 如何推动智能视觉技术发展
如何推动智能视觉技术发展
(鸣谢 Arm 工程部计算视觉主任架构师 Catherine Wang 对本文内容的贡献)
语言学和认知科学的先驱 Noam Chomsky 曾经说过,人类语言在动物世界中是独一无二的。如今,随着诸如 GPT-3.5、GPT-4.0 和 Bert 等大语言模型 (LLM) 和生成式人工智能 (AI) 的迅猛发展,机器已经开始能够理解人类语言,这极大地扩展了机器可行使的功能。由此也引发了人们的思考:接下来技术会如何发展?
智能的演进塑造全新计算范式
要预测 AI 的未来发展方向,我们只需反观人类自身。我们通过感官、思想和行动的相互动态作用来改变世界。这个过程包括感知周围世界、处理信息,并在深思熟虑后作出回应。
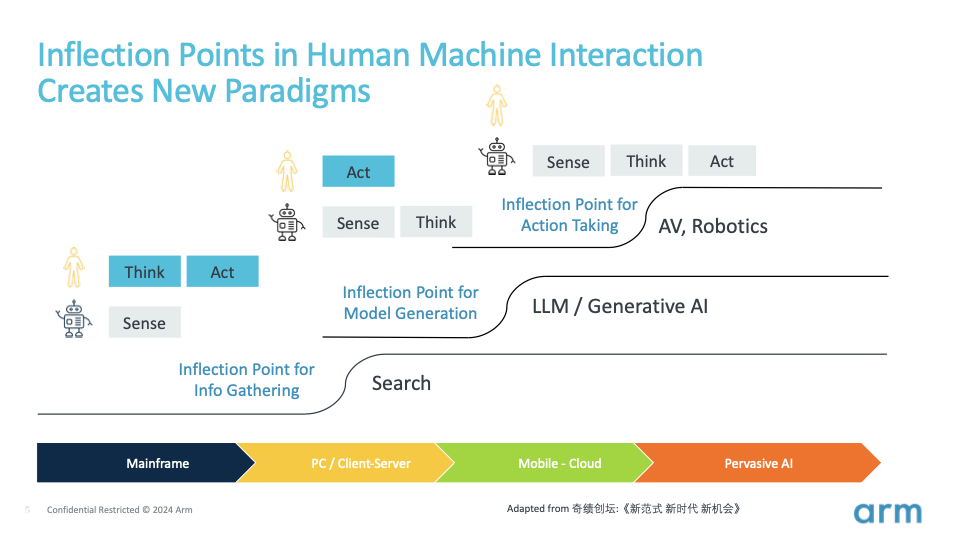
在计算技术的发展历程中,我们目睹了曾经是人类独有的感知、思考和行动等能力,逐渐被机器所掌握。每一次能力的转移都将催生出新的范式。
20 世纪末,像 Google 这样的大公司将信息获取成本从边际成本转变为固定成本,具体点说就是,Google 投入资金来抓取网络和索引信息,但对于我们每个搜寻信息的用户来说,投入的成本几乎可以忽略不计。机器开始成为我们的信息系统。这开启了互联网时代及其后续的移动互联网时代,改变了人们获取、传播和分享信息的方式,并对商业、教育、娱乐、社交等多个领域产生了深远的影响。
现在,我们正见证技术发展的新转折,思考、推理和模型构建的能力正从人类转移到机器上。OpenAI 和大模型将生产模型的成本从边际成本转变为固定成本。
大模型已经通过来自互联网的大量文本、图像和视频进行了训练,这其中包含了法律、医学、科学、艺术等各种领域的信息。这种广泛的训练使得这些大模型可以作为基础模型,用以更轻松地构建其他模型。
无论是认知模型(如何观察和表达)、行为模型(如何驾驶汽车),还是特定领域的模型(如何设计半导体芯片),这一转折点必将激发各类模型的广泛涌现。模型是知识的载体,这一转折点将使模型和知识变得无处不在,使我们加速进入新一轮的技术创新,迎来一个由自动驾驶汽车、自主移动机器人、人形机器人等多样的机器及其在各行各业和各种部署场景中应用的新时代。这些新范式将重新定义人机交互的方式。
多模态 LLM 与视觉的关键作用
通过 Transformer 模型及其自注意力机制,AI 可以真正实现多模态,这意味着 AI 系统可以像人们一样处理来自语音、图像和文本等多种模式的输入信息。
OpenAI 的 CLIP、DALL·E、Sora 和 GPT-4o 就是朝着多模态迈进的一些模型。例如,CLIP 用于理解图像与自然语言的配对数据,从而在视觉和文本信息之间架起桥梁;DALL·E 旨在根据文本描述生成图像,而 Sora 可以根据文本生成视频,有望在未来成为全球性的模拟器。OpenAI 则将 GPT-4o 的发展往前更进一步,OpenAI 综合利用文本、视觉和音频信息来端到端训练单个新模型 GPT-4o,无需进行多媒体与文本的相互转换。所有输入和输出都经同一神经网络处理,使得模型能够跨模态综合音频、视觉和文本信息进行实时推理。
多模态 AI 的未来将聚焦于边缘侧
得益于边缘侧硬件的进步(许多边缘硬件都是基于 Arm 平台开发设计的),同时也为了解决延迟问题、隐私和安全需求、带宽和成本考量,并确保在网络连接间断或无连接时能够离线使用,AI 创新者在不断突破模型的运行边界。Sam Altman 也曾坦言[1],对于视频(我们通过视觉感知到的内容),要想提供理想的用户体验,端侧模型至关重要。
然而,资源限制、模型大小和复杂性挑战阻碍了多模态 AI 向边缘侧的转移。要想解决这些问题,我们需综合利用硬件进步、模型优化技术和创新的软件解决方案,来促进多模态 AI 的普及。
近期的 AI 发展对计算机视觉产生了深远的影响,尤其令人关注。许多视觉领域研究人员和从业者正在使用大模型和 Transformer 来增强视觉能力。在大模型时代,视觉的重要性日益凸显。原因有以下几点:
机器系统必须通过视觉等感知能力来了解周围环境,为自动驾驶和机器人提供关乎人身安全的必要安全性和避障能力。空间智能是被誉为“AI 教母”的李飞飞等研究人员关注的热门领域。
视觉对于人机交互至关重要。AI 伴侣不仅需要高智商,还需要高情商。机器视觉可以捕捉人类的表情、手势和动作,从而更好地理解人类的意图和情感。
AI 模型需要视觉能力和其他传感器来收集实际数据并适应特定环境,随着 AI 从轻工业延伸到数字化水平较低的重工业,收集物理世界特征数据集,建立 3D 物理世界的仿真环境或数字孪生,并使用这些技术来训练多模态大模型,使模型可以理解真实的物理世界,这一点都尤为重要。
视觉 + 基础模型的示例
尽管 ChatGPT 因其出色的语言能力而广受欢迎,但随着主流的 LLM 逐渐演变成多模态,将它们称作“基础模型”也许更为贴切。包括视觉等多种模态在内的基础模型领域正在快速发展。以下是一些例子:
DINOv2
DINOv2 是由 Meta AI 开发的先进自监督学习模型,它基于原来的 DINO 模型打造,并已通过拥有 1.42 亿张图像的庞大数据集进行了训练,这有助于提高它在不同视觉领域的稳健性和通用性。DINOv2 无需专门训练就能分割对象。此外,它还能生成通用特征,适用于图像级视觉任务(如图像分类、视频理解)和像素级视觉任务(如深度估计、语义分割),表现出卓越的泛化能力和多功能性。
Segment Anything 模型 (SAM)
SAM 是一种可推广的分割系统,可以对不熟悉的对象和图像进行零样本泛化,而无需额外训练。它可以使用多种输入提示词来识别和分割图像中的对象,以明确要分割的目标。因此在遇到每个新对象或场景时,它无需进行特殊训练即可运行。据 Meta AI 介绍,SAM 可以在短短 50 毫秒内生成分割结果,因此非常适合实时应用。它具备多功能性,可应用于从医学成像到自动驾驶等诸多领域。
Stable Diffusion
文生图和文生视频是生成式 AI 的一个重要方面,因为它不仅能够助力产生新的创意,还有望构建一个世界模拟器,用来作为训练模拟、教育程序或视频游戏的基础。Stable Diffusion 是一个生成式 AI 模型,能够根据文本描述创建图像。该模型使用一种称为潜在扩散 (latent diffusion) 的技术,在潜在空间 (latent space) 的压缩格式中操作图像,而不是直接在像素空间中操作,从而实现高效运行。这种方法有助于减少计算负载,使模型能够更快地生成高质量图像。
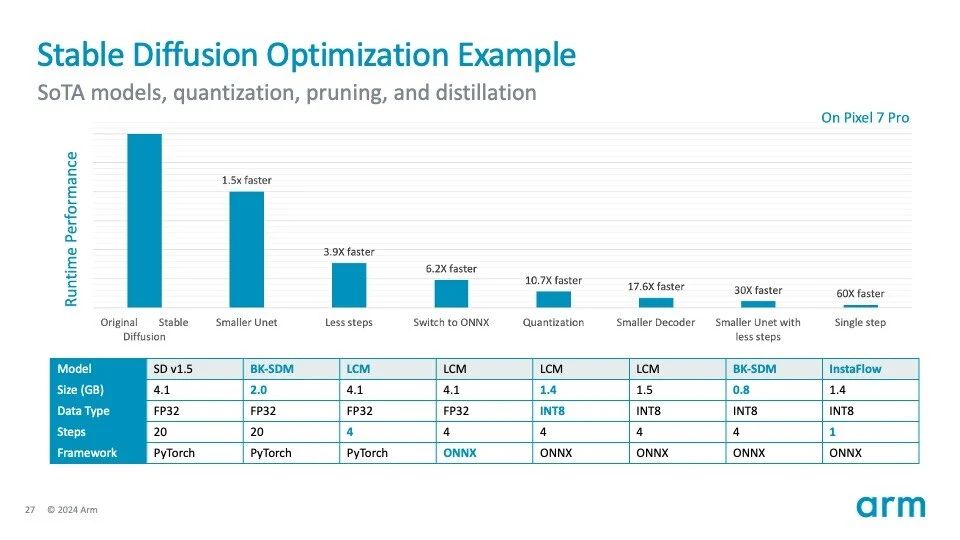
Stable Diffusion 已经可以在智能移动设备的边缘侧运行。上图是 Stable Diffusion 优化过程的示例:
如果采用 Stable Diffusion 的原始设置,将不适合在移动端 CPU 或 NPU 上运行(基于 512×512 图像分辨率)。
通过使用更小的 U-Net 架构、更少的采样步骤、切换到 ONNX 格式、应用量化技术(从 FP32 到 INT8)和其他技术,它仅在 CPU 上就实现了超过 60 倍的速度提升。其中许多优化技术和工具都是基于 Arm 广泛的生态系统所开发的。该模型仍有进一步优化的空间。
借助多模态 LLM 实现出色视觉体验
作为 Arm 的智能视觉合作伙伴计划的一员,爱芯元智 (Axera) 利用其旗舰芯片组 AX650N 在边缘侧部署了 DINOv2 视觉 Transformer。该芯片采用 Arm Cortex-A55 CPU 集群进行预处理和后处理,结合爱芯通元混合精度 NPU 和爱芯智眸 AI-ISP,其具有高性能、高精度、易于部署和出色能效等特点。
以下展示了在 AX650N 上运行 DINOv2 的效果:
通过使用多样化大型数据集进行预训练之后,视觉 Transformer 可以更好地泛化到新任务和未见过的任务,从而简化了再训练过程并缩短了调优时间。它们可以应用于图像分类之外的多种任务,例如对象检测和分割,而无需进行大量的架构更改。
迎接 AI 和人机界面的未来
得益于 AI 和 LLM 的不断发展,我们正处于技术和人类交互转型的交会点。视觉会在这一演进中起到关键作用,赋予了机器理解周围环境以及在物理世界中“生存”的能力,可确保安全并增强交互性。在硬件和软件快速发展的推动下,向边缘侧 AI 的转变有望实现高效的实时应用。
-
ARM
+关注
关注
134文章
9184浏览量
369726 -
智能视觉
+关注
关注
0文章
102浏览量
9269 -
大模型
+关注
关注
2文章
2652浏览量
3267
原文标题:大咖观点 | 在大模型时代推动智能视觉技术的发展
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论