 Vivado 2017.1和Vivado 2016.4性能对比分析
Vivado 2017.1和Vivado 2016.4性能对比分析
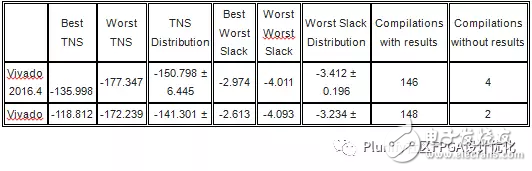
分别进行了3个Vivado 2017.1对Vivado2016.4的性能测试。总体而言,Vivado 2017.1比Vivado2016.4给出了更好的效果。虽然在测试1中的结果有些相似,但是Vivado2017.1从测试2和3中获得的最佳TNS总负余量和WS最差余量却比Vivado2016.4要好得多。
方法Methods
此性能测试我们将使用名为“CPU”的设计,目标器件为“XC7K70TFBG676-2”。
比较2个工具链版本之间将通过以下测试进行:
用于编译的设置将通过InTime使用Vivado2016.4生成。Vivado 2017.1将使用相同的设置进行编译。
用于编译的设置将通过InTime使用Vivado2017.1生成。 Vivado 2016.4将使用相同的设置进行编译。
对于每个测试,每个工具链版本共做了150个编译。InTime的特点是从过去的结果中学习,因此在测试这些工具链的性能时必须考虑这一点。通过运行相同的实验两次,然后可以分析InTime从不同的工具链版本中学习到的结果是好坏。
测试Experiment 1
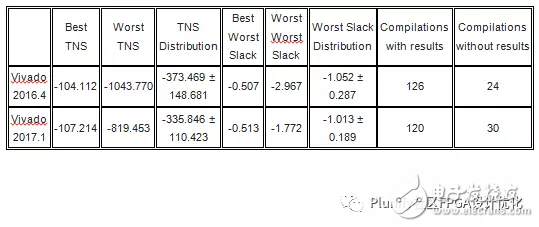
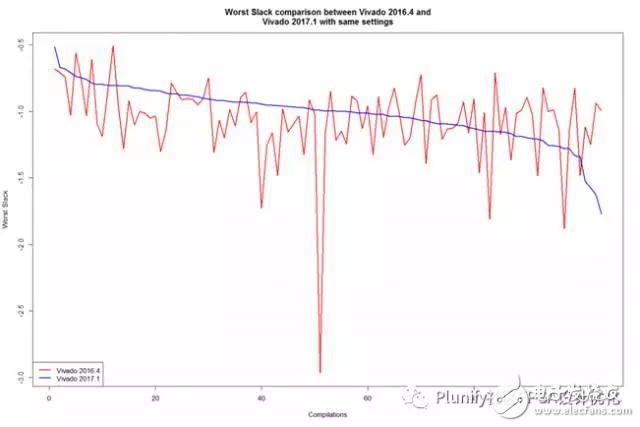
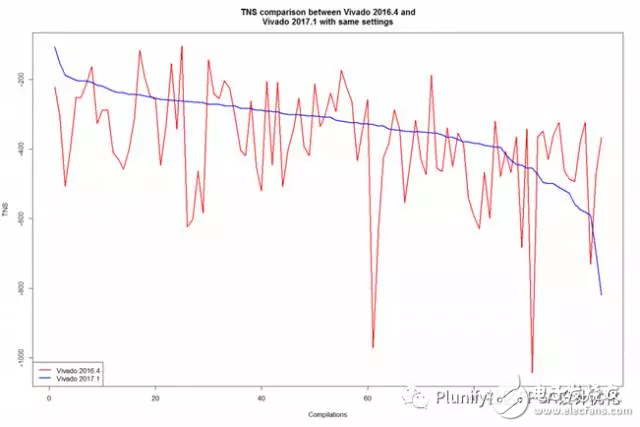
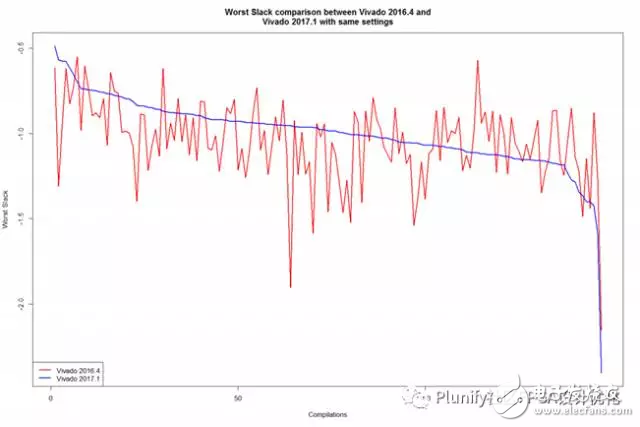
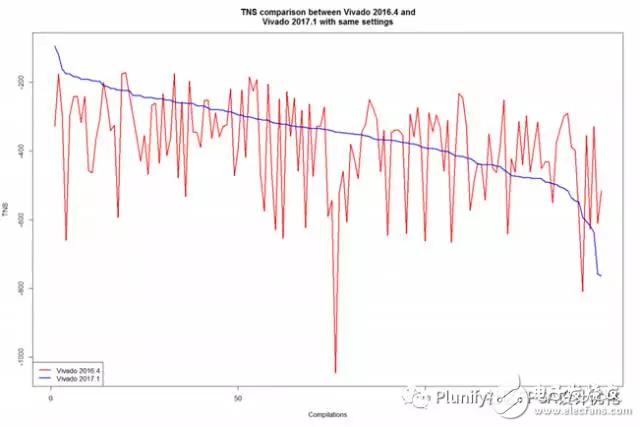
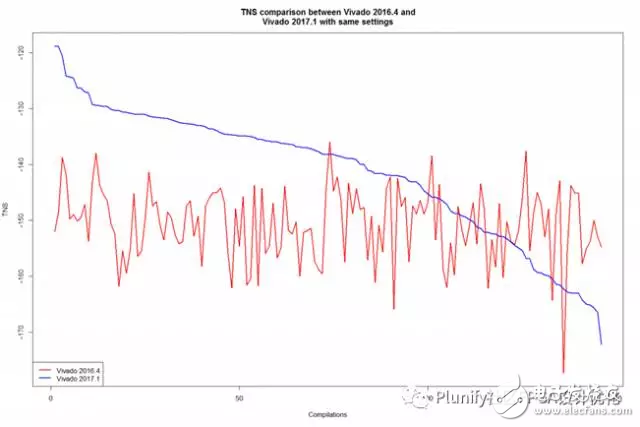
下面表格里列出了此测试结果的一些基本统计信息,而图表显示了两个工具链版本的每个编译后的TNS总负余量和WS最差余量。参阅表的分析显示,两个工具链版本的最佳TNS实际上非常相似。然而Vivado 2017.1的WS最差余量表现出更好的数据。与Vivado 2016.4相比,Vivado 2017.1的TNS总负余量和WS最差余量的分布更低,更少变化,表明最新版本的Vivado工具链更稳定和产出更好数据,虽然略好于以前的版本。
看看图表,我们可以看出,Vivado 2016.4(红线)的糟糕结果在Vivado 2017.1(蓝线)方面实际上有所改善。另一方面,Vivado 2016.4的好结果在新版Vivado中实际上变得更糟。总体看来,Vivado 2017.1的表现似乎比Vivado 2016.4好一些。
测试Experiment 2
此测试与前面的报告格式相似。在本测试中,Vivado 2017.1还是优于Vivado2016.4。我们可以看到Vivado 2016.4(红线)的结果都趋低于Vivado2017.1的结果(蓝线)。这表明较新的工具链通常会产生更好的结果。
另外,你可能会注意到,测试2的成功编译数量远远高于测试1。这表明Vivado 2017.1产生的结果与设置有较高的相关性,这允许InTime学习并避免不成功的编译。
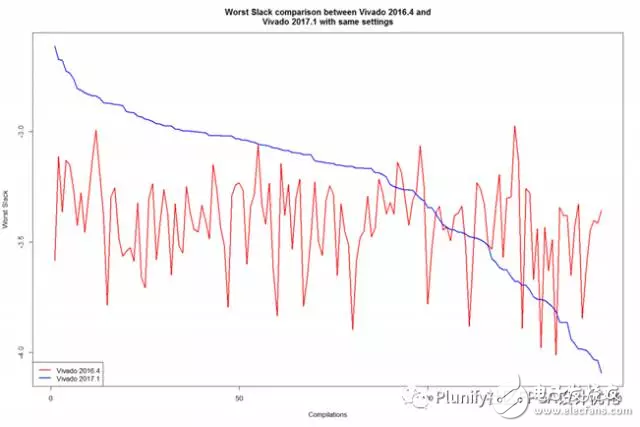
比较eight_bit_uc八位数设计
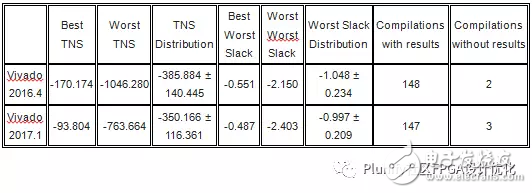
在得出任何结论之前,我们将其结果与另一种设计进行比较。在第三个测试中,我们用“eight_bit_uc八位数”设计(目标器件“XC7K70TFBG484-2”)重复测试一。结果报告如下,并与先前的两个测试相同--Vivado 2017.1几乎在所有方面都优于Vivado 2016.4。
总结
Vivado 2017.1比Vivado 2016.4获得了更好的效果。虽然在测试1中的结果有些相似,但是从Vivado 2017.1获得的最佳TNS总负余量和WS最差余量在测试2和3中要比Vivado 2016.4好得多。
想要试一下Plunify InTime FPGA 优化功能?对它的使用详情与报表功能感兴趣?
-
Vivado
+关注
关注
19文章
815浏览量
66867
发布评论请先 登录
相关推荐
请问为什么Vivado 2017.1无法连接ZC702板?
Vivado 2016.4比特流崩溃
Vivado 2016.4发生意外错误(11)
2017.1 VIVADO崩溃
下载Xilinx Vivado 2017.1时出错
Vivado 2016.4合成错误
Vivado Design Suite 2017.1的五大方法介绍
Vivado 2017.1 的 HLx 版本已可下载_两大特色先知道
Vivado Design Suite 2017.1套件的新外观与功能介绍
Vivado Design Suite 2017.1的新功能介绍






 工商网监
工商网监
评论