 NVIDIA RTX AI套件简化AI驱动的应用开发
NVIDIA RTX AI套件简化AI驱动的应用开发
NVIDIA 于近日发布NVIDIA RTX AI套件,这一工具和 SDK 集合能够帮助 Windows 应用开发者定制、优化和部署适用于 Windows 应用的 AI 模型。该套件免费提供,不要求使用者具备 AI 框架和开发工具方面的经验,并且可以为本地和云端部署提供绝佳的 AI 性能。
生成式预训练转换器(GPT)模型的普及为 Windows 开发者创造了将 AI 功能集成到应用中的绝佳机会。但要实现这些功能仍面临着巨大的挑战。首先,您需要根据应用的特定需求来定制模型。其次,需要优化模型,使其在适应各种硬件的同时,仍然能够提供绝佳的性能。之后,需要一条同时适用于云端和本地 AI 的简便部署路径。
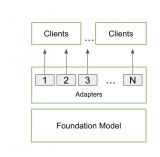
NVIDIA RTX AI 套件为 Windows 应用开发者提供了端到端工作流。您可以根据应用的特定要求,使用常用的微调技术对 Hugging Face 的预训练模型进行定制,并将它们量化到适合消费类 PC 的规模。然后,可以对它们进行优化,使其能够在整个NVIDIA GeForce RTX GPU系列以及云端 NVIDIA GPU 上发挥绝佳性能。
当需要部署时,无论您是选择将经过优化的模型与应用捆绑在一起,还是在应用安装/更新时下载模型,亦或是建立一个云微服务,RTX AI 套件都能提供多种途径来满足您的应用需求。该套件还包含NVIDIA AI 推理管理器(AIM)SDK,能够根据用户的系统配置或当前的工作负载让应用在本地或云端运行 AI。
适用于各种应用的强大定制 AI
当今的生成式模型在庞大的数据集上训练而成。整个训练过程可能需要数周时间,并使用数百颗全球最强大的 GPU。虽然这些计算资源对大多数开发者来说遥不可及,但开源预训练模型可以让您获得强大的 AI 功能。
开源预训练基础模型通常在通用数据集上训练而成,因此在各种任务中都能够提供不错的结果。但应用往往需要专门的行为,例如游戏角色需要以特定的方式说话、科学写作助手需要理解特定行业的术语等。
微调是一种可以根据应用需求,在额外的数据上对预训练模型进行进一步训练的技术,例如游戏角色的对话示例。
RTX AI 套件包含NVIDIA AI Workbench等支持微调的工具。今年早些时候发布的 AI Workbench 是一款用于在本地 RTX GPU 和云端中组织并运行模型训练、调优与优化项目的工具。RTX AI 套件还包含使用 QLoRA 进行微调的 AI Workbench 项目,QLoRA 是当今最常用、效果最好的技术之一。
为了实现参数高效微调,该套件使用 Hugging Face Transformer 库来充分发挥 QLoRA 的作用,在减少内存使用的同时实现了定制化,而且可以在搭载 RTX GPU 的客户端设备上高效运行。
微调完成后的下一步是优化。
针对 PC 和云端进行优化
AI 模型优化需要解决两大难题。首先,PC 用于运行 AI 模型的内存和计算资源有限。其次,PC 和云端之间存在各种具有不同功能的目标硬件。
RTX AI 套件包含以下用于优化 AI 模型并使其作好部署准备的工具。
NVIDIA TensorRT 模型优化器:即使较小的 LLM 也需要 14 GB 或以上的内存。适用于 Windows 的 NVIDIA TensorRT 模型优化器正式发布,它所提供的模型量化工具可在不显著降低准确性的情况下,将模型规模最多缩小至原来的三分之一。其中的 INT4 AWQ 后训练量化等方法便于在 RTX GPU 上运行最先进的 LLM。这样一来,较小的模型不仅可以更加容易地适应典型系统上可用的 GPU 内存,还能通过减少内存带宽瓶颈来提高性能。
NVIDIA TensorRT Cloud:为了在每个系统上都能获得绝佳的性能,可以针对每个 GPU 专门优化模型。当前推出的NVIDIA TensorRT Cloud开发者预览版是一项云服务,用于为 PC 中的 RTX GPU 以及云端中的 GPU 构建经过优化的模型引擎。它还为流行的生成式 AI 模型提供了预构建的减重引擎,这些引擎可与微调的权重合并成优化的引擎。与预训练模型相比,使用 TensorRT Cloud 构建并使用 TensorRT 运行时运行的引擎可以实现高达 4 倍的性能提升。
优化微调模型后的下一步是部署。
开发一次即可实现随处部署
如果您的应用能够在本地或云端执行推理,就能为大多数用户提供绝佳的体验。将模型部署在设备上可以实现更低的延迟,并且不需要在运行时调用云,但对硬件有一定的要求。将模型部署在云端则可以支持在任何硬件上运行的应用,但服务提供商需要承担持续的运营成本。在完成模型开发后,您就可以使用 RTX AI 套件将其部署到任意位置,且该套件中的工具既适用于设备端路径,也适用于云端路径,例如:
NVIDIA AI 推理管理器(AIM):当前推出的 AIM 抢先体验版为 PC 开发者简化了 AI 集成的复杂性,并且可以在 PC 端和云端无缝协调 AI 推理。NVIDIA AIM 利用必要的 AI 模型、引擎和依赖关系对 PC 环境进行预配置,并支持 GPU、NPU、CPU 等各种不同加速器的所有主要推理后端(TensorRT、ONNX Runtime、GGUF、Pytorch)。它还能执行运行时兼容性检查,以此确定 PC 是否能在本地运行模型,或者根据开发者策略切换到云端。
借助 NVIDIA AIM,开发者既可以利用NVIDIA NIM在云端进行部署,也可以利用 TensorRT 等工具在本地设备上进行部署。
NVIDIA NIM:NVIDIA NIM 是一套易于使用的微服务,能够加速云、数据中心和工作站中的生成式 AI 模型部署。NIM 属于NVIDIA AI Enterprise软件套装的一部分。RTX AI 套件提供的工具可将经过优化的模型与其依赖关系打包并上传至暂存服务器,然后启动 NIM。这一步将调入经过优化的模型,并创建一个端点供应用调用。
您还可以使用 NVIDIA AI 推理管理器(AIM)插件在设备上部署模型,有助于管理本地和云推理的细节,减轻开发者的集成负担。
NVIDIA TensorRT:NVIDIA TensorRT 10.0和TensorRT-LLM推理后端为配备张量核的 NVIDIA GPU 提供同类产品中的最佳性能。新发布的 TensorRT 10.0 简化了将 AI 模型部署到 Windows 应用中的流程。减重引擎可压缩 99% 以上的已编译引擎大小,因此可直接在终端用户设备上使用模型权重对其进行重新调整。此外,TensorRT 还为 AI 模型提供软硬件前向兼容性,使其能与较新的运行时或硬件配合使用。TensorRT-LLM 加入了在 RTX GPU 上加速生成式 AI LLM 和 SLM 的专门优化措施,可进一步加速 LLM 推理。
这些工具使开发者能够在应用运行时准备好模型。
RTX AI 加速生态系统
包括 Adobe、Blackmagic Design、Topaz Labs 等在内的顶尖创意独立软件开发商(ISV)正在将 NVIDIA RTX AI 套件集成到他们的应用中,以提供在 RTX PC 上运行的 AI 加速应用,从而提升数百万创作者的用户体验。
如果您想要在 RTX PC 上构建基于 RAG 和智能体的加速工作流,可以通过 LangChain 和 LlamaIndex 等开发者框架获得 RTX AI 套件的功能和组件(如 TensorRT-LLM)。此外,常用的生态系统工具(如 Automatic1111、Comfy.UI、Jan.AI、OobaBooga 和 Sanctum.AI)也可通过 RTX AI 套件实现加速。通过这些集成,您可以轻松构建经过优化的 AI 加速应用,将其部署到设备和云端 GPU 上,并在应用中实现能够在各种本地和云环境中运行推理的混合功能。
将强大的 AI
加入到 Windows 应用中
NVIDIA RTX AI 套件为 Windows 应用开发者提供了一套端到端工作流,使他们能够充分利用预训练模型,对这些模型进行定制和优化,并将它们部署到本地或云端运行。借助快速、强大的混合 AI,由 AI 驱动的应用既能够快速扩展,又能在各个系统上提供绝佳的性能。RTX AI 套件使您能够为更多用户带来更多由 AI 驱动的功能,让用户在游戏、生产、内容创建等所有活动中都能享受到 AI 所带来的好处。
-
NVIDIA
+关注
关注
14文章
5105浏览量
104456 -
WINDOWS
+关注
关注
4文章
3586浏览量
89921 -
AI
+关注
关注
87文章
32422浏览量
271587 -
应用开发
+关注
关注
0文章
60浏览量
9500
原文标题:借助适用于 Windows RTX PC 的 NVIDIA RTX AI 套件简化 AI 驱动的应用开发
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NVIDIA RTX 4500 Ada与NVIDIA RTX A5000的对比
NVIDIA推出面向RTX AI PC的AI基础模型
NVIDIA RTX AI Toolkit拥抱LoRA技术
使用全新NVIDIA AI Blueprint开发视觉AI智能体
Arm推出GitHub平台AI工具,简化开发者AI应用开发部署流程
RTX AI PC和工作站提供强大AI性能
揭秘NVIDIA AI Workbench 如何助力应用开发
HPE 携手 NVIDIA 推出 NVIDIA AI Computing by HPE,加速生成式 AI 变革
NVIDIA推出NVIDIA AI Computing by HPE加速生成式 AI 变革
NVIDIA推出用于支持在全新GeForce RTX AI笔记本电脑上运行的AI助手及数字人
NVIDIA宣布全面推出 NVIDIA ACE 生成式 AI 微服务
联发科发布天玑AI开发套件,赋能终端生成式AI应用
NVIDIA数字人技术加速部署生成式AI驱动的游戏角色






 工商网监
工商网监
评论