 spark为什么比mapreduce快?
spark为什么比mapreduce快?
spark为什么比mapreduce快?
首先澄清几个误区:
1:两者都是基于内存计算的,任何计算框架都肯定是基于内存的,所以网上说的spark是基于内存计算所以快,显然是错误的
2;DAG计算模型减少的是磁盘I/O次数(相比于mapreduce计算模型而言),而不是shuffle次数,因为shuffle是根据数据重组的次数而定,所以shuffle次数不能减少
所以总结spark比mapreduce快的原因有以下几点:
1:DAG相比hadoop的mapreduce在大多数情况下可以减少磁盘I/O次数
因为mapreduce计算模型只能包含一个map和一个reduce,所以reduce完后必须进行落盘,而DAG可以连续shuffle的,也就是说一个DAG可以完成好几个
mapreduce,所以dag只需要在最后一个shuffle落盘,就比mapreduce少了,总shuffle次数越多,减少的落盘次数就越多
2:spark shuffle 的优化
mapreduce在shuffle时默认进行排序,spark在shuffle时则只有部分场景才需要排序(bypass技师不需要排序),排序是非常耗时的,这样就可以加快shuffle速度
3:spark支持将需要反复用到的数据进行缓存
所以对于下次再次使用此rdd时,不再再次计算,而是直接从缓存中获取,因此可以减少数据加载耗时,所以更适合需要迭代计算的机器学习算法
4:任务级别并行度上的不同
mapreduce采用多进程模型,而spark采用了多线程模型,多进程模型的好处是便于细粒度控制每个任务占用的资源,但每次任务的启动都会消耗一定的启动时间,即mapreduce的map task 和reduce task是进程级别的,都是jvm进程,每次启动都需要重新申请资源,消耗不必要的时间,而spark task是基于线程模型的,通过复用线程池中的线程来减少启动,关闭task所需要的开销(多线程模型也有缺点,由于同节点上所有任务运行在一个进行中,因此,会出现严重的资源争用,难以细粒度控制每个任务占用资源)
审核编辑 黄宇
-
内存
+关注
关注
8文章
3020浏览量
74011 -
SPARK
+关注
关注
1文章
105浏览量
19895 -
MapReduce
+关注
关注
0文章
45浏览量
6299
发布评论请先 登录
相关推荐
比克电池邱沫:超低内阻,比克大圆柱电池达成极致快充性能

供应智融SW6106支持PD的多协议双向快充IC
快充工作原理,解读什么是快充协议及协议芯片的应用

快恢复桥损坏如何判断

2024快应用智慧服务生态白皮书发布,探索AI与快应用融合之路

广汽能源与泰国Spark EV签订合作框架协议
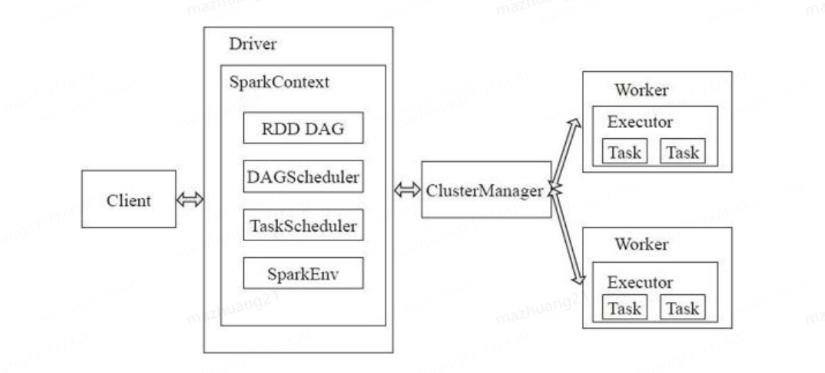
spark运行的基本流程
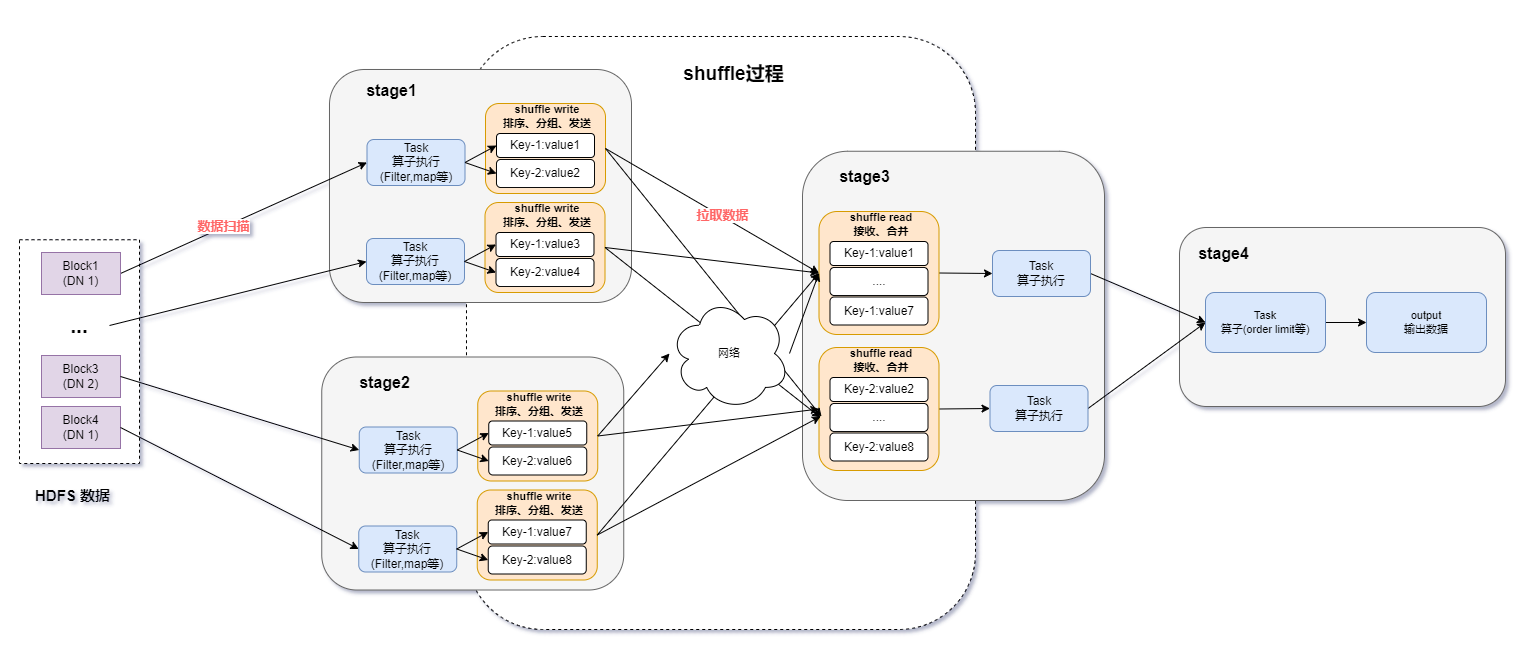
Spark基于DPU的Native引擎算子卸载方案

关于Spark的从0实现30s内实时监控指标计算
快充技术的演变与PW6606快充电压诱骗芯片的应用

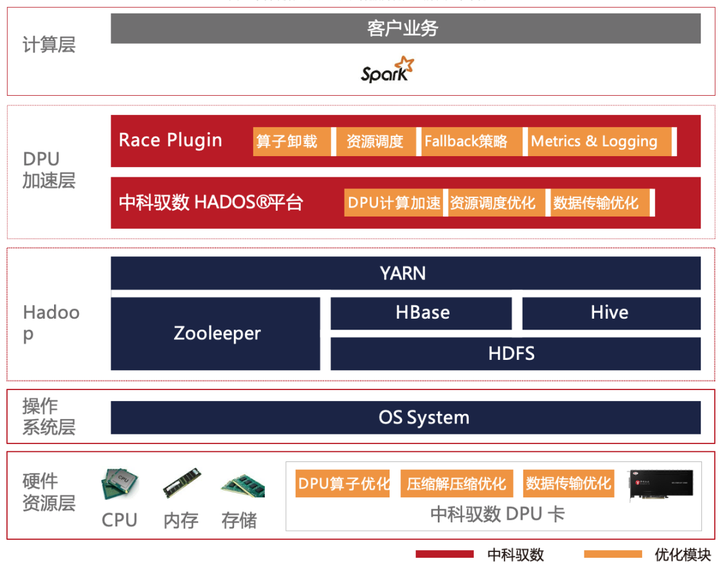
如何利用DPU加速Spark大数据处理? | 总结篇
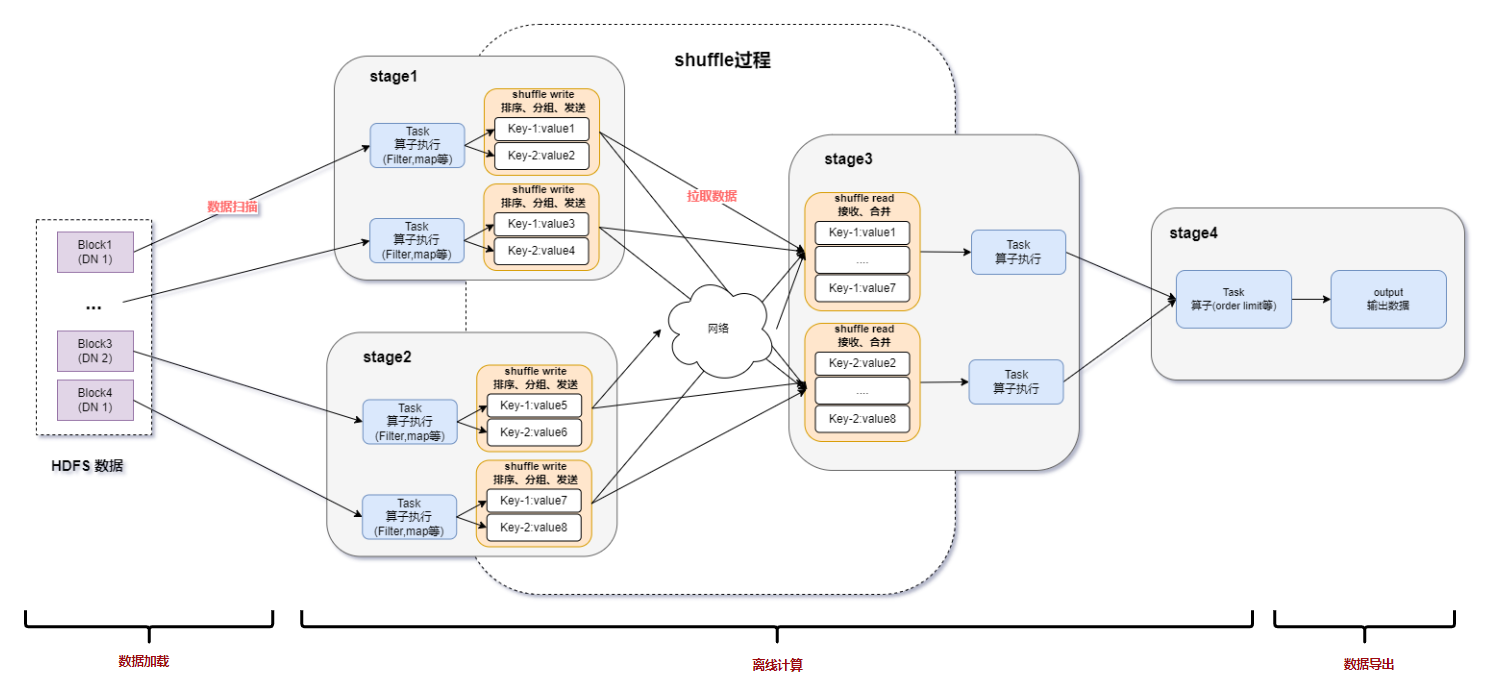
Spark基于DPU Snappy压缩算法的异构加速方案
RDMA技术在Apache Spark中的应用

基于DPU和HADOS-RACE加速Spark 3.x





 工商网监
工商网监
评论