 NVIDIA文本嵌入模型NV-Embed的精度基准
NVIDIA文本嵌入模型NV-Embed的精度基准
NVIDIA 的最新嵌入模型 NV-Embed —— 以 69.32 的分数创下了嵌入准确率的新纪录海量文本嵌入基准测试(MTEB)涵盖 56 项嵌入任务。
NV-Embed 等高度准确有效的模型是将大量数据转化为可操作见解的关键。NVIDIA 通过 NVIDIA API 目录提供性能一流的模型。
由 LLM 提供支持的“与您的数据对话”流程严重依赖 embedding model,例如 NV-Embed,它通过将英语单词转换为文本中信息的压缩数学表示形式来创建非结构化文本的语义表示。这种表示通常存储在 vector database 中,以便日后使用。
当用户提出问题时,系统会对问题的数学表征和所有基础数据块进行比较,以检索最有用的信息来回答用户的问题。
请注意,此特定模型只能用于非商业用途。
分解基准
在讨论模型的准确率数字之前,讨论基准测试很重要。本节简要介绍有关理解基准测试的详细信息。我们的深入探讨评估适用于企业级 RAG 的 Retriever 是获取更多信息的绝佳资源。
了解嵌入模型的指标
从我们将讨论的基准测试指标开始,主要有两个注意事项:
Normalized Discounted Cumulative Gain(NDCG)是一个排名感知指标,用于衡量检索到的信息的相关性和顺序。简言之,如果我们有 1,000 个 chunks 并检索 10 (NDCG@10),那么当最相关的 chunk 排名第一、第二相关的 chunk 排名第二,以此类推,直到第十个最相关的 chunk 位于第 10 位时,才会给出理想的分数。
Recall是一个与排名无关的指标,用于测量检索到的相关结果的百分比。在这种情况下,如果我们有 1,000 个数据块并检索 10 个数据块(Recall@10),则如果选择了前 10 个最相关的数据块,则无论这些数据块的排名顺序如何,都将获得完美分数。
大多数基准测试都报告 NDCG@10,但由于大多数企业级检索增强生成(RAG)流程,我们建议使用 Recall@5。
什么是 MTEB 和 Beir?
检索流程的核心功能是将问题的语义表示与各种数据点进行比较。这自然会引导开发者提出几个后续问题:
相同的表示是否可以用于不同的任务?
如果我们缩小一项任务的范围,该模型是否擅长表示不同类型的问题或理解不同领域?
为了回答这些问题,我们研究了有关检索的文献中最常见的两个基准测试。
MTEB:此基准测试涵盖 56 项不同的任务,包括检索、分类、重新排名、聚类、总结等。根据您的目标,您可以查看代表您用例的精确任务子集。
BEIR:该基准测试专注于检索任务,并以不同类型和领域的问题(例如 fact-checking、biomedical questions 或检测重复性问题)的形式增加了复杂性。MTEB 在很大程度上是 BEIR 基准测试的超集,因此我们在大多数讨论中将专注于 MTEB。
NV-Embed 模型精度基准
现在我们已经讨论了基础基准测试和指标,我们来看看新模型 NV-Embed 的执行情况。
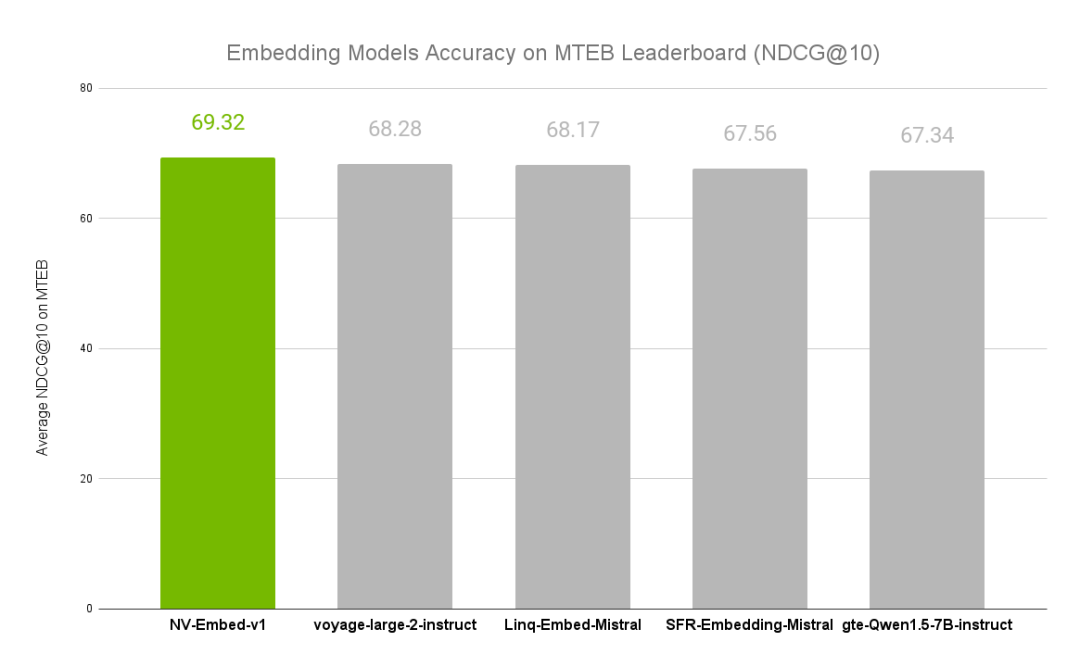
图 1. MTEB 基准测试中排名前 5 的模型
平均而言,NV-Embed 模型在 56 个任务中的跟踪准确度最佳,NDCG@10 分为 69.32(参见图 1)。
虽然 NV-Embed 涵盖了大多数模型架构和训练细节,准确率达到 69.32,以下总结了主要改进。
新的 latent attention layer。我们引入了 latent attention layer,该层能够简化模型将一系列词(tokens sequence)的数学表示(embeddings)的过程。通常情况下,对于基于 BERT 的模型,这是通过求平均值来完成的,对于仅解码器的模型,则是通过关注 End-of-Sequence-Token(
两阶段学习过程。在第一阶段,使用 in-batch 负例对和 hard 负例对进行 contrastive 学习。简而言之,使用证据对和问题对。证据似乎回答了这些对中的问题,但如果您仔细观察,您会发现缺少基本信息。在第二阶段,来自非检索任务的数据混合在一起以进行 contrastive 学习,并且禁用 in-batch 负例训练。
现在自然而然的问题是,“这对我的企业检索工作负载的转换效果有多好。”
答案是,它取决于数据的性质和领域。对于每个基准测试,您必须评估单个数据集的相关性一般检索用例。
我们的关键要点是,虽然 19 个数据集构成了 BEIR 基准测试,但数据集 Quora 其中包含超出常规检索任务的问题。因此,我们建议查看更能代表工作负载的数据集子集,例如 Natural Questions 和 HotPotQA 数据集。有关上下文,请参阅以下代码段。
Quora 示例数据集的数据对专注于检索 Quora 上提出的其他类似问题。
Input:Which question should I ask on Quora?
Target:What are good questions to ask on Quora?
HotpotQA 示例问题通道对
Input-Question:Were Scott Derrickson and Ed Wood of the same nationality?
Target-Chunk:Scott Derrickson (born July 16, 1966) is an American director, screenwriter and producer. He lives in Los Angeles, California. He is best known for directing horror films such as “Sinister”, “The Exorcism of Emily Rose”, and “Deliver Us From Evil”, as well as the 2016 Marvel Cinematic Universe installment, “Doctor Strange.”
NQ 示例常规问题通道对
Input-Question: What is non-controlling interest on the balance sheet?
Target-Chunk:In accounting, minority interest (or non-controlling interest) is the portion of a subsidiary corporation’s stock that is not owned by the parent corporation. The magnitude of the minority interest in the subsidiary company is generally less than 50% of outstanding shares, or the corporation would generally cease to be a subsidiary of the parent.[1]
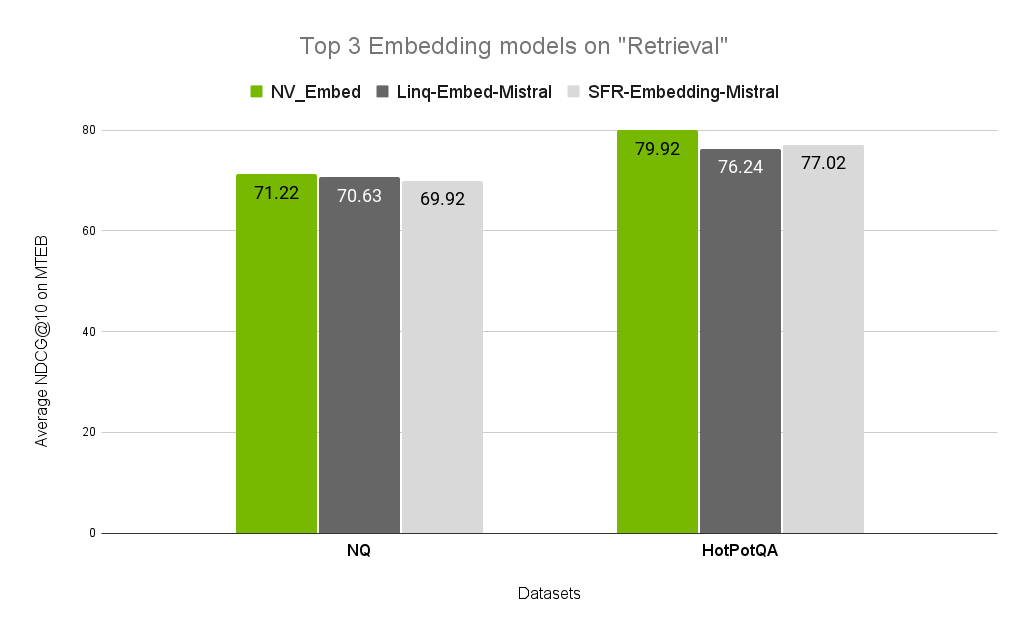
图 2. HotPotQA 和 NQ 上来自 MTEB 的前三个嵌入模型,它们很好地代表了通用检索用例
在图 2 中,NV-Embed 模型最适合用于表示这些用例的数据集。我们鼓励您对自己的数据重复此评估。如果您没有要测试的干净数据,我们建议找到表示您用例的子集。
立即开始原型设计
通过 API 目录体验 NV-Embed 模型。
此外,使用 NVIDIA NeMo Retriever 微服务集合,该集合旨在使组织能够将自定义模型无缝连接到各种业务数据,并提供高度准确的响应。
-
NVIDIA
+关注
关注
14文章
5087浏览量
103916 -
API
+关注
关注
2文章
1522浏览量
62506 -
模型
+关注
关注
1文章
3372浏览量
49314
原文标题:NVIDIA 文本嵌入模型位列 MTEB 排行榜榜首
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
是否有来自NVIDIA的基准测试
NVIDIA 在首个AI推理基准测试中大放异彩
NVIDIA Jetson的相关资料分享
在Ubuntu上使用Nvidia GPU训练模型
如何使用TensorFlow Hub文本模块构建一个模型,以根据相关描述预测电影类型

基于词嵌入与神经网络的文本匹配模型
基于LSTM的表示学习-文本分类模型
NVIDIA Jetson Orin Nano的性能基准
GTC 2023主题直播:NVIDIA Nemo构建定制的语言文本转文本

GTC23 | 使用 NVIDIA TAO Toolkit 5.0 体验最新的视觉 AI 模型开发工作流程
NVIDIA AI 技术助力 vivo 文本预训练大模型性能提升

基于文本到图像模型的可控文本到视频生成






 工商网监
工商网监
评论