 单向链表中的存值与存址、数据与p_next分离问题
单向链表中的存值与存址、数据与p_next分离问题
周立功教授数年之心血之作《程序设计与数据结构》以及《面向AMetal框架与接口的编程(上)》,书本内容公开后,在电子行业掀起一片学习热潮。经周立功教授授权,本公众号特对《程序设计与数据结构》一书内容进行连载,愿共勉之。
第三章为算法与数据结构,本文为3.2 单向链表中的3.2.1 存值与存址和3.2.2 数据与p_next分离。
>>> 3.2.1存值与存址
1、存值
在结构体中,虽然不能用“当前结构体类型”作为结构体成员的类型,但可以用“指向当前结构体类型的指针”作为结构体成员的类型。比如:

其中,slist 是single list 的缩写,表明该结点是单向链表结点。由于AMetal平台规定字母大小写不能混用,且类型名、变量名、函数名等只能使用小写字母,宏定义只能使用大写字母,因此为了与AMetal平台保持一致,类型名中的字母全部使用小写。
由于p_next是指针类型而不是结构体,它所指向的是同一种类型的结构体变量。事实上,编译器在确定结构体的长度之前就已经知道了指针的长度,因此这种类型的自引用是合法的。p_next不仅是struct _slist_node类型中的一员,而且又指向struct _slist_node类型的数据,接着开始为这个结构体创建类型名slist_node_t。即:

AMetal规定使用typedef定义的新类型名必须以“_t”结尾,为了与AMetal保持一致,后续的类型名结尾为“_t”。但一定要警惕下面这样的声明陷阱:

在声明p_next指针时,typedef还没有结束,slist_node_t还不能使用,所以编译器报告错误信息。当然,也可以在定义结构体前先用typedef,即可在声明p_next指针时,使用类型定义slist_node_t。比如:

最后也可以结合上述2种方法按照以下形式进行定义:

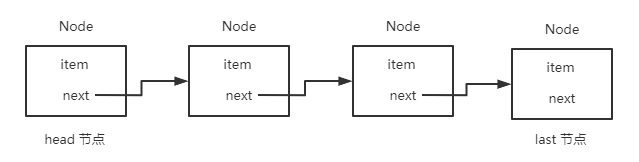
即定义了一个结构体类型,这种方法常用于链表(list)、树(tree)与许多其它的动态数据结构。p_next称为链(link),每个结构将通过p_next链接到后面的结构,详见图 3.1。其中,data用于存放结点中的数据,该数据是由调用者(应用程序)提供的,p_next用于存放指向链表中下一个结点的指针(地址)。其中的箭头表示链,p_next的值是下一个结点的地址,当p_next的值为NULL(0),表示链表已经结束。因此可以将链表想象为一系列连续的元素,元素与元素之间的链接关系只是为了确保所有的元素都可以被访问。如果错误地丢失了一个链接,则从这个位置开始往后的所有元素都无法访问。

图 3.1 链表示意图
通常需要定义一个指向链表头结点的指针p_head,便于从链表的头结点开始,顺序地访问链表中所有的结点。比如:
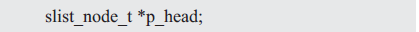
添加头结点p_head后,完整的链表示意图详见图3.2。

图3.2 添加指向链表头结点的指针
此时,只要获取p_head的值,即可依次遍历(访问)链表的所有结点。比如:

对于操作链表的函数,必须进行测试,以确保在操作空链表是也是正确的。如果直接使用p_head访问各个结点,当遍历结束后,则p_head的值为NULL,它不再指向第一个结点,从而丢失了整个链表,因此必须通过一个临时指针变量访问链表的各个结点。比如:
接下来,考虑将结点添加到链表的尾部。在初始状态下,链表是一个不包含任何结点的空表,此时p_head为NULL,那么新增的结点就是头结点,直接修改p_head的值,使其从NULL变为指向新结点的指针,链表的变化详见图3.3。
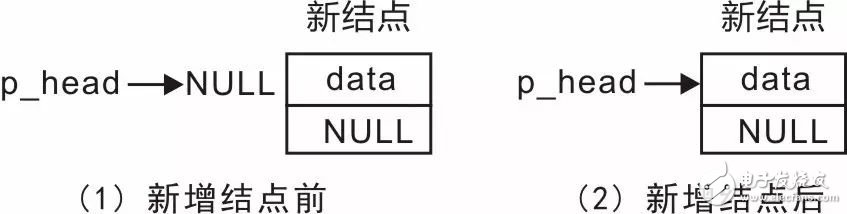
图3.3 链表为空时新增结点
由于新结点添加在链表的尾部,因此新结点中p_next的值为NULL,详见程序清单3.6。
程序清单3.6 新增结点范例程序(链表为空)

现在我们来编写一个简单的示例,验证结点是否添加成功,详见程序清单3.7。
程序清单3.7 添加结点范例程序(1)

如果结点加入成功,则可以通过printf将数据1打印出来。遗憾的是,运行该程序后,什么现象都没有看到。当链表为空时,添加一个结点的核心工作是“修改p_head的值,使其从NULL变为指向新结点的指针”。在调用slist_add_tail()后,p_head被修改了吗?
当将指针传递给函数时,其传递的是值。如果想要修改原指针,而不是指针的副本,则需要传递指针的指针。p_head是在主程序中定义的,其后仅仅是将NULL值作为实参传递给了slist_add_tail()的形参。此后p_head与slist_add_tail()再无任何关联,因此slist_add_tail()根本不可能修改p_head。要想在调用时修改p_head,则必须将该指针的地址传递给slist_add_tail(),详见程序清单3.8。
程序清单3.8 链表为空时新增结点的范例程序

如程序清单3.9所示的测试程序可以验证添加结点是否成功,首先初始化链表为空,接着传递p_head的地址,然后从头结点开始,依次访问各个结点。
程序清单3.9 添加结点范例程序(2)

当链表不为空时,假定已经存在一个值为data1的结点,再添加一个值为data2的结点,链表的变化详见图3.4。

图3.4 链表非空时新增结点
其实现的过程仅需要修改原链表尾结点p_next的值,使其从NULL指针变为指向新结点的指针,详见程序清单3.10。
程序清单3.10 新增结点范例程序

现在可以在程序清单3.9的基础上,添加更多的结点作为测试程序,详见程序清单3.11。
程序清单3.11 添加结点范例程序(3)

通过该程序可以验证结点添加成功,但仔细观察程序清单3.10可以发现,新增一个结点时,需要判定当前链表是否为空,然后再根据实际情况作出相应的处理。产生条件判断的原因是链表可能为空,没有一个有效结点。如果链表初始时就存在一个结点head:

由于这是一个实际的结点,不再是指向头结点的指针,因此链表不可能为空,链表示意图详见图 3.5。

图 3.5 链表示意图
对于这种类型的链表,始终存在一个无需有效数据的头结点,对于空链表,其至少包含该头结点,空链表示意图详见图3.6。由于在初始化时不包含其它任何结点,因此p_next的值为NULL。
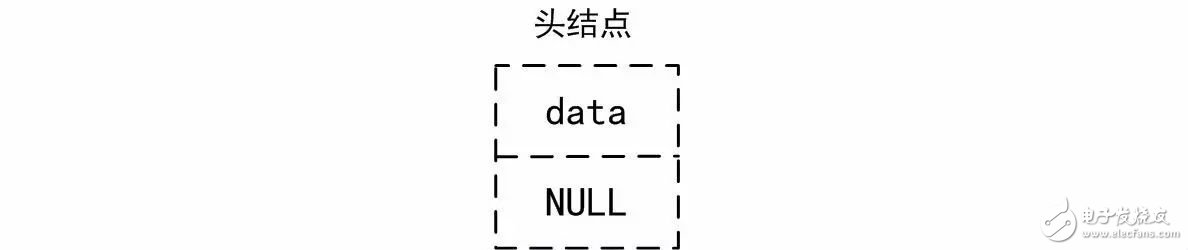
图3.6 空链表示意图
当需要添加一个新的结点时,则从头结点开始寻找尾结点。当找到尾结点时,则修改尾结点的p_next值,使其从NULL指针变为指向新结点的指针,详见程序清单3.12。
程序清单3.12 新增结点范例程序

注意,这里的p_head始终指向存在的头结点,与程序清单3.6中的p_head意义不同,可以使用如程序清单3.13所示的测试程序对其进行测试,由于初始化时无后继结点,因此p_next域的值为NULL。
程序清单3.13 添加结点范例程序(4)

虽然如程序清单3.12所示的程序不再使用判断语句,但又带来了新的问题,头结点的data被闲置,仅使用了p_next,则势必浪费内存。当然,对于当前示例来讲data是int类型数据,仅占用4个字节,浪费4个字节或许还能接受,如果data是其它类型呢?
如果链表的元素是学生记录中的数据,由于学生记录中的数据分别为不同类型的数据,因此结构体是最好的选择。而作为范例程序无法面面俱到,所以仅以几个典型的数据为例作为结构体的成员。基于此,专门为学生记录中的数据定义一个结构体类型与新的结构体类型名。其数据类型定义如下:
即可用此结构体存储学生记录中的数据,其成员在内存中的存储关系详见图 3.7。如果将element_type_t声明与student_t相同的类型,则链表数据结构为:

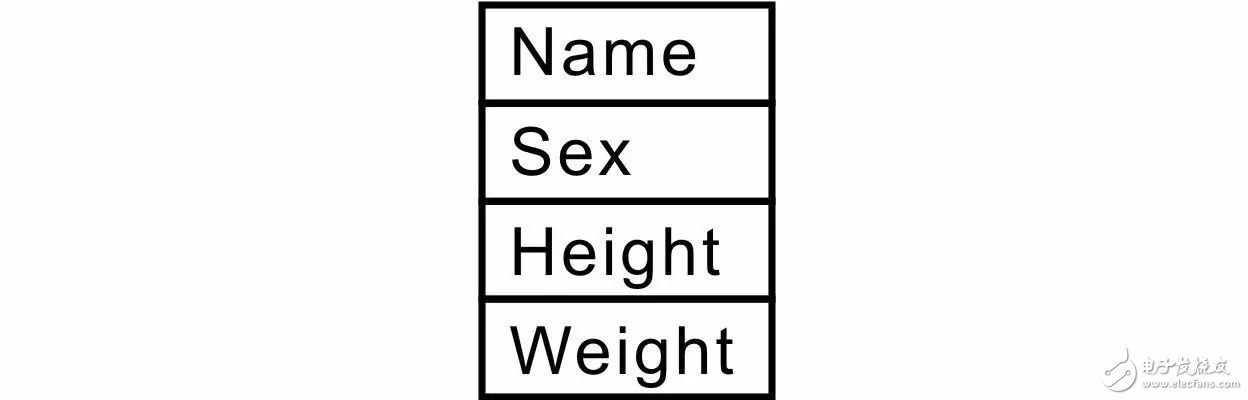
图 3.7
即与应用程序相关的数据data的类型为另一个结构体类型student_t。
此时只要定义一个slist_node_t类型的变量node,即可引用结构体的成员:

那么该链表各成员在内存中的存储关系就确定下来了,详见图 3.8。如果使用表达式

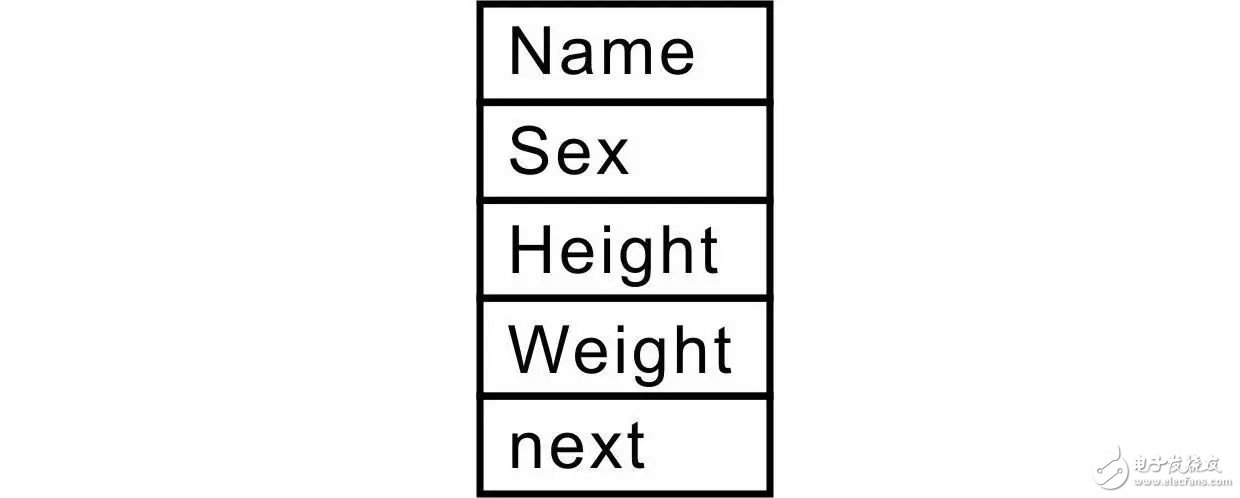
图 3.8
即可通过node变量引用slist_node_t结构体的成员data。此时,只要将node.data看作一个student_t类型变量,即可使用表达式

引用student_t结构体成员data的成员name(学生记录中的数据)。
当链表中的数据从int类型变为student_t时,浪费的空间将是student_t类型的大小。这里仅仅是一个示例,学生记录可能包含更多其它的信息,比如,学号、年级、血型、宿舍号等,则头结点浪费的空间将会更大。
同时,这里也隐含了一个问题,数据类型的改变将导致程序行为的改变,使得该程序无法做到通用,必须在编译前确定好数据类型,则程序不能以通用库的形式发布。如果要使代码通用,就要使用能接受任意数据类型的void *。
2、存址
为了通用还是在链表中存放void *类型的元素,即可用链表存储用户传入的任意指针类型数据,则链表结点的数据结构定义如下:

其中,结点的数据域类型为void *类型指针,data指向用户数据,结点中的数据是由调用者(应用程序)提供的用户数据。
虽然void *看起来是一个指针,其本质上则是一个整数,因为在大多数编译器中指针与int占用的存储空间大小一样,所以通用链表是一个结点数据域类型为int型的链表,只不过结点的数据域中存储的是与应用程序关联的用户数据的地址。
假设存储在struct _student结构体学生记录中的数据就是用户数据,那么只要将存储学生记录的结构体变量的地址传递给链表结点的数据域就行了,即p->data指向用户数据的结构体存储空间,详见图 3.9。如果void *指针指向的不是结构体或者字符串,而是int型之类的简单类型,那么只要在使用时进行强制类型转换即可。
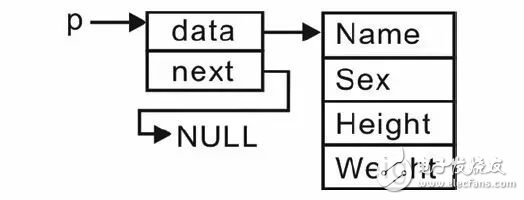
图 3.9 data指向用户数据
如果为了使链表数据与学生记录结构体关联,则必须先定义一个学生记录,然后将链表结点中的void *指针指向该学生记录。与之前直接将学生结构体作为链表结点的数据成员的链表相比,每个结点都会多耗费一个void *指针的空间。虽然一个结点耗费的空间并不多,但如果结点很多,其浪费的内存还是相当可观的,特别是在一些内存资源本身就很紧张的嵌入式系统中。
显然,要想节省内存空间,则不能定义void *类型指针,必须将数据(比如,学生记录)和链表结点的p_next放在一起,但这样做则无法做到重用链表程序。
分析当前链表结点的定义,其主要包含两个部分:链表关心的p_next指针和用户关心的data数据。回顾如程序清单3.12所示的slist_add_tail()函数,没有出现任何访问data的代码,从而说明data与链表无关。既然如此,是否可以将它们分离呢?
>>> 3.2.2 数据与p_next分离
由于链表只关心p_next指针,因此完全没有必要在链表结点中定义数据域,那么只保留p_next指针就好了。链表结点的数据结构(slist.h)定义如下:

由于结点中没有任何数据,因此节省了内存空间,其示意图详见图3.10。

图3.10 链表示意图
当用户需要使用链表管理数据时,仅需关联数据和链表结点,最简单的方式是将数据和链表结点打包在一起。以int类型数据为例,首先将链表结点作为它的一个成员,再添加与用户相关的int类型数据,该结构体定义如下:

由此可见,无论是什么数据,链表结点只是用户数据记录的一个成员。当调用链表接口时,仅需将node的地址作为链表接口参数即可。在定义链表结点的数据结构时,由于仅删除了data成员,因此还是可以直接使用原来的slist_add_tail()函数,管理int型数据的范例程序详见程序清单3.14。
程序清单3.14 管理int型数据的范例程序

由于用户需要初始化head为NULL,且遍历时需要操作各个结点的p_next指针。而将数据和p_next分离的目的就是使各自的功能职责分离,链表只需要关心p_next的处理,用户只关心数据的处理。因此,对于用户来说,链表结点的定义就是一个“黑盒子”,只能通过链表提供的接口访问链表,不应该访问链表结点的具体成员。
为了完成头结点的初始赋值,应该提供一个初始化函数,其本质上就是将头结点中的p_next成员设置为NULL。链表初始化函数原型为:

由于头结点的类型与其它普通结点的类型一样,因此很容易让用户误以为,这是初始化所有结点的函数。实际上,头结点与普通结点的含义是不一样的,由于只要获取头结点就可以遍历整个链表,因此头结点往往是被链表的拥有者持有,而普通结点仅仅代表单一的一个结点。为了避免用户将头结点和其它结点混淆,需要再定义一个头结点类型(slist.h):

基于此,将链表初始化函数原型(slist.h)修改为:

其中,p_head指向待初始化的链表头结点,slist_init()函数的实现详见程序清单3.15。
程序清单3.15 链表初始化函数

在向链表添加结点前,需要初始化头结点。即:

由于重新定义了头结点的类型,因此添加结点的函数原型也应该进行相应的修改。即:

其中,p_head指向链表头结点,p_node为新增的结点,slist_add_tail()函数的实现详见程序清单3.16。
程序清单3.16 新增结点范例程序

同理,当前链表的遍历采用的还是直接访问结点成员的方式,其核心代码如下:
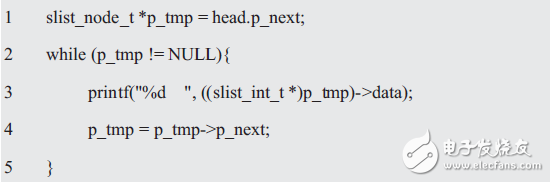
这里主要对链表作了三个操作:(1)得到第一个用户结点;(2)得到当前结点的下一个结点;(3)判断链表是否结束,与结束标记(NULL)比较。
基于此,将分别提供三个对应的接口来实现这些功能,避免用户直接访问结点成员。它们的函数原型为(slist.h):

其实现代码详见程序清单3.17。
程序清单3.17 遍历相关函数实现

程序中获取的第一个用户结点,其实质上就是头结点的下一个结点,因此可以直接调用slist_next_get()实现。尽管slist_next_get()在实现时并没有用到参数p_head,但还是将p_head参数传进来了,因为实现其它的功能时将会用到p_head参数,比如,判断p_pos是否在链表中。当有了这些接口函数后,即可完成遍历,详见程序清单3.18。
程序清单3.18 使用各个接口函数实现遍历的范例程序

由此可见,slist_begin_get()和slist_end_get()的返回值决定了当前有效结点的范围,其范围为一个半开半闭的空间,即:[begin,end),包括begin,但是不包括end。当begin与end相等时,表明当前链表为空,没有一个有效结点。
在程序清单3.18所示的遍历程序中,只有printf()语句才是用户实际关心的语句,其它语句都是固定的模式,为此可以封装一个通用的遍历函数,便于用户顺序处理与各个链表结点相关联的数据。显然,只有使用链表的用户才知道数据的具体含义,对数据的实际处理应该交由用户完成,比如,程序清单3.18中的打印语句,因此访问数据的行为应该由用户定义,定义一个回调函数,通过参数传递给遍历函数,每遍历到一个结点时,都调用该回调函数处理对数据进行处理。遍历链表的函数原型(slist.h)为:

其中,p_head指向链表头结点,pfn_node_process为结点处理回调函数。每遍历到一个结点时,都会调用pfn_node_process指向的函数,便于用户根据需要自行处理结点数据。当调用该回调函数时,会自动将用户参数p_arg作为回调函数的第1个参数,将指向当前遍历到的结点的指针作为回调函数的第2个参数。
当遍历到某个结点时,用户可能希望终止遍历,此时只要在回调函数中返回负值即可。一般地,若要继续遍历,函数执行结束后返回0。slist_foreach()函数的实现详见程序清单3.19。
程序清单3.19 遍历链表范例程序

现在可以使用这些接口函数,迭代如程序清单3.14所示的功能,详见程序清单3.20。
程序清单3.20 管理int型数据的范例程序
-
数据结构
+关注
关注
3文章
573浏览量
40149 -
程序设计
+关注
关注
3文章
261浏览量
30404 -
周立功
+关注
关注
38文章
130浏览量
37664 -
链表
+关注
关注
0文章
80浏览量
10572
原文标题:周立功:轻松掌握单向链表中的存值与存址、数据与p_next分离
文章出处:【微信号:ZLG_zhiyuan,微信公众号:ZLG致远电子】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
FPGA的设计中为什么避免使用锁存器
C语言单向链表
C语言学习笔记一:单向链表动态数据结构
请问FPGA用什么存数据?
锁存器的缺点和优点
数据 采-存-传系统(FPGA)

Hadoop大数据存算分离方案:计算层无缝对接存储系统
Apache Doris巨大飞跃:存算分离新架构介绍
LinkedBlockingQueue基于单向链表的实现





 工商网监
工商网监
评论