 链表结点的数据结构该如何定义
链表结点的数据结构该如何定义
近日周立功教授公开了数年的心血之作《程序设计与数据结构》,电子版已无偿性分享到电子工程师与高校群体下载,经周立功教授授权,特对本书内容进行连载。
>>>1.1.1 数据与p_next分离
由于链表只关心p_next指针,因此完全没有必要在链表结点中定义数据域,那么只保留p_next指针就好了。链表结点的数据结构(slist.h)定义如下:
1 typedef struct _slist_node{
2 struct _slist_node *p_next; //指向下一个结点的指针
3 }slist_node_t;
由于结点中没有任何数据,因此节省了内存空间,其示意图详见图3.10。

图3.10 链表示意图
当用户需要使用链表管理数据时,仅需关联数据和链表结点,最简单的方式是将数据和链表结点打包在一起。以int类型数据为例,首先将链表结点作为它的一个成员,再添加与用户相关的int类型数据,该结构体定义如下:
1 typedef struct _slist_int{
2 slist_node_t node; //包含链表结点
3 int data; // int类型数据
4 }slist_int_t;
由此可见,无论是什么数据,链表结点只是用户数据记录的一个成员。当调用链表接口时,仅需将node的地址作为链表接口参数即可。在定义链表结点的数据结构时,由于仅删除了data成员,因此还是可以直接使用原来的slist_add_tail()函数,管理int型数据的范例程序详见程序清单3.14。
程序清单3.14管理int型数据的范例程序
1 #include
2 typedef struct _slist_int{
3 slist_node_t node;
4 int data;
5 }slist_int_t;
6
7 int main (void)
8 {
9 slist_node_t head = {NULL};
10 slist_int_t node1, node2, node3;
11 slist_node_t *p_tmp;
12
13 node1.data = 1;
14 slist_add_tail(&head, &node1.node);
15 node2.data = 2;
16 slist_add_tail(&head, &node2.node);
17 node3.data = 3;
18 slist_add_tail(&head, &node3.node);
19 p_tmp = head.p_next;
20 while (p_tmp != NULL){
21 printf("%d ", ((slist_int_t *)p_tmp)->data);
22 p_tmp = p_tmp->p_next;
23 }
24 return 0;
25 }
由于用户需要初始化head为NULL,且遍历时需要操作各个结点的p_next指针。而将数据和p_next分离的目的就是使各自的功能职责分离,链表只需要关心p_next的处理,用户只关心数据的处理。因此,对于用户来说,链表结点的定义就是一个“黑盒子”,只能通过链表提供的接口访问链表,不应该访问链表结点的具体成员。
为了完成头结点的初始赋值,应该提供一个初始化函数,其本质上就是将头结点中的p_next成员设置为NULL。链表初始化函数原型为:
int slist_init (slist_node_t *p_head);
由于头结点的类型与其它普通结点的类型一样,因此很容易让用户误以为,这是初始化所有结点的函数。实际上,头结点与普通结点的含义是不一样的,由于只要获取头结点就可以遍历整个链表,因此头结点往往是被链表的拥有者持有,而普通结点仅仅代表单一的一个结点。为了避免用户将头结点和其它结点混淆,需要再定义一个头结点类型(slist.h):
typedef slist_node_t slist_head_t;
基于此,将链表初始化函数原型(slist.h)修改为:
int slist_init (slist_head_t *p_head);
其中,p_head指向待初始化的链表头结点,slist_init()函数的实现详见程序清单3.15。
程序清单3.15链表初始化函数
1 int slist_init (slist_head_t *p_head)
2 {
3 if (p_head == NULL){
4 return -1;
5 }
6 p_head -> p_next = NULL;
7 return 0;
8 }
在向链表添加结点前,需要初始化头结点。即:
slist_node_t head;
slist_init(&head);
由于重新定义了头结点的类型,因此添加结点的函数原型也应该进行相应的修改。即:
int slist_add_tail (slist_head_t *p_head, slist_node_t *p_node);
其中,p_head指向链表头结点,p_node为新增的结点,slist_add_tail()函数的实现详见程序清单3.16。
程序清单3.16新增结点范例程序
1 int slist_add_tail (slist_head_t *p_head, slist_node_t *p_node)
2 {
3 slist_node_t *p_tmp;
4
5 if ((p_head == NULL) || (p_node == NULL)){
6 return -1;
7 }
8 p_tmp = p_head;
9 while (p_tmp -> p_next != NULL){
10 p_tmp = p_tmp -> p_next;
11 }
12 p_tmp -> p_next = p_node;
13 p_node -> p_next = NULL;
14 return 0;
15 }
同理,当前链表的遍历采用的还是直接访问结点成员的方式,其核心代码如下:
1 slist_node_t *p_tmp = head.p_next;
2 while (p_tmp != NULL){
3 printf("%d ", ((slist_int_t *)p_tmp)->data);
4 p_tmp = p_tmp->p_next;
5 }
这里主要对链表作了三个操作:(1)得到第一个用户结点;(2)得到当前结点的下一个结点;(3)判断链表是否结束,与结束标记(NULL)比较。
基于此,将分别提供三个对应的接口来实现这些功能,避免用户直接访问结点成员。它们的函数原型为(slist.h):
slist_node_t *slist_begin_get (slist_head_t *p_head); //获取开始位置,第一个用户结点
slist_node_t *slist_next_get (slist_head_t *p_head, slist_node_t *p_pos);//获取某一结点的后一结点
slist_node_t *slist_end_get (slist_head_t *p_head); //结束位置,尾结点下一个结点的位置
其实现代码详见程序清单3.17。
程序清单3.17遍历相关函数实现
1 slist_node_t *slist_next_get (slist_head_t *p_head, slist_node_t *p_pos)
2 {
3 if (p_pos) { //找到p_pos指向的结点
4 return p_pos->p_next;
5 }
6 return NULL;
7 }
8
9 slist_node_t *slist_begin_get (slist_head_t *p_head)
10 {
11 return slist_next_get(p_head, p_head);
12 }
13
14 slist_node_t *slist_end_get (slist_head_t *p_head)
15 {
16 return NULL;
17 }
程序中获取的第一个用户结点,其实质上就是头结点的下一个结点,因此可以直接调用slist_next_get()实现。尽管slist_next_get()在实现时并没有用到参数p_head,但还是将p_head参数传进来了,因为实现其它的功能时将会用到p_head参数,比如,判断p_pos是否在链表中。当有了这些接口函数后,即可完成遍历,详见程序清单3.18。
程序清单3.18使用各个接口函数实现遍历的范例程序
1 slist_node_t *p_tmp = slist_begin_get(&head);
2 slist_node_t *p_end = slist_end_get(&head);
3 while (p_tmp != p_end){
4 printf("%d ", ((slist_int_t *)p_tmp)->data);
5 p_tmp = slist_next_get(&head, p_tmp);
6 }
由此可见,slist_begin_get()和slist_end_get()的返回值决定了当前有效结点的范围,其范围为一个半开半闭的空间,即:[begin,end),包括begin,但是不包括end。当begin与end相等时,表明当前链表为空,没有一个有效结点。
在程序清单3.18所示的遍历程序中,只有printf()语句才是用户实际关心的语句,其它语句都是固定的模式,为此可以封装一个通用的遍历函数,便于用户顺序处理与各个链表结点相关联的数据。显然,只有使用链表的用户才知道数据的具体含义,对数据的实际处理应该交由用户完成,比如,程序清单3.18中的打印语句,因此访问数据的行为应该由用户定义,定义一个回调函数,通过参数传递给遍历函数,每遍历到一个结点时,都调用该回调函数处理对数据进行处理。遍历链表的函数原型(slist.h)为:
typedef int (*slist_node_process_t) (void *p_arg, slist_node_t *p_node);
int slist_foreach(slist_head_t *p_head,
slist_node_process_t pfn_node_process,
void *p_arg);
其中,p_head指向链表头结点,pfn_node_process为结点处理回调函数。每遍历到一个结点时,都会调用pfn_node_process指向的函数,便于用户根据需要自行处理结点数据。当调用该回调函数时,会自动将用户参数p_arg作为回调函数的第1个参数,将指向当前遍历到的结点的指针作为回调函数的第2个参数。
当遍历到某个结点时,用户可能希望终止遍历,此时只要在回调函数中返回负值即可。一般地,若要继续遍历,函数执行结束后返回0。slist_foreach()函数的实现详见程序清单3.19。
程序清单3.19遍历链表范例程序
1 int slist_foreach( slist_head_t *p_head,
2 slist_node_process_t pfn_node_process,
3 void *p_arg);
4
5 {
6 slist_node_t *p_tmp, *p_end;
7 int ret;
8
9 if ((p_head == NULL) || (pfn_node_process == NULL)){
10 return -1;
11 }
12 p_tmp = slist_begin_get(p_head);
13 p_end = slist_end_get(p_head);
14 while (p_tmp != p_end){
15 ret = pfn_node_process(p_arg, p_tmp);
16 if (ret < 0) return ret; // 不再继续遍历
17 p_tmp = slist_next_get(p_head, p_tmp); //继续下一个结点
18 }
19 return 0;
20 }
现在可以使用这些接口函数,迭代如程序清单3.14所示的功能,详见程序清单3.20。
程序清单3.20管理int型数据的范例程序
1 #include
2 #include "slist.h"
3
4 typedef struct _slist_int {
5 slist_node_t node; //包含链表结点
6 int data; // int类型数据
7 }slist_int_t;
8
9 int list_node_process (void *p_arg, slist_node_t *p_node)
10 {
11 printf("%d ", ((slist_int_t *)p_node)->data);
12 return 0;
13 }
14
15 int main(void)
16 {
17 slist_head_t head; //定义链表头结点
18 slist_int_t nodel, node2, node3;
19 slist_init(&head);
20
21 node1.data = 1;
22 slist_add_tail(&head, &(node1.node));
23 node2.data = 2;
24 slist_add_tail(&head, &(node2.node));
25 node3.data = 3;
26 slist_add_tail(&head, &(node3.node));
27 slist_foreach(&head, list_node_process, NULL); //遍历链表,用户参数为NULL
28 return 0;
29 }-
电子工程师
+关注
关注
252文章
768浏览量
95623 -
数据结构
+关注
关注
3文章
573浏览量
40127 -
周立功
+关注
关注
38文章
130浏览量
37622 -
链表
+关注
关注
0文章
80浏览量
10558
原文标题:周立功:数据与p_next分离
文章出处:【微信号:Zlgmcu7890,微信公众号:周立功单片机】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
数据结构中最简单的链表


Linux Kernel数据结构:链表
数据结构之链式栈介绍
在RT-Thread中普通链表和侵入式链表有何区别
RT-Thread中侵入式链表的应用有哪些呢

链表的基础知识

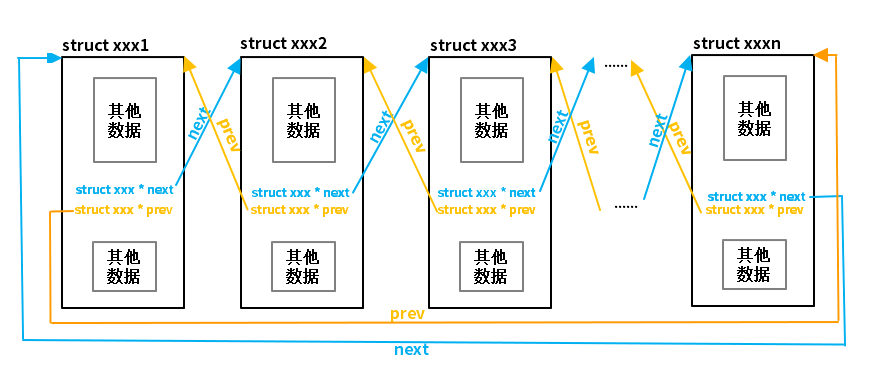
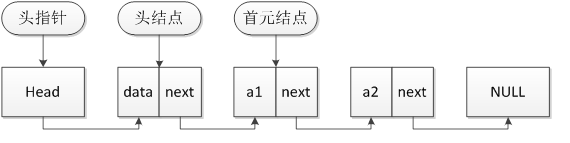
链表数据结构基本概念





 工商网监
工商网监
评论