入等)进行仿真,详见通过使用 NVIDIA Isaac 的新型仿真方法推进机器人装配技术发展。这使得使用数据饥渴的学习算法来训练仿真机器人智能体成为可能:
https://developer.nvidia.com/blog/advancing-robotic-assembly-with-a-novel-simulation-approach-using-nvidia-isaac/
后续关于机器人装配从仿真到现实的迁移研究提出了使用强化学习 (RL) 在仿真中解决少量装配任务的算法,以及在现实世界中成功部署所学技能的方法。详见将工业机器人装配任务从仿真迁移到现实:
https://developer.nvidia.com/blog/transferring-industrial-robot-assembly-tasks-from-simulation-to-reality/
本文将介绍 AutoMate,这一新型框架被用来训练使用机械臂装配不同形状零件的专家和通才策略;然后对训练策略从仿真到现实的零样本迁移进行演示,这意味着无需额外调整在仿真中学习到的装配技能,即可直接应用于现实环境。
什么是 AutoMate?
AutoMate 是首个基于仿真的框架,用于学习各种装配任务中的专业(部件特定)和通用(统一)装配技能。例如:在汽车制造领域,AutoMate 可以帮助工人掌握发动机部件的特定装配技巧以及整车的统一装配流程。这项工作成果来自于南加州大学与 NVIDIA 西雅图机器人实验室的密切合作。
AutoMate 的主要贡献有:
100 个装配体和现成仿真环境的数据集。
一种有效训练仿真机器人解决各种仿真装配任务的新型算法组合。
有效综合各种学习方法,将多种专业装配技能的知识提炼成一种通用装配技能,并通过 RL 进一步提高通用装配技能的性能。
一个能够在以感知为初始的工作流中,部署通过仿真训练获得的装配技能的真实世界系统。
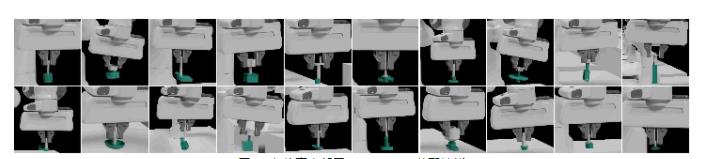
图 1. 在仿真中部署 AutoMate 装配技能

图 2. 在现实中部署 AutoMate 装配技能
数据集和仿真环境
AutoMate 提供了一个包含 100 个装配体的数据集,这些装配体与仿真兼容,并可以在现实世界中进行 3D 打印。同时,它还为所有 100 个装配体提供了并行化仿真环境。这 100 个装配体基于 Autodesk 的大型装配体数据集。在这项工作成果中,术语“插头”指的是必须插入的部件(图 3 中用白色表示),“插座”指的是与插头配合的部件(图 3 中用绿色表示)。

图 3. AutoMate 数据集中 100 个装配体的可视化图

图 4. AutoMate 数据集中的装配体仿真环境
在多种形状上学习专家技能
尽管 NVIDIA 之前的工作成果 IndustReal 表明,纯 RL 方法可以解决接触丰富的装配任务,但它只能解决一小部分装配体。在 AutoMate 数据集中的 100 个装配体中,大部分都无法通过纯 RL 方法解决。但仿真学习可以让机器人通过观察和模仿演示来习得复杂的技能。AutoMate 引入了包含三种不同算法的新型组合。该组合通过将 RL 与仿真学习相结合,使机器人能够有效掌握适用于各种装配体的技能。
使用仿真学习增强 RL 面临以下三个挑战:
生成装配演示
将仿真学习目标整合到 RL 中
选择在学习过程中使用的演示
下文将探讨如何逐一解决这三个挑战。
利用拆解-组装来生成示范
装配运动学是一个狭窄通道问题,机器人必须操纵部件通过狭窄空间,并且不能与障碍物相撞。使用运动规划器自动采集装配演示非常困难。要采集人类演示,还需要有技能娴熟的人类操作员和先进的远程操作界面,而这些都十分昂贵。
“拆解-组装”的概念告诉我们,在装配一个物体前,首先要了解如何拆卸它。受到这一概念的启发,可以先采集拆卸演示,然后按相反步骤操作便可进行装配。在仿真中,命令机器人将插头从插座上拆下,每个装配体记录 100 次成功的拆卸演示。

图 5. 在仿真中生成拆卸演示的过程
带有模仿目标的 RL
RL 中的奖励是向智能体发出的一个信号,该信号表明智能体在规定步骤中的表现有多好。奖励可作为反馈,指导智能体学习和调整其行动,以逐渐使其累积奖励最大化(从而成功完成任务)。受 DeepMimic 等角色动画工作成果的启发,奖励函数中加入了一个模仿项,以便通过模仿目标增强 RL,鼓励机器人在学习过程中模仿演示。每个时间步的模仿奖励被定义为规定装配体所有演示的最大奖励。
除了模仿项,奖励公式中还包含以下项:
目标距离惩罚
仿真误差惩罚
奖励任务难度
这与之前的 InsutReal 工作相一致。
通过动态时间扭曲来选择演示
如要确定模仿哪个演示(即哪个演示在当前时间步提供最大奖励),第一步是计算每个演示与当前机器人末端执行器路径之间的距离,然后模仿距离最小的路径。与机器人末端执行器路径相比,演示路径的路径点分布可能不均匀,路径点数量也可能不同,因此很难确定演示路径中的路径点与机器人末端执行器路径之间的对应关系。
动态时间扭曲 (DTW) 是一种用于测量两个速度可能不同的时间序列之间相似性的算法。在这项工作中,DTW 被用于找出机器人末端执行器路径和每个演示路径之间的映射,从而使末端执行器路径上的每个路径点与演示路径上的匹配路径点之间的距离总和最小(图 6)。根据 DTW 返回的距离,计算每条演示路径的模仿奖励,并选择模仿奖励最高的演示路径。
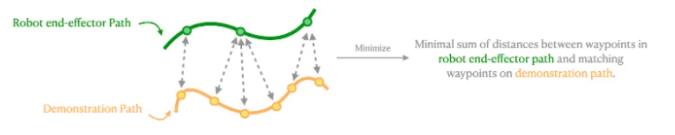
图 6. DTW 将末端执行器路径与演示路径之间的映射可视化
所提出的拆解-组装组合、带有模仿目标的 RL 和使用 DTW 匹配轨迹的组合方法在各种装配体中都表现出一致的性能。在仿真中,专家策略在 80 个不同装配体上的成功率约为 80% 以上,在 55 个不同装配体上的成功率约为 90% 以上。在现实世界中,专家策略在 20 个组件上的平均成功率为 86.5%,比在仿真中用于这些组件时仅下降了 4.2%(图 7)。
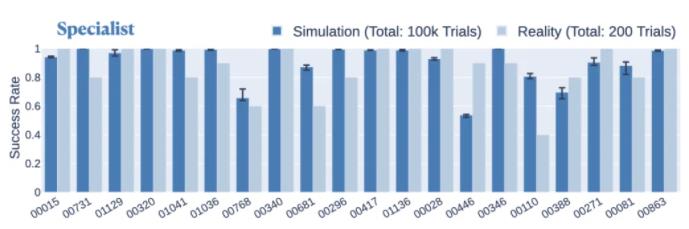
图 7. 专家策略在现实世界与仿真中解决每个装配体的成功率比较
学习通用装配技能
为了训练一种能够解决多种装配任务的通用技能,需要重新使用已训练的专家技能中的知识,然后使用基于课程的 RL 进一步提高性能。所提出的方法包含三个阶段:
首先,使用标准行为克隆 (BC),即从已经训练过的专家技能中采集演示,并使用这些演示监督通才技能的训练。
随后,使用 DAgger(数据集聚合)完善通才技能,方法是执行通才技能,并在通才技能访问的状态下主动查询专家技能(即获取专家技能预测的操作)以进行监督。
最后,对通才技能执行 RL 微调阶段。在微调阶段,使用 IndustReal 工作中基于采样的课程。随着通才技能任务成功率的提高,部件的初始参与度会逐渐降低。
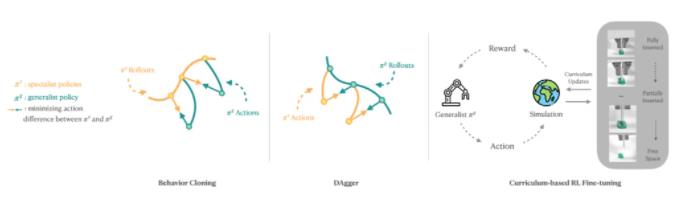
图 8. 行为克隆、DAgger 和基于课程的 RL 微调示意图
使用刚才提出的三阶段方法在 20 个装配体上进行通才技能训练。在仿真中,通才策略可以联合解决 20 个装配体,成功率为 80.4%。在现实世界中,通才策略在同一组装配体上的平均成功率为 84.5%,比在仿真中提高了 4.1%(图 9)。
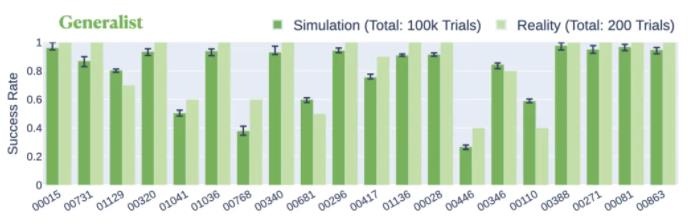
图 9. 通才策略在现实世界和仿真中解决每个装配体的成功率比较
现实世界环境和感知初始化工作流
现实世界环境包括一个 Franka Panda 机械臂、一个安装在手腕上的英特尔 RealSense D435 摄像头、一个 3D 打印插头和插座,以及一个用于固定插座的 Schunk EGK40 抓取器。在感知初始化工作流中:
插头被随意放置在泡沫块上,插座被随意放置在 Schunk 抓取器中。
通过安装在手腕上的摄像头捕捉 RGB-D 图像,然后对部件进行 6D 姿态估计 (FoundationPose)。
机器人抓取插头、将其移动到插座上,并使用在仿真中训练的装配技能。
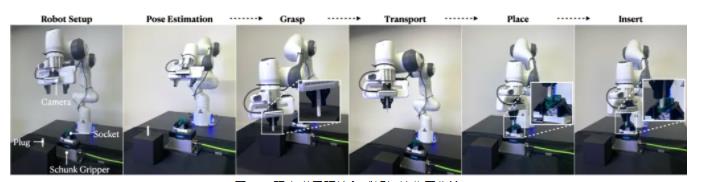
图 10. 现实世界环境和感知初始化工作流
专家和通才技能在感知初始化工作流中被进行评估。专家技能的平均成功率为 90.0%,通才技能的成功率为 86.0%。这些结果表明,6-DOF 姿态估计、抓取优化和所提出的学习专家和通才策略的方法可以有效结合,从而在现实条件下使用研究级硬件实现可靠的装配。
总结
AutoMate 是我们第一次尝试利用学习方法和仿真来解决各种装配问题。通过这项工作,NVIDIA 研究人员立足于现实世界的部署,逐步建立了工业机器人的大型模型范例。
未来的工作重点是解决需要高效序列规划(即决定下一个装配部件)的多部件装配体,并进一步提高技能,以达到具有行业竞争力的性能指标。
-
机器人
+关注
关注
212文章
28887浏览量
209512 -
NVIDIA
+关注
关注
14文章
5103浏览量
104342 -
仿真
+关注
关注
50文章
4151浏览量
134407 -
工业机器人
+关注
关注
91文章
3393浏览量
93084
原文标题:通过多样的几何形状来训练机器人从仿真到现实转换的装配技能
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
全国首个异构人形机器人训练场启用
物理仿真人形机器人的统一全身控制策略

《具身智能机器人系统》第10-13章阅读心得之具身智能机器人计算挑战
【「具身智能机器人系统」阅读体验】2.具身智能机器人大模型
【「具身智能机器人系统」阅读体验】1.初步理解具身智能
《具身智能机器人系统》第7-9章阅读心得之具身智能机器人与大模型
【「具身智能机器人系统」阅读体验】+数据在具身人工智能中的价值
【「具身智能机器人系统」阅读体验】+初品的体验
NVIDIA通过加速AWS上的机器人仿真推进物理AI的发展
“0元购”智元灵犀X1机器人,软硬件全套图纸和代码全公开!资料免费下载!
在NVIDIA Isaac Lab中训练四足机器人运动





 工商网监
工商网监
评论