 解析Arm Neoverse N2 PMU事件L2D_CACHE_WR
解析Arm Neoverse N2 PMU事件L2D_CACHE_WR
作者:安谋科技 (Arm China) 主任工程师 Ker Liu;安谋科技 (Arm China) 主任软件工程师 蔡亦波
有客户希望我们帮忙分析 Eigen gemm 基准测试的一些执行情况。具体来说是为什么 L1D_CACHE_WR 的值会低于 L2D_CACHE_WR,这种情况令人费解。

通常,我们期望写操作发生在 L1 数据缓存中。来自 L1 数据缓存的一些回写可能会引发 L2 缓存写操作。一般来说,L1 数据缓存写操作的数量应该高于 L2 缓存写操作的数量。对于一些常用的工作负载(例如 Redis 和 Nginx),如果我们对 PMU 进行监控,就会发现 L1 数据缓存写操作的数量会高于 L2 缓存写操作的 PMU 值。但对于某些工作负载而言,L1 数据缓存写操作的 PMU 值要低于 L2 缓存写操作的 PMU 值。
本文中,我们将分析 L2D_CACHE_WR 的计数,以及在何种情况下,L1D_CACHE_WR 的 PMU 值会低于 L2D_CACHE_WR。
验证平台
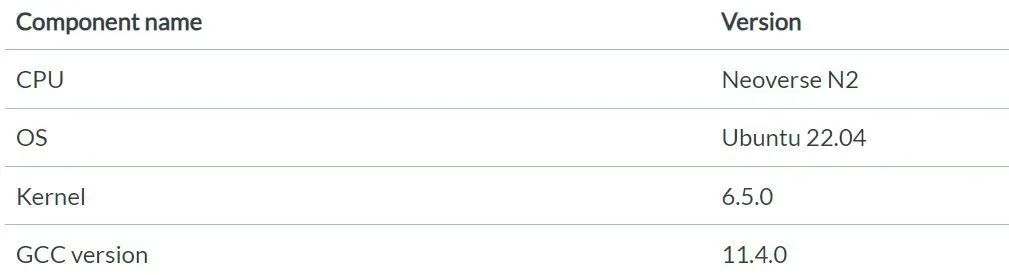
本文中的测试都是基于 Arm Neoverse N2 平台的服务器。下表显示了该服务器的硬件和软件版本信息。
调查
对于大多数工作负载而言,L1D_CACHE_WR 的 PMU 值要高于 L2D_CACHE_WR。例如,对于 Redis 来说,一个 Redis 进程在Core 1 上运行。使用 Memtier 客户端来生成读写混合请求。

以下是 Neoverse N2 PMU 指南[1]中 L1D_CACHE_WR 和 L2D_CACHE_WR 的定义。
L1D_CACHE_WR:此事件将统计在 L1 数据缓存中查找的任何内存写入操作。此事件还将统计由数据缓存按虚拟地址清零 (DC ZVA) 指令所引发的访问操作。
L2D_CACHE_WR:此事件将统计由 CPU 发出并在统一 L2 缓存中查找的任何内存写入操作。无论 L2 缓存是否命中,该事件都将计数。此事件还将统计从 L1 数据缓存分配到 L2 缓存的任何回写。此事件将 DC ZVA 操作视为存储指令并统计这些访问。来自 CPU 外部的监听不计算在内。
从 Neoverse N2 技术参考手册[2]中我们知道,L1 缓存和 L2 缓存之间具有严格的包含关系。存在于 L1 缓存中的任何缓存行也同样存在于 L2 缓存中。
经过分析研究,我们发现如下规律:
L2D_CACHE_WR 的 PMU 值约等于“L1 数据缓存重填”、“L1 指令缓存重填”和“L1 预取重填”的 PMU 值之和。
为什么我们要从这三个事件开始分析?
因为这三个事件都会引起 L1 数据缓存和 L1 指令缓存的替换行为,包括干净替换 (clean evictions) 和脏替换 (dirty evictions)。如果仔细看 L2D_CACHE_WR 的定义,您会发现它将统计从 L1 数据缓存分配到 L2 缓存的任何回写。L1 数据缓存回写则统计从 L1 数据缓存到 L2 缓存的任何脏数据回写,该值通常非常小,与 L2D_CACHE_WR 的值并不匹配,且没有专门针对干净替换的 PMU 计数器。因此,我们综合考虑了所有可能导致缓存替换的事件(包括干净替换和脏替换),从不同的角度进行分析,找到了这个规律。

我们已在几个典型场景中验证了这一发现。大多数测试用例确实遵循这种规律。
对于 Redis 的情况
我们使用 Memtier 客户端作为负载生成器,为 Redis 进程生成混合读写请求,结果发现 PMU 值遵循相应规律。

对于“Telemetry: ustress: l1d_cache_workload”[3]的情况
此基准测试仅读取数据,旨在对 L1 数据缓存的未命中情况进行压力测试,结果发现 PMU 值遵循相应规律。

对于“Telemetry: ustress: l1i_cache_workload”[4]的情况
此基准测试将重复调用那些与页面边界对齐的函数,旨在对 CPU L1 指令缓存的未命中情况进行压力测试,结果发现 PMU 值遵循相应规律。

对于 Eigen gemm 的情况
此基准测试包含许多读取操作。L1D_CACHE_WR 的 PMU 值比较小,但 L1 缓存的预取操作导致 L2D 的 PMU 值很大。因此,我们得到的结果是 L1D_CACHE_WR 的 PMU 值要低于 L2D_CACHE_WR。PMU 值也遵循这种规律。

但是,流写入是一个例外。我们使用“Telemetry: ustress: memcpy_workload”[5]基准测试,对加载-存储 (load-store) 管线中完全处于 L1D 缓存内的 memcpy 进行压力测试。memcpy 触发流写入,跳过 L1 并直接写入 L2。此时,PMU 值并不遵循这种规律。

以下是 Neoverse N2 技术参考手册中关于写入流模式的描述。
Neoverse N2 核心支持写入流模式(有时也称为读取分配模式),这一点同时适用于 L1 和 L2 缓存。
当发生读取未命中或写入未命中时,会向 L1 和 L2 缓存分配缓存行。但是,写入大块数据可能会导致不必要的数据浪费缓存空间。这也可能会浪费功率和性能,因为在执行行填充后,如果 memset() 随后写入了整行数据,行填充数据将被丢弃。有些情况下,不需要在写入时分配缓存行,例如在执行 C 标准库 memset() 函数以将一大块内存清除为某个已知值时。
为了防止不必要的缓存行分配,内存系统可以在行填充完成之前检测核心何时写入完整的缓存行。如果在可配置数量的连续行填充中检测到这种情况,系统就会切换到写入流模式。
在写入流模式下,读取操作会正常执行,仍可能引发行填充。写入操作还是会先查找缓存,但如果未命中,它们就会写入 L2 或系统,而不是开始行填充。
总结
在基于 Neoverse N2 的服务器上,L2D_CACHE_WR 会统计来自 L1 缓存的所有缓存替换(包括干净替换和脏替换)以及流写入。
对于读取大量数据的工作负载,我们会看到,L1D_CACHE_WR 的 PMU 值要低于 L2D_CACHE_WR。
-
ARM
+关注
关注
134文章
9188浏览量
369903 -
服务器
+关注
关注
12文章
9357浏览量
86240 -
数据缓存
+关注
关注
0文章
23浏览量
7186 -
PMU
+关注
关注
1文章
109浏览量
21746
原文标题:深入研究 Arm Neoverse N2 PMU 事件 L2D_CACHE_WR
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Arm Neoverse家族新增V1和N2两大平台,突破高性能计算瓶颈
ARM Neoverse N2 PMU指南
Arm Neoverse V1 PMU指南
Arm Neoverse N2汽车硬件技术概述
ARM Neoverse™N2软件优化指南
Arm Neoverse™ N1 PMU指南
Arm Neoverse™ N2核心加密扩展技术参考手册
ARM Neoverse™N1核心技术参考手册
ARM Neoverse™N2核心技术参考手册
互联网巨头纷纷启用Arm CPU架构,Arm最新Neoverse V1和N2平台加速云服务器芯片自研
Arm推出新一代平台 Neoverse V2 平台
Neoverse N2和CMN-700系统的PoC点在哪里?
Arm 更新 Neoverse 产品路线图,实现基于 Arm 平台的人工智能基础设施
Arm新Arm Neoverse计算子系统(CSS):Arm Neoverse CSS V3和Arm Neoverse CSS N3






 工商网监
工商网监
评论